深度学习之基础模型-DenseNet
2017-11-05 15:22
309 查看
In this paper, we embrace this observation and introduce the Dense Convolutional Network(DenseNet), which connects each layer to every other layer in a feed-forward fashion.
DenseNets have several compelling advantages: they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters.
注:Deep Network with Stochastic depth,在训练过程中,随机去掉很多层,并没有影响算法的收敛性,说明了ResNet具有很好的冗余性。而且去掉中间几层对最终的结果也没什么影响,说明ResNet每一层学习的特征信息都非常少,也说明了ResNet具有很好的冗余性。【这个应该得益于ResNet的skip connections的作用】
从而作者让每一层都直接与前面的所有层建立连接。但DenseNet不同与ResNet:
To ensure maximum information flow between layers in the network, we connect all layers (with matching features-map sizes) directly with each other
currialy, in contrast to ResNets, we never combine features throughout summation before the are passed into a layer; instead, we combine features by concatenating them
信息传递:DenseNet提高了信息流和梯度在网络之间传递。
正则化作用:减少过拟合overfitting
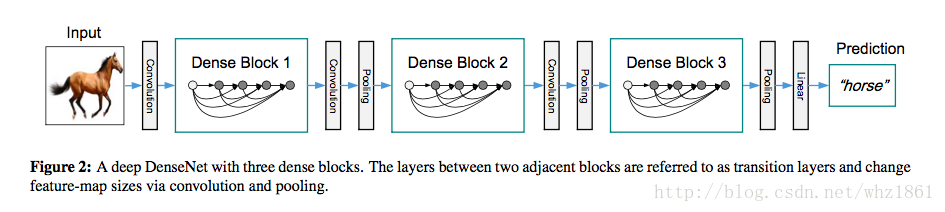
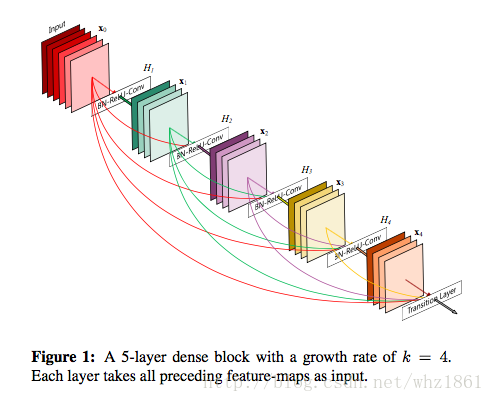
DenseNet网络结构采用传统的卷积和池化操作与Dense Block之间交替叠加,从而可以有效的增加网络深度。
结构对比
- DenseNet模块结构类型
注:为了避免DenseNet最终的channel太大,设置增产率k相对比较小,如12,即每一个卷积后输出都是12个通道的特征图

在所有数据集上,除了ImageNet外,都是只包含3个dense block层
第一个传统卷积convolution,其他数据集16层的特征图,ImageNet产生32层的特征图
3x3卷积,Padding=’SAME’
transition layer: BN+conv1x1 + average pooling2x2
最后采用global average pooling+softmax classifier
其他数据集中的3个dense block的输出分别是[32x32],[16x16],[8x8]

效果
在CIFAR数据集上,DenseNet L190 k40的效果已经超过了所有的其他网络
在C10和C00数据集上,DenseNet错误率都要比FractalNet低将近30%以上
在SVHN数据集上,DenseNet L00 k24的效果也吵过了所有其他网络
Cappacity
在没有任何压缩或者bottleneck层的前提下,网络随着L和k的增加,效果呈上升趋势
Parameter Efficiency
DenseNet在网络参数方面利用率更好。比如250层的网络结构,却只有15.3M的参数量,但却比其他参数更多的网络结构FractalNet,Wide ResNet效果要好
DenseNet-BC L00 k12网络结构采用ResNet1001 10%的参数量,却达到了相同的效果
overfitting
DenseNet较少过拟合

单个输入和多个输入的结果表明,随着网络深度的增加,效果越来越好。

和ResNet比较
相同精度的情况下,DenseNet需要的参数更少。DenseNet-201拥有20M的参数量,却能达到ResNet-101(拥有40M参数量)的效果
相同精度的情况下,DenseNet需要的计算量flops也更少。DenseNet可以使用ResNet-50的计算量,达到ResNet101的精度

通过中间图的和ResNet比较发现,同样精度的情况下,DenseNet-BC之需要ResNet参数的13
最右侧的图,表明,只有0.8M的DenseNet-BC能够和ResNet1001(具有10.2M)的效果基本等价。
DenseNets perform a similar deep supervision in an implicit fashion: a single classifier on top of the network provides direct supervision to all layers though at most two or three transition layer.

http://blog.csdn.net/u012938704/article/details/53468483
http://blog.csdn.net/gavin__zhou/article/details/53445539
http://blog.csdn.net/u014380165/article/details/75142664
http://www.sohu.com/a/161639222_114877
DenseNets have several compelling advantages: they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters.
思想
denseNet的思想来自于作者之前的工作(随机深度网络,Deep Network with Stochastic depth),其训练过程中采用随机dropout一些中间层的方法改进ResNet,发现可以显著提高ResNet的泛化能力。注:Deep Network with Stochastic depth,在训练过程中,随机去掉很多层,并没有影响算法的收敛性,说明了ResNet具有很好的冗余性。而且去掉中间几层对最终的结果也没什么影响,说明ResNet每一层学习的特征信息都非常少,也说明了ResNet具有很好的冗余性。【这个应该得益于ResNet的skip connections的作用】
从而作者让每一层都直接与前面的所有层建立连接。但DenseNet不同与ResNet:
To ensure maximum information flow between layers in the network, we connect all layers (with matching features-map sizes) directly with each other
currialy, in contrast to ResNets, we never combine features throughout summation before the are passed into a layer; instead, we combine features by concatenating them
优点
减少参数量:在ImageNet上相同精度下,DenseNet参数量只有ResNet的一半信息传递:DenseNet提高了信息流和梯度在网络之间传递。
正则化作用:减少过拟合overfitting
网络结构
DenseNet网络结构采用传统的卷积和池化操作与Dense Block之间交替叠加,从而可以有效的增加网络深度。
结构对比
| 网络名称 | 说明 |
|---|---|
| ResNet | xl=Hl(xl−1)+xl−1 |
| DenseNet | xl=Hl([x0,x1,....,xl−1]) |
| 名称 | 说明 |
|---|---|
| Dense block | Conv1x1->Conv3x3 |
| DenseNet-B | BN->ReLU->Conv1x1->BN->ReLU->Conv3x3 |
| Densenet-BC | 在DenseNet-B的基础上,令输出的的channel个数缩小,由m变成θm,具有压缩功能 |
| Transition layer | dense block -> BN+Conv1x1+Pooling2x2 -> dense block |
网络整体结构
在所有数据集上,除了ImageNet外,都是只包含3个dense block层
第一个传统卷积convolution,其他数据集16层的特征图,ImageNet产生32层的特征图
3x3卷积,Padding=’SAME’
transition layer: BN+conv1x1 + average pooling2x2
最后采用global average pooling+softmax classifier
其他数据集中的3个dense block的输出分别是[32x32],[16x16],[8x8]
结果分析
实验1
效果
在CIFAR数据集上,DenseNet L190 k40的效果已经超过了所有的其他网络
在C10和C00数据集上,DenseNet错误率都要比FractalNet低将近30%以上
在SVHN数据集上,DenseNet L00 k24的效果也吵过了所有其他网络
Cappacity
在没有任何压缩或者bottleneck层的前提下,网络随着L和k的增加,效果呈上升趋势
Parameter Efficiency
DenseNet在网络参数方面利用率更好。比如250层的网络结构,却只有15.3M的参数量,但却比其他参数更多的网络结构FractalNet,Wide ResNet效果要好
DenseNet-BC L00 k12网络结构采用ResNet1001 10%的参数量,却达到了相同的效果
overfitting
DenseNet较少过拟合
实验2
单个输入和多个输入的结果表明,随着网络深度的增加,效果越来越好。
和ResNet比较
相同精度的情况下,DenseNet需要的参数更少。DenseNet-201拥有20M的参数量,却能达到ResNet-101(拥有40M参数量)的效果
相同精度的情况下,DenseNet需要的计算量flops也更少。DenseNet可以使用ResNet-50的计算量,达到ResNet101的精度
讨论
Model compactness
上图left比较DenseNet各个模型的参数效率。通过中间图的和ResNet比较发现,同样精度的情况下,DenseNet-BC之需要ResNet参数的13
最右侧的图,表明,只有0.8M的DenseNet-BC能够和ResNet1001(具有10.2M)的效果基本等价。
Implicit Deep Supervision
One explanation for the improved accuracy of dense convolution networks may be that individual layers receive additional supervision from the loss function through the shorter connections.DenseNets perform a similar deep supervision in an implicit fashion: a single classifier on top of the network provides direct supervision to all layers though at most two or three transition layer.
Stochastic vs. deterministic connection
对了一下和作者之前的工作《Deep networks with stochastic depth》。DenseNet的思想来源于之前的工作。Feature Reuse
参考文献
https://arxiv.org/pdf/1608.06993.pdfhttp://blog.csdn.net/u012938704/article/details/53468483
http://blog.csdn.net/gavin__zhou/article/details/53445539
http://blog.csdn.net/u014380165/article/details/75142664
http://www.sohu.com/a/161639222_114877

相关文章推荐
- 深度学习基础(六):LSTM模型及原理介绍
- 深度学习之基础模型-VGG
- 深度学习之基础模型-总结
- 深度学习之基础模型-Xception
- 深度学习之基础模型-总结
- 深度学习之基础模型-FractalNet
- 深度学习基础模型算法原理及编程实现--04.改进神经网络的方法
- 深度学习之基础模型-NIN
- 深度学习之基础模型-PolyNet
- 深度学习基础模型算法原理及编程实现--02.线性单元
- 深度学习之基础模型-SEP-Nets
- 深度学习之基础模型---AlexNet
- 深度学习基础模型算法原理及编程实现--09.自编码网络
- 深度学习基础模型算法原理及编程实现--06.循环神经网络
- 【深度学习 论文综述】深度神经网络全面概述:从基本概念到实际模型和硬件基础
- 深度学习之基础模型—resNet
- 深度学习基础模型算法原理及编程实现--05.卷积神经网络
- 深度学习之基础模型-mobileNet
- 深度学习基础模型算法原理及编程实现--01.感知机
- 深度学习训练模型调参策略