Spark2.x与ElasticSearch的完美结合
2017-10-19 00:00
375 查看
ElasticSearch(简称ES)是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RestFul web接口。ElasticSearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便的目地,当前在各大公司使用非常普遍。而Spark是基于分布式内存的高性能计算框架,用来处理大量的数据。本篇文章,我将与大家探讨如何用Spark从ES中加载数据,并将数据保存到ES里面。
1. FEA-spk集成ElasticSearch
FEA-spk技术,它的底层基于最流行的大数据开发框架Spark,对各种算子的操作都是基于DataFrame的。使用FEA-spk来做交互分析,不但非常简单易懂,而且几乎和Spark的功能一样强大,更重要的一点是,它可以实现可视化,处理的数据规模更大,可以进行分布式的机器学习等。
Spark2.x与ElasticSearch的完美结合,大大丰富了FEA-spk的业务处理能力。
2. FEA处理ElasticSearch的原语实现
(1) 创建spk的连接
(2) 创建ElasticSearch的连接

(3) 加载数据到ES中
数据的格式如下表所示
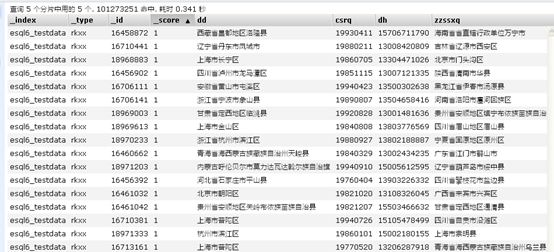
可以看到数据有一亿多条,73个字段,数据量还是比较大的。

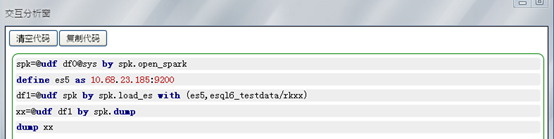
(4)查看一下df1表的前十行
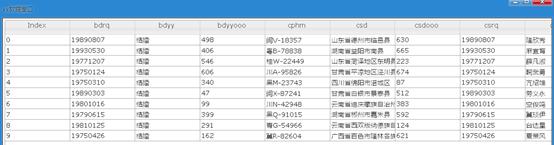
(5) 下面将df1表的数据写回到ES里面,其中spark是index,people是type。
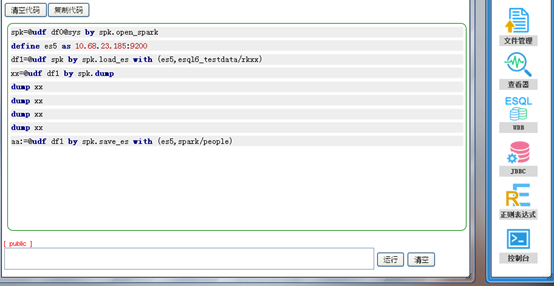
由于数据量比较大,所以我们选择后台运行。
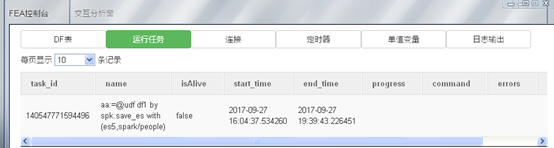
进入spark web界面,查看运行情况。
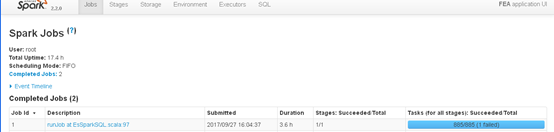
可以看到花费了3.6h,如果能够再调优一下,可能花费的时间更短
如果对我的文章感兴趣,请帮忙点个赞噢。
1. FEA-spk集成ElasticSearch
FEA-spk技术,它的底层基于最流行的大数据开发框架Spark,对各种算子的操作都是基于DataFrame的。使用FEA-spk来做交互分析,不但非常简单易懂,而且几乎和Spark的功能一样强大,更重要的一点是,它可以实现可视化,处理的数据规模更大,可以进行分布式的机器学习等。
Spark2.x与ElasticSearch的完美结合,大大丰富了FEA-spk的业务处理能力。
2. FEA处理ElasticSearch的原语实现
(1) 创建spk的连接
(2) 创建ElasticSearch的连接
(3) 加载数据到ES中
数据的格式如下表所示
可以看到数据有一亿多条,73个字段,数据量还是比较大的。
(4)查看一下df1表的前十行
(5) 下面将df1表的数据写回到ES里面,其中spark是index,people是type。
由于数据量比较大,所以我们选择后台运行。
进入spark web界面,查看运行情况。
可以看到花费了3.6h,如果能够再调优一下,可能花费的时间更短
如果对我的文章感兴趣,请帮忙点个赞噢。

相关文章推荐
- Spark2.x与ElasticSearch的完美结合
- Spark2.x写入Elasticsearch的性能测试
- apache spark 结合 elasticsearch
- 纯ASP结合VML生成完美图-折线图
- Spark2.x 快速入门教程 4
- 如何将DSP和MCU两者完美结合
- 无敌神功之“二八”原则和“四象限”的完美结合
- 推荐一个创新的东西,OPS[将表单页面数据XML化,与AJAX完美结合起来,有创意!]
- ScribeFire:和firefox完美结合的博客离线编辑器 - 博客联盟
- 开发日记]图片抽奖软件的原型设想及界面设计-打算用PowerPoint结合Vc++完美实现 (进展二)-于11月7日完工
- 大数据处理 Hadoop、HBase、ElasticSearch、Storm、Kafka、Spark
- Spark2.x学习笔记:6、在Windows平台下搭建Spark开发环境(Intellij IDEA)
- 强者联盟——Python语言结合Spark框架
- spark 读取elasticsearch中数据不完整问题
- 横向滑动+viewpage的完美结合
- 免杀后门之MSF&Veil-Evasion的完美结合
- spark2.x由浅入深深到底系列六之RDD 支持java8 lambda表达式
- 2007软件开发2.0大会课程之一:ASP.NET AJAX 与 Silverlight 的完美结合
- EasyUI1.4.4 + zTree3.5.19 完美结合框架布局 tree+tab
- Spark2.x学习笔记:10、简易电影受众系统