当我们在谈论 Deep Learning:AutoEncoder 及其相关模型
2017-10-27 14:42
246 查看
引言
AutoEncoder 是 Feedforward Neural Network 的一种,曾经主要用于数据的降维或者特征的抽取,而现在也被扩展用于生成模型中。与其他 Feedforward NN 不同的是,其他 Feedforward NN 关注的是 Output Layer 和错误率,而 AutoEncoder 关注的是 Hidden Layer;其次,普通的 Feedforward NN 一般比较深,而 AutoEncoder 通常只有一层 Hidden Layer。本篇文章会主要介绍传统的 AutoEncoder 相关模型、以及生成模型 Variational AutoEncoder。为了方便讲述,以下主要以单层 Hidden Layer 的 AutoEncoder 为例。
AutoEncoder
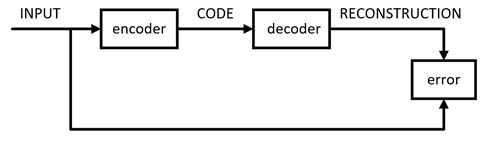
原始 AutoEncoder原始的 AutoEncoder 结构很简单:Input Layer、Hidden Layer、Output Layer。此网络的约束有:
Hidden Layer 的维度要远小于 Input Layer
Output 用于重构 Input,也即让误差
最小
于是,可以用 Hidden Layer 中神经元组成的向量(这里我们称为 Code)来表示 Input,就达到了对 Input 压缩的效果。AutoEncoder 的训练方式就是普通的 BP。其中,将 Input 压缩为 Code 的部分称为 encoder,将 Code 还原为 Input 的部分称为 decoder。于是,AutoEncoder 的结构可以表示为
其数学表达式如下,其中
、
分别表示
encoder 和 decoder
可以看出,AutoEncoder 其实是增强的 PCA:AutoEncoder 具有非线性变换单元,因此学出来的 Code 可能更精炼,对 Input 的表达能力更强。
虽然用 AutoEncoder 来压缩理论上看起来很智能,但是实际上并不太好用:
由于 AutoEncoder 是训练出来的,故它的压缩能力仅适用于与训练样本相似的样本
AutoEncoder 还要求 encoder 和 decoder 的能力不能太强。极端情况下,它们有能力完全记忆住训练样本,那么 Code 是什么也就不重要了,更不用谈压缩能力了
下面再简要介绍一些 AutoEncoder 的扩展。
Sparse AutoEncoder
Sparse 本身已经被研究了很多年了,比如曾辉煌一时的 Sparse Representation。Sparse AutoEncoder(SAE)其实就是对 AutoEncoder 的 Code 增加了稀疏的约束。而稀疏具有很多良好的性质,如:
有降维的效果,可以用于提取主要特征
由于可以抓住主要特征,故具有一定抗噪能力
稀疏的可解释性好,现实场景大多满足这种约束(如“奥卡姆剃刀定律”)
增加了稀疏约束后的 AutoEncoder 的损失函数定义如下:
其中,
表示 KL散度,
表示网络中神经元的期望激活程度(若
Activation 为 Sigmoid 函数,此值可设为 0.05,表示大部分神经元未激活),
表示第
个神经元的平均激活程度。在此处,KL散度
定义如下
其中,
定义为训练样本集上的平均激活程度,公式如下。其中
表示第
个训练样本
Denoising AutoEncoder
Denoising AutoEncoder(DAE)是在“Vincent Extracting and composing robust features with denoising autoencoders, 2008”中提出的。本质就是在原样本中增加噪声,并期望利用 DAE 将加噪样本来还原成纯净样本。
在文章中,作者以图像为例,对图像中的像素以一定概率遮挡,作为输入。随后利用 DAE 进行恢复。由于增加了噪声,因此学习出来的 Code 会更加稳健。其次,论文中还从各种方面(流形、生成模型、信息论等等)对 DAE 进行了解释。但是由于 DAE 应用不多,这里就不展开了,有兴趣的同学可以参考原文。
其他 AutoEncoder
除了上述的 AutoEncoder,为了学习出更加稳健,表达能力更强的 Code,还有其他的 AutoEncoder,如:
Contrative AutoEncoder(CAE),在文章"Contractive auto-encoders: Explicit invariance during feature extraction, 2011"中提出。其与 DAE 的区别就在于约束项进行了修改,意在学习出更加紧凑稳健的 Code。
Stacked AutoEncoder(SAE),在文章“Greedy Layer-Wise Training of Deep Networks, 2007”中提出。作者对单层 AutoEncoder 进行了扩展,提出了多层的 AutoEncoder,意在学习出对输入更抽象、更具扩展性的 Code 的表达。
除此之外,还有将传统 FNN 网络中的结构融入到 AutoEncoder 的,如:Convolutional Autoencoder、 Recursive Autoencoder、 LSTM Autoencoder 等等。
Autoencoder 期望利用样本自适应学习出稳健、表达能力强、扩展能力强的 Code 的设想很好,但是实际中应用场景却很有限。一般可以用于数据的降维、或者辅助进行数据的可视化分析。有学者另辟蹊径,借鉴了 Autoencoder 的思想,将其用于数据的生成,取得到惊人的效果,如下面会介绍的 Variational AutoEncoder。
Variational AutoEncoder
Variational AutoEncoder(VAE)是由 Kingma 和 Welling 在“Auto-Encoding Variational Bayes, 2014”中提出的一种生成模型。VAE 作为目前(2017)最流行的生成模型之一,可用于生成训练样本中没有的样本,让人看到了 Deep Learning 强大的无监督学习能力。如下图这张广为人知的“手写数字生成图”,就是由 VAE 产生的。

判别模型 与 生成模型
我们都知道一般有监督学习可以分为两种模型:判别模型(DM,Discriminative Model)和生成模型(GM,Generative Model)。下面我们以分类问题为例,简单回顾一下其概念。
对于分类问题,本质需要解决的其实就是最大化后验概率,即
于是,可以衍生出两种方案。第一种方法如下:
由于
原问题就转化为了求
和
,这就是生成模型特点:需要直接或间接对
建模。常见的生成模型有隐马尔可夫模型(HMM)、朴素贝叶斯、高斯混合模型(GMM)等等。
形象一点地表达,即为了求样本
属于每一类的概率,我们先求解每一类出现的概率;并对每一类分别建模,求出样本
在该类发生的概率。最后利用贝叶斯公式算出
。
其二种方法即,我们可以直接对后验
建模,显性或隐形地求出其表达式。对样本
,代入公式求解出每一类的后验概率,取其中最大值即可。这就是判别模型。常见的判别模型有线性回归模型、支持向量机(SVM)、神经网络等等,
VAE
VAE 跟传统 AutoEncoder 关系并不大,只是思想及架构上也有 Encoder 和 Decoder 两个结构而已。跟 AutoEncoder 不同,VAE 理论跟实际效果都非常惊艳,理论上涉及到的主要背景知识也比较多,包括:隐变量(Latent Variable Models)、变分推理(Variational Inference)、Reparameterization Trick 等等。
由于涉及到的知识较多,本部分只会对 VAE 进行简要介绍,省略很多证明。本部分讲解思路参考论文"Tutorial on Variational Autoencoders"和博客“Tutorial
- What is a variational autoencoder? ”。
首先,先定义问题:我们希望学习出一个模型,能产生训练样本中没有,但与训练集相似的数据。换一种说法,对于样本空间
,当以
抽取数据时,我们希望以较高概率抽取到与训练样本近似的数据。对于手写数字的场景,则表现为生成像手写数字的图像。
对于我们期望获取的数据
,其不同维度之间可能存在特定的联系。将这些联系对应的因素单独抽取出来作为特征,即隐变量(Latent Variables),写作
。则原来对
建模转为对
进行建模,同时有
其中,
是隐变量空间
中的点,
是模型参数空间
中的点。此时可以分别对
和
建模,这就与上面提到的生成模型是一致的,因此
VAE 是无监督的生成模型。对于手写数字的场景,隐变量
可以理解成图像对应的真实数字、书写的角度、笔尖宽度等等方面。
为了计算这个积分,首先需要给出
的表达形式。在 VAE 中,作者选择高斯分布,即
其中,
表示单位矩阵,
为超参数。
为将
映射到
的函数,即
。
此时,还需要给出
的表达式。不过,其中隐变量
到底代表什么(对应的数字、书写的角度、笔尖宽度等等,难以人工穷举),以及它们对应的表达式都是很难人工定义的。这里,作者给出一个很巧妙的解决方法,即取
,同时
利用多层
DNN 来学习。当然,真实的隐变量不可能是简单的
。巧妙之处在于,由于任何
维的分布,都可以利用
维的高斯分布经过某种复杂函数变换得到。因此,
对应的多层
DNN,前几层负责将高斯分布的
映射到真正的隐变量,后几层负责将这个隐变量映射到
。
接下来我们可以开始解决最大化
的问题,公式为
如果
的数量较少,我们就可以利用采样来计算积分,即
但若现在隐变量
维度很大时,就会需要极大量的样本,几乎是不可能计算的。但是根据经验可以得知,对大多数
来说,
,对估计
没有帮助。于是只需要采样那些对
有贡献的
。此时,就需要知道
,但是这个无法直接求取。VAE
中利用 Variational Inference,引入
来近似
。
关于 Variational Inference,鉴于篇幅不会展开讲,有需要了解的同学的请参考《PRML》第10章、《Deep Learning》第19章、以及其他教材。
最终,可以得到需要优化的目标 ELBO(Evidence Lower BOund),此处其定义为
其中,第一项是我们希望最大化的目标
;第二项是在数据
下真实分布
与假想分布
的距离,当
的选择合理时此项会接近为0。但公式中含有
,无法直接求解,于是将其化简后得到
上述公式中每一项的分布如下。其中
中参数
和
依然利用
DNN 来学习
由于两个高斯分布的 KL 距离可以直接计算,故当
与
中参数已知时(通过
DNN 学习),
就能求解。当
与
很接近时,
接近于0,优化此式就相当于在优化我们期望的目标
。
概率视角讲的差不多了,我们回到 DNN 视角。上述文章已经说明了我们需要最大化的目标是
于是,对于某个样本
,其损失函数可以表示为
其中,
意味着将样本
编码为隐变量
,对应于
AutoEncoder 中的 Encoder;
意味着将隐变量
恢复成
,对应着
Decoder。于是,
的意义就可以这样理解
第一项
,表示隐变量
对样本
的重构误差,并在
空间内取期望,即平均的重构误差。我们的目标就是使误差最小化
第二项
,可以理解为正则项。其计算的是
与真实
的差异,表示我们用
近似
带来的信息损失。我们也希望这个信息损失项尽可能的小
于是,VAE 的结构可以表示为
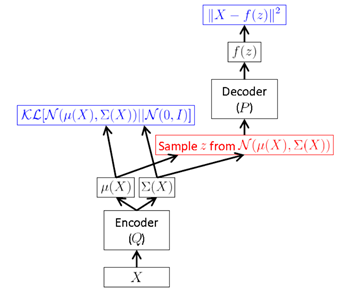
但是,上面这种方式需要在 FF 时进行采样,而这种采样操作是无法进行 BP 的。于是,作者提出一种“Reparameterization Trick”:将对
采样的操作移到输入层进行。于是就有了下面的
VAE 最终形式
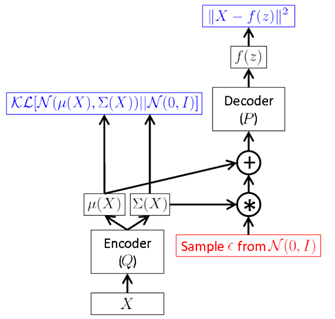
采样时,先对输入的
进行采样,然后计算
间接对
采样。通过这种方式,就可以利用
BP 来优化损失函数了。
我们再结合两个图梳理一下 VAE 的过程。
下图表示了 VAE 整个过程。即首先通过 Encoder 得到
的隐变量分布参数;然后采样得到隐变量
。接下来按公式,应该是利用
Decoder 求得
的分布参数,而实际中一般就直接利用隐变量恢复
。

下图展示了一个具有3个隐变量的 VAE 结构示意图,是对上面抽象描述的一个补充说明,不再赘述。
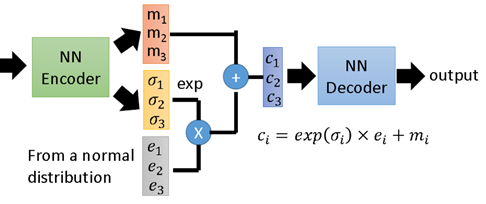
尾巴
前几周由于个人原因无暇他顾,使本篇拖更良久。近期更新可能仍会比较缓慢,但我还是会保持更新,毕竟值得写的东西太多太多。最后关于 VAE 部分,限于个人水平、VAE 的难度、篇幅等,本篇未能完全做到足够清晰明了,其中省略了不少的证明及推理过程。有需要深入研究的同学建议看完本篇后,再深入阅读下文中提到的 Paper,才能对 VAE 有更系统的理解。
Reference:
变分自编码器(VAEs):在对 VAE 结构和原理有大致了解后,对背后的推导有兴趣的同学可以参考此博客原文地址: https://zhuanlan.zhihu.com/p/27865705

相关文章推荐
- Deep Learning模型之:Sparse AutoEncoder
- Deep Learning模型之:Denoise Autoencoder
- Deep Learning模型之:AutoEncoder自编码器
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
- Linux kernel驱动相关抽象概念及其实现 之“linux设备模型kobject,kset,ktype”
- 「Deep Learning」语义图像分割模型:DeepLab系统及其发展
- Deep learning:四十八(Contractive AutoEncoder简单理解)
- 模型加速:WAE-Learning a Wavelet-like Auto-Encoder to Accelerate Deep Neural Networks
- Deep learning:九(Sparse Autoencoder练习)
- Deep learning:四十二(Denoise Autoencoder简单理解)
- Deep learning:八【sparse autoencoder】
- Auto-Encoder相关介绍(转载)
- Deep learning:九(Sparse Autoencoder练习)
- Deep Learning 练习一:Sparse Autoencoder
- Deep learning:九(Sparse Autoencoder练习)
- Deep learning:四十二(Denoise Autoencoder简单理解)
- Deep Learning:Sparse Autoencoder练习
- Deep Learning 学习 Toolbox学习记录三DenoisingAutoencoder
- <模型汇总-9> Variational AutoEncoder_VAE基础:LVM、MAP、EM、MCMC、Variational Inference(VI)
- Deep Learning 练习一:Sparse Autoencoder