用机器学习构建模型,进行信用卡反欺诈预测
2017-11-07 00:00
706 查看
本文通过利用信用卡的历史交易数据进行机器学习,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。
1. 数据的下载和数据介绍
数据的下载地址为
https://www.kaggle.com/dalpozz/creditcardfraud/data
数据集是2013年9月使用信用卡进行交易的数据。此数据集显示两天内发生的交易,其中284,807笔交易中有492笔被盗刷。数据集非常不平衡,被盗刷占所有交易的0.172%。不幸的是,由于保密问题,我们无法提供原始数据。特征V1,V2,... V28是使用PCA获得的主要组件。特征Class是响应变量,如果发生被盗刷,则取值1,否则为0。
数据包含了Time,V1,V2,..V28,Amount,Class一共31列,其中Class是标签列,其中0代表没有被盗刷,1表示被盗刷。
2. 分析工具介绍
我们使用的工具是FEA-spk技术,它的底层基于最流行的大数据开发框架spark,对各种算子的操作都是基于DataFrame的,使用FEA-spk来做交互分析,不但非常简单易懂而且几乎和spark的功能一样强大,更重要的一点,它可以实现可视化,处理的数据规模更大,可以进行分布式的机器学习等
3. 案例的具体实现步骤如下
1. 数据预处理(Pre-processing Data)
(1) 加载数据
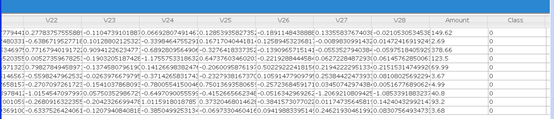
查看一下数据的大小

可以看到一共有28万多条
(2) 缺失值的处理,缺失值的占比情况


可以看到没有缺失值
2. 特征工程(Feature Engineering)
统计目标列的情况,这里涉及到样本的不平衡问题



可以看到数据严重的不均衡,样本不平衡影响分类器的学习,下面进行欠采样。


可以看到数据比较平衡了。
3. 特征选择
(1)由于Spark机器学习只支持double类型的数据,所以我们将数据转化为double类型的。


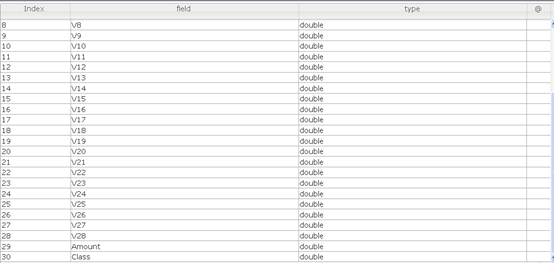
(2) 将特征聚合为向量

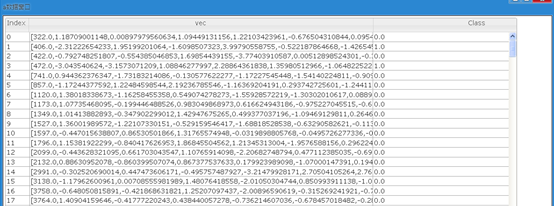
(3) 我们可以看到Time和Amount对应的向量的规格和其他特征相差较大,因此我们需对其进行归一化处理。

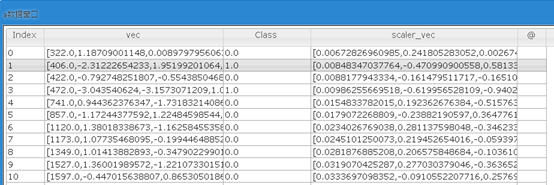
(4)我们看到特征向量一共有30个特征,特征的个数太多了,下面我们对特征进行卡方特征选择,选取10个最有预测能力的特征。

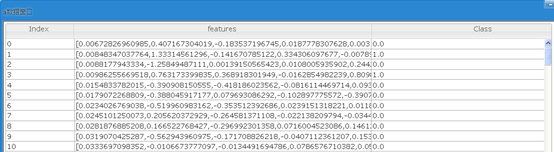
可以看到特征向量的维度变为10维了。
4.将数据划分为训练集和测试集

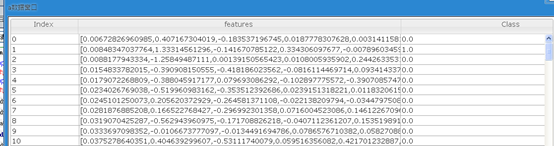
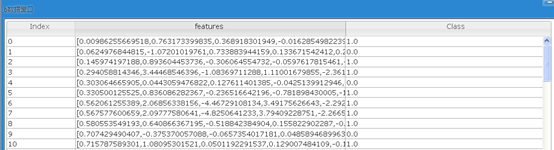
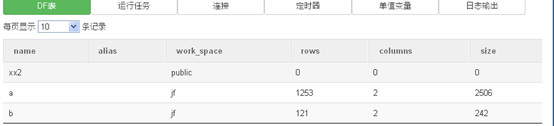
可以看到,a表和b表的比例大约为10:1。
5. 模型设定与预测
(1)对训练集df6表构造逻辑回归模型

(2)此刻的模型已经建立好了,下面我们用测试集进行预测

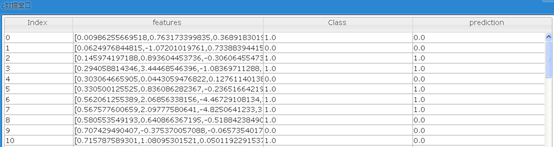
其中prediction列就是测试集的预测结果。
(3)对模型进行打分,评价模型的好坏


可以看到,模型的准确率达到了91%以上。
(4) 将模型保存到hdfs上面,以便下次使用

(5) 加载模型

以上就是信用卡反欺诈模型的构建过程,关注openfea,会有更多精彩的内容推荐。
1. 数据的下载和数据介绍
数据的下载地址为
https://www.kaggle.com/dalpozz/creditcardfraud/data
数据集是2013年9月使用信用卡进行交易的数据。此数据集显示两天内发生的交易,其中284,807笔交易中有492笔被盗刷。数据集非常不平衡,被盗刷占所有交易的0.172%。不幸的是,由于保密问题,我们无法提供原始数据。特征V1,V2,... V28是使用PCA获得的主要组件。特征Class是响应变量,如果发生被盗刷,则取值1,否则为0。
数据包含了Time,V1,V2,..V28,Amount,Class一共31列,其中Class是标签列,其中0代表没有被盗刷,1表示被盗刷。
2. 分析工具介绍
我们使用的工具是FEA-spk技术,它的底层基于最流行的大数据开发框架spark,对各种算子的操作都是基于DataFrame的,使用FEA-spk来做交互分析,不但非常简单易懂而且几乎和spark的功能一样强大,更重要的一点,它可以实现可视化,处理的数据规模更大,可以进行分布式的机器学习等
3. 案例的具体实现步骤如下
1. 数据预处理(Pre-processing Data)
(1) 加载数据
查看一下数据的大小
可以看到一共有28万多条
(2) 缺失值的处理,缺失值的占比情况
可以看到没有缺失值
2. 特征工程(Feature Engineering)
统计目标列的情况,这里涉及到样本的不平衡问题
可以看到数据严重的不均衡,样本不平衡影响分类器的学习,下面进行欠采样。
可以看到数据比较平衡了。
3. 特征选择
(1)由于Spark机器学习只支持double类型的数据,所以我们将数据转化为double类型的。
(2) 将特征聚合为向量
(3) 我们可以看到Time和Amount对应的向量的规格和其他特征相差较大,因此我们需对其进行归一化处理。
(4)我们看到特征向量一共有30个特征,特征的个数太多了,下面我们对特征进行卡方特征选择,选取10个最有预测能力的特征。
可以看到特征向量的维度变为10维了。
4.将数据划分为训练集和测试集
可以看到,a表和b表的比例大约为10:1。
5. 模型设定与预测
(1)对训练集df6表构造逻辑回归模型
(2)此刻的模型已经建立好了,下面我们用测试集进行预测
其中prediction列就是测试集的预测结果。
(3)对模型进行打分,评价模型的好坏
可以看到,模型的准确率达到了91%以上。
(4) 将模型保存到hdfs上面,以便下次使用
(5) 加载模型
以上就是信用卡反欺诈模型的构建过程,关注openfea,会有更多精彩的内容推荐。

相关文章推荐
- 用机器学习构建模型,进行信用卡反欺诈预测
- 使用Weka进行数据挖掘(Weka教程七)Weka分类/预测模型构建与评价
- 机器学习中的贝叶斯方法---先验概率、似然函数、后验概率的理解及如何使用贝叶斯进行模型预测(2)
- 机器学习中的贝叶斯方法---先验概率、似然函数、后验概率的理解及如何使用贝叶斯进行模型预测(1)
- 【知识】如何使用Amazon Machine Learning构建机器学习预测模型
- 机器学习实验(三):建立深度学习模型对kaggle保险索赔进行预测
- 通过 Microsoft SQL Server 2005 Analysis Services 构建库存预测模型
- Airbnb欺诈预测机器学习模型设计:准确率和召回率的故事 发表于2015-07-15 16:14| 3926次阅读| 来源AirBNB/Data| 1 条评论| 作者Ariana Radianto
- tensorflow将训练好的模型freeze,即将权重固化到图里面,并使用该模型进行预测
- 【CNTK】CNTK学习笔记之应用卷积神经网络模型进行数据预测
- 项目二:使用机器学习(SVM)进行基因预测
- [机器学习入门] 李宏毅机器学习笔记-25(Sturctured Linear Model;结构化预测-线性模型)
- 基于R语言构建的电影评分预测模型
- 利用ARIMA模型对标普500指数进行预测
- 【机器学习笔记之五】用ARIMA模型做需求预测用ARIMA模型做需求预测
- 反欺诈中所用到的机器学习模型有哪些?
- Python机器学习实践例子&&Kagle入门 Titanic乘客生存预测模型分析(利用决策树)
- 机器学习性能改善备忘单:32个帮你做出更好预测模型的技巧和窍门
- Airbnb欺诈预测机器学习模型设计:准确率和召回率的故事
- Airbnb欺诈预测机器学习模型设计:准确率和召回率的故事