深度学习之基础模型-Xception
2017-10-30 18:08
543 查看
We present an interpretation of Inception modules in convolutional neural networks as being an intermediate step in-between regular convolution and the depth wise separable convolution operation(a depth wise convolution followed by a point wise convolution).
假设:
卷积在3个维度上进行学习,因此卷积需要既要考虑空间相关性,又要考虑channel相关性:
spatial dimensions(width and height)
channel dimension
corss-channel correlations和spatial correlations是充分解耦合的,没有必要将他们叠加在一起
注:关于空间width和height解耦合可以参考Inception V3论文
思想:将Inception modul拆分成一系列操作,独立处理spatial-correlations和cross-channel correlations,网络处理起来更加简单有效
首先通过‘1x1’卷积,将输入数据拆分cross-channel相关性,拆分成3或者4组独立的空间
然后,通过‘3x3’或者‘5x5’卷积核映射到更小的空间上去
Q:为什么Inception module可以用depthwise separable convolution替代?
首先,对于原始的Inception模块,如Inception V3,结构如下:

模块中,基本上先通过一系列1x1卷积降维,然后再通过3x3卷积提取特征。如果我们将上述结构再进行简化,可以得到如下简化结构:

从上图中我们可以看出,1x1卷积将输入数据的channel维度上进行了拆解,再输送到空间卷积3x3,改写成下图:

可以考虑一种更加极端的情况:3x3卷积在1x1卷积后的每一个通道上运行,则有:
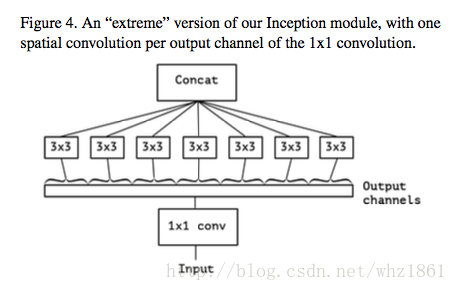
我们可以从上图上,看到该模块将输入数据在channel维度上进行解耦合,该模块称之为‘extreme’version of Inception module,这个思想和depthwise separable convolution非常相似。
操作顺序不同:
depth wise separable convolutions:先进行channel-wise 空间卷积,然后1x1卷积进行融
4000
合
Inception:先进行1x1卷积,然后进行channel-wise空间卷积
非线性激励函数:
depthwise separable convolution:两个操作之间没有激励函数
Inception:两个操作之间,添加了ReLU非线性激励
但是,作者介绍说,上述两个不同点中,第一个并不是太重要,原因在与整个结构模型是Inception模块不断叠加的,从而改变一下结构中的模块划分顺序,两者基本上就等价了。而对于第二点就比较重要了。基本上,整个网络结构就是把Inception module换成了depthwise separable convlution,但是里面的深层次含义却很重要。

说明:
整个网络结构具有14个模块,36个卷积
残差连接
最后采用logistic regression
注:ImageNet数据集为单标签,JFT数据集为多标签
正则化
注:使用tensorflow, 60块NVIDIA K80显卡
实验1:
参数个数

注:两者在参数个数和速度上相差不大
ImageNet上的精度

注:Xception的效果最好
收敛速度

注:Xception收敛速度更快
实验2:
在JFT上的效果

with fully-connected layers

without fully-connected layers

注:相比较与ImageNet数据集,Xception在JFT数据集上的效果更加明显
实验3:

带有残差连接的网络不仅收敛更加快,效果也更加好
注:作者对这种对比结果也提出了质疑,这种效果仅针对这个特殊的网络结构
实验4:

不带激活函数的网络结构,效果更好
注:和《InceptionV3》中的结论相反,可能和特征空间的深度有关
网络特征比较深的时候,非线性激活有帮助
网络结构比较浅的时候,非线性激活反而有害
http://blog.csdn.net/KangRoger/article/details/69929915
https://www.leiphone.com/news/201708/KGJYBHXPwsRYMhWw.html
http://blog.csdn.net/tangzy_/article/details/53672620
思想
基于Inception系列网络结构的基础上,结合depthwise separable convolution
假设:
卷积在3个维度上进行学习,因此卷积需要既要考虑空间相关性,又要考虑channel相关性:
spatial dimensions(width and height)
channel dimension
corss-channel correlations和spatial correlations是充分解耦合的,没有必要将他们叠加在一起
注:关于空间width和height解耦合可以参考Inception V3论文
思想:将Inception modul拆分成一系列操作,独立处理spatial-correlations和cross-channel correlations,网络处理起来更加简单有效
首先通过‘1x1’卷积,将输入数据拆分cross-channel相关性,拆分成3或者4组独立的空间
然后,通过‘3x3’或者‘5x5’卷积核映射到更小的空间上去
Q:为什么Inception module可以用depthwise separable convolution替代?
首先,对于原始的Inception模块,如Inception V3,结构如下:
模块中,基本上先通过一系列1x1卷积降维,然后再通过3x3卷积提取特征。如果我们将上述结构再进行简化,可以得到如下简化结构:
从上图中我们可以看出,1x1卷积将输入数据的channel维度上进行了拆解,再输送到空间卷积3x3,改写成下图:
可以考虑一种更加极端的情况:3x3卷积在1x1卷积后的每一个通道上运行,则有:
我们可以从上图上,看到该模块将输入数据在channel维度上进行解耦合,该模块称之为‘extreme’version of Inception module,这个思想和depthwise separable convolution非常相似。
操作顺序不同:
depth wise separable convolutions:先进行channel-wise 空间卷积,然后1x1卷积进行融
4000
合
Inception:先进行1x1卷积,然后进行channel-wise空间卷积
非线性激励函数:
depthwise separable convolution:两个操作之间没有激励函数
Inception:两个操作之间,添加了ReLU非线性激励
但是,作者介绍说,上述两个不同点中,第一个并不是太重要,原因在与整个结构模型是Inception模块不断叠加的,从而改变一下结构中的模块划分顺序,两者基本上就等价了。而对于第二点就比较重要了。基本上,整个网络结构就是把Inception module换成了depthwise separable convlution,但是里面的深层次含义却很重要。
网络结构
整个网络结构,不仅借鉴了depthwise separable convolution的思想,也结合了ResNet的思想,最后作者也比较了ResNet在其中的作用。结构如下:说明:
整个网络结构具有14个模块,36个卷积
残差连接
最后采用logistic regression
效果分析
实验参数:| name | ImageNet | JFT |
|---|---|---|
| Optimizer | SGD | RMsprop |
| Momentum | 0.9 | 0.9 |
| Initial learning rate | 0.045 | 0.001 |
| Learning rate decay | decay of rate 0.94 every 2 epochs | decay of rate 0.9 every 3,000,000 samples |
正则化
| operation | value |
|---|---|
| weight decay | InceptionV3 L2 regularization(4e-5)/Xception(1e-5) |
| dropout | ImageNet rate=0.5/JFT no dropout |
| Auxiliary loss tower | InceptionV3 included/Xception not included |
实验1:
与InceptionV3对比
参数个数
注:两者在参数个数和速度上相差不大
ImageNet上的精度
注:Xception的效果最好
收敛速度
注:Xception收敛速度更快
实验2:
full-connected layer的影响
在JFT上的效果
with fully-connected layers
without fully-connected layers
注:相比较与ImageNet数据集,Xception在JFT数据集上的效果更加明显
实验3:
残差连接的作用
带有残差连接的网络不仅收敛更加快,效果也更加好
注:作者对这种对比结果也提出了质疑,这种效果仅针对这个特殊的网络结构
实验4:
激活函数的作用:在depthwise与pointwise之间使用不同的激活函数
不带激活函数的网络结构,效果更好
注:和《InceptionV3》中的结论相反,可能和特征空间的深度有关
网络特征比较深的时候,非线性激活有帮助
网络结构比较浅的时候,非线性激活反而有害
参考文献
https://arxiv.org/pdf/1610.02357.pdfhttp://blog.csdn.net/KangRoger/article/details/69929915
https://www.leiphone.com/news/201708/KGJYBHXPwsRYMhWw.html
http://blog.csdn.net/tangzy_/article/details/53672620

相关文章推荐
- 深度学习之基础模型-FractalNet
- 深度学习基础(六):LSTM模型及原理介绍
- 深度学习之基础模型-SEP-Nets
- 深度学习之基础模型-VGG
- 深度学习基础模型算法原理及编程实现--05.卷积神经网络
- 深度学习之基础模型-DenseNet
- 【深度学习 论文综述】深度神经网络全面概述:从基本概念到实际模型和硬件基础
- 深度学习之基础模型-NIN
- 深度学习之基础模型-总结
- 深度学习基础模型算法原理及编程实现--01.感知机
- 深度学习之基础模型-总结
- 深度学习基础模型算法原理及编程实现--09.自编码网络
- 深度学习之基础模型-mobileNet
- 深度学习基础模型算法原理及编程实现--06.循环神经网络
- 深度学习之基础模型—resNet
- 深度学习基础模型算法原理及编程实现--04.改进神经网络的方法
- 深度学习之基础模型-PolyNet
- 深度学习之基础模型---AlexNet
- 深度学习基础模型算法原理及编程实现--02.线性单元
- 如何选择深度学习模型中最优的学习率和源码实现