(HA)DRBD原理简介到实战配置
2017-10-29 13:59
435 查看
前言:先把DRBD高可用大概的写一下,后面再引入分布式系统与DRBDR相结合更加明显凸显他们各自实现的功能,从而整体体现出相对比较可靠(稳定)的状态。
一、DRBD简介
1、DRBD是啥、能干啥?
DRBD全称::Distributed ReplicatedBlock Device分布式块设备复制,是一种基于软件的,无共享的,复制的存储解决方案,镜像主机之间的块设备(硬盘,分区,逻辑卷等)的内容。DRBD功能是由drbd内核模块和相关脚本构成,用来构建高可用集群(主要是储存方面)。一般来说,首先DRBD分为两块,一块是在本地,另一块是在远端,其次还会给这两块分别划分等级,一开始划给本地这块primary,给远端那块划secondary。
关于DRBD镜像数据:
实时:当应用程序修改设备上的数据时,复制会持续发生。
透明:应用程序不需要知道数据存储在多台主机上。
同步或异步:通过同步镜像,在所有主机上执行写入操作后,都会通知应用程序的写入完成。通过异 步镜像,当本地完成写入操作时,应用程序将被通知写入完成,这通常在传播到其他主机之前。
2、DRBD实现的原理
DRBD primary本地这块(主机磁盘)负责接受写入的数据,并且把写入的数据发送给DRBD Secondary远端那块(主机磁盘),简单来说就是把写入本地的数据,通过网络传输的方式复制到远端,在远端建立了一个数据镜像。
3、三种复制模式
协议A:
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点。
协议B:
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘。
协议C:
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽。
注意:一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,我们在生产环境使用时须慎重选项使用哪一种协议。
4、DRBD工作原理图
大牛版:
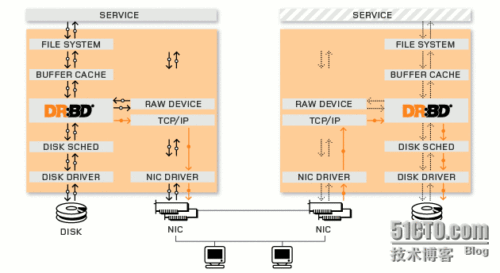
菜鸟版:
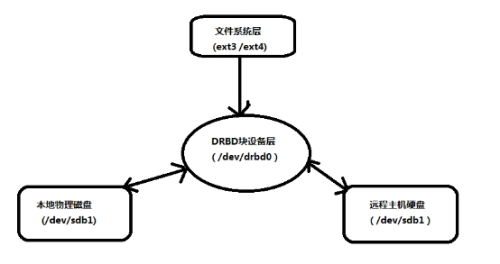
菜鸟版图片来自简书作者:宇信智臻sy
二、DRBD实战配置
1、环境布置
系统版本、软件:vmworkstation、CENTOS 7.3
虚拟机及IP:两台虚拟机node3(10.0.0.5)、node4(10.0.0.6)
软件包:yum安装kmod-drbd84、drbd84-utils(包要同版本)
2、通信、同步配置
⑴、修改node3、nide4的hosts文件,通过此文件解析到主机IP
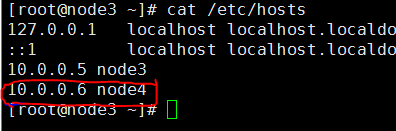
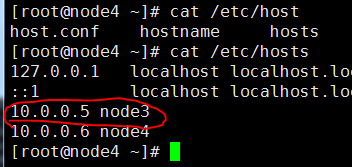
⑵、ssh免密登入
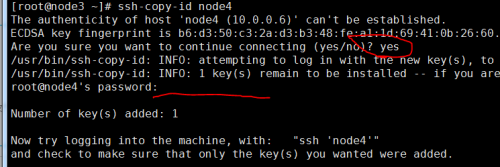
⑶、设置两台服务器时钟服务器
3、安装elrepo源,安装drbd
4、在两台虚拟机服务器上个各添加一块大小相同磁盘,重启虚拟机
5、两台服务器配置drbd配置文件
6、启动brbd内核模块、创建启动资源、查看磁盘状态
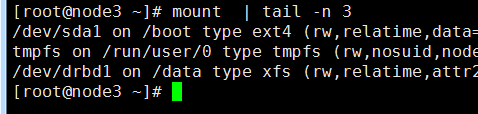
三、简单测试drbr高可用
三、总结
到此为止drbd的一般搭建就完成了,学过KEEPAKIVED实现高可用的同学可能会觉得drdb这个实现方式有点太LOW了,实现高可用还需要人工干预,那在实际生产环境还一直放个人在旁边守着?所以为了让他实现“自动化”我后面会写用drbd+corosync+pacemaker+crmsh来自动的切换故障节点,这样才够“高大上”。
一、DRBD简介
1、DRBD是啥、能干啥?
DRBD全称::Distributed ReplicatedBlock Device分布式块设备复制,是一种基于软件的,无共享的,复制的存储解决方案,镜像主机之间的块设备(硬盘,分区,逻辑卷等)的内容。DRBD功能是由drbd内核模块和相关脚本构成,用来构建高可用集群(主要是储存方面)。一般来说,首先DRBD分为两块,一块是在本地,另一块是在远端,其次还会给这两块分别划分等级,一开始划给本地这块primary,给远端那块划secondary。
关于DRBD镜像数据:
实时:当应用程序修改设备上的数据时,复制会持续发生。
透明:应用程序不需要知道数据存储在多台主机上。
同步或异步:通过同步镜像,在所有主机上执行写入操作后,都会通知应用程序的写入完成。通过异 步镜像,当本地完成写入操作时,应用程序将被通知写入完成,这通常在传播到其他主机之前。
2、DRBD实现的原理
DRBD primary本地这块(主机磁盘)负责接受写入的数据,并且把写入的数据发送给DRBD Secondary远端那块(主机磁盘),简单来说就是把写入本地的数据,通过网络传输的方式复制到远端,在远端建立了一个数据镜像。
3、三种复制模式
协议A:
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点。
协议B:
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘。
协议C:
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽。
注意:一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,我们在生产环境使用时须慎重选项使用哪一种协议。
4、DRBD工作原理图
大牛版:
菜鸟版:
菜鸟版图片来自简书作者:宇信智臻sy
二、DRBD实战配置
1、环境布置
系统版本、软件:vmworkstation、CENTOS 7.3
虚拟机及IP:两台虚拟机node3(10.0.0.5)、node4(10.0.0.6)
软件包:yum安装kmod-drbd84、drbd84-utils(包要同版本)
2、通信、同步配置
⑴、修改node3、nide4的hosts文件,通过此文件解析到主机IP
⑵、ssh免密登入
[root@node3 ~]#ssh-keygen #多次回车直到密钥创建完成 [root@node3 ~]#ssh-copy-id node4
⑶、设置两台服务器时钟服务器
[root@node3 ~]# crontab -l */5 * * * * ntpdate cn.pool.ntp.org #在node3 [root@node4 ~]# crontab -l */5 * * * * ntpdate cn.pool.ntp.org #在node4⑷、关闭防火墙和SELINUX
3、安装elrepo源,安装drbd
[root@node3 ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org [root@node3 ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm [root@node3 ~]# yum install -y kmod-drbd84 drbd84-utils
4、在两台虚拟机服务器上个各添加一块大小相同磁盘,重启虚拟机
5、两台服务器配置drbd配置文件
[root@node3 ~]# cat /etc/drbd.conf ##不用改动此文件 # You can find an example in /usr/share/doc/drbd.../drbd.conf.example include "drbd.d/global_common.conf"; include "drbd.d/*.res";
#配置全局配置文件
[rootglob@node3 ~]# cat /etc/drbd.d/global_common.conf
global {
usage-count no;
# minor-count dialog-refresh disable-ip-verification
}
common {
protocol C; #使用DRBD的同步协议
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
}
startup {
}
options {
}
disk {
on-io-error detach;
}
net {
}
syncer {
rate 1024M;
}##创建资源配置文件
cat /etc/drbd.d/mysql.res
resource mysql { #资源名称
protocol C; #使用协议
meta-disk internal;
device /dev/drbd1; #DRBD设备名称
syncer {
verify-alg sha1;# 加密算法
}
net {
allow-two-primaries;
}
on node3 {
disk /dev/sdb; drbd1使用的磁盘分区为"mysql",指定新加的磁盘
address 10.0.0.5:7789; #设置DRBD监听地址与端口
}
on node4 {
disk /dev/sdb;
address 10.0.0.6:7789;
}
}##在node4也使用相同的配置 [root@node3 ~]# scp -p global_common.conf mysql.res
6、启动brbd内核模块、创建启动资源、查看磁盘状态
#node3、node4查看内核模块是否已经加载 [root@node3 ~]# lsmod | grep drbd #没有则主动加载 [root@node3 ~]# modprobe drbd #如果显示没有此模块是因为系统内核版本太低,不支持模块需要升级 #执行可以用 yum install kernel* 方式来更新 #也可以 yum kernel-devel kernel kernel-headers -y ##########################node4相同操作######################################
#创建资源 [root@node3 ~]# drbdadm create-md mysql initializing activity log initializing bitmap (160 KB) to all zero Writing meta data... New drbd meta data block successfully created. #启动资源、指定本机为primary [root@node3 ~]# drbdadm up mysql [root@node3 ~]# drbdadm -- --force primary mysql #node4 [root@node4 ~]# drbdadm create-md mysql [root@node4 ~]# drbdadm up mysql
[root@nod4 ~]# drbdadm dstate mysql #Inconsistent/Inconsistent #本地和对等节点的硬盘有可能为下列状态之一: #Diskless 无盘:本地没有块设备分配给DRBD使用,这表示没有可用的设备,或者使用drbdadm命令手工分离或是底层的I/O错误导致自动分离 #Attaching:读取无数据时候的瞬间状态 #Failed 失败:本地块设备报告I/O错误的下一个状态,其下一个状态为Diskless无盘 #Negotiating:在已经连接的DRBD设置进行Attach读取无数据前的瞬间状态 #Inconsistent:数据是不一致的,在两个节点上(初始的完全同步前)这种状态出现后立即创建一个新的资源。此外,在同步期间(同步目标)在一个节点上出现这种状态 #Outdated:数据资源是一致的,但是已经过时 #DUnknown:当对等节点网络连接不可用时出现这种状态 #Consistent:一个没有连接的节点数据一致,当建立连接时,它决定数据是UpToDate或是Outdated #UpToDate:一致的最新的数据状态,这个状态为正常状态7、格式化drbd磁盘
[root@node3 ~]# mkfs.xfs /dev/drbd1 ...8、挂载/dev/drbd1磁盘到primary
[root@node3 ~]# mkdir /data [root@node3 ~]# mount /dev/drbd1 /data
三、简单测试drbr高可用
##先在主从结点上创建一个文件,在从节点同样创建一个/data目录 [root@node3 data]# echo "11111" > 123.txt [root@node4 /]#mkdir data ##先把主结点降为从结点(先卸载才能变为从): [root@node3 etc]# umount /data/ [root@node3 etc]# drbdadm secondary mysql [root@node3 etc]# drbd-overview NOTE: drbd-overview will be deprecated soon. Please consider using drbdtop. 1:mysql/0 Connected Secondary/Secondary UpToDate/UpToDate ## [root@node4 ~]# drbdadm primary mysql You have new mail in /var/spool/mail/root [root@node4 ~]# drbd-overview NOTE: drbd-overview will be deprecated soon. Please consider using drbdtop. 1:mysql/0 Connected Primary/Secondary UpToDate/UpToDate 3、然后我们挂载试一下: [root@node3 ~]# mount /dev/drbd1 /data/ [root@node3 ~]# cat /data/123.txt 11111
三、总结
到此为止drbd的一般搭建就完成了,学过KEEPAKIVED实现高可用的同学可能会觉得drdb这个实现方式有点太LOW了,实现高可用还需要人工干预,那在实际生产环境还一直放个人在旁边守着?所以为了让他实现“自动化”我后面会写用drbd+corosync+pacemaker+crmsh来自动的切换故障节点,这样才够“高大上”。

相关文章推荐
- 高可用集群(HA)之DRBD原理和基础配置
- Flume NG 简介及配置实战
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- 《which命令实战及原理详解-PATH实战配置》
- DRBD简介 安装、编译报错解决 DRBD的配置、初始化及同步、主备模型
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- [Link]Flume NG 简介及配置实战
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- ZooKeeper简介、设计原理、主要配置及集群
- 李克华 云计算高级群: 292870151 195907286 交流:Hadoop、NoSQL、分布式、lucene、solr、nutch kafka入门:简介、使用场景、设计原理、主要配置及集群搭
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- DNS原理及实战配置指南
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- Kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
- Flume NG 简介及配置实战