论文阅读:《Human Parsing with Contextualized Convolutional Neural Network》ICCV 2015
2017-10-25 11:45
686 查看
论文地址:
https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Liang_Human_Parsing_With_ICCV_2015_paper.pdf
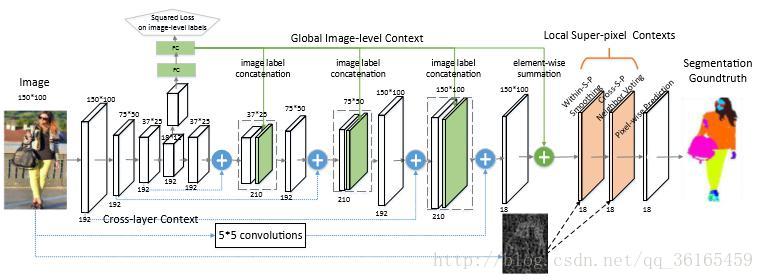
首先,输入网络的图片大小是150*100,这是根据卷积核的大小以及实验环境所决定的图片尺寸,对于不符合图片尺寸的,采用传统的resize 的方式。对于图片,先做三次下采样的操作,分别得到150*100,75*50, 37*25, 18*12 四种尺寸的图片。对于这四个尺寸的图片,经过逐步上采样,分别将之前和其相同分辨率的early, fine layers 的图像信息以及deep, coarse layer 的图像信息相结合,从而获取cross layer 的内容。这是局部的操作。
接着,一个辅助性的操作是将最小尺度的图像经过两个全连接层得到图像的预测标签,加在即将进行上采样的图像流中。同时,这些预测结果也会结合到上采样的最后一步中,用来重新定位pixel-wise 的预测权重。这是全局的操作。
最后对于已经和输入图片相同大小的预测图做一些局部的滤波优化处理,包
括within-super-pixel smoothing 和cross-super-pixel neighborhood
voting,最终得到pixel-wise prediction。
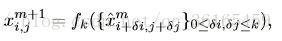
对于经过第三次image label 结合后的150*100 的特征图, 再使用element-wise 的相加方法,将全局预测标签加到特征图上。这和之前的image label 结合方式是不相同的,之前的结合方式是上采样后进过卷积操作,才输出到下一层;这种相加的方式对每一个特征元素直接相加。这样经过下一个阶段的滤波优化操作后,预测概率低的标签就会被消除掉,只保留预测概率高的标签。
b9ae
p>对于局部超像素内容, 主要有两个操作, 一是within-super-pixel smoothing,二是cross-super-pixel neighborhood voting。
Within-super-pixel smoothing 实际上就是对每一张图片产生500 个超像素,超像素实际上就是将图像聚类分割成500 个区域。然后使用以下的公式进行滤波,进行平滑处理:
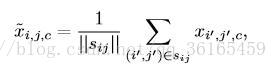
Cross-super-pixel neighborhood voting 主要是一种投票机制。对于每一超像素s,首先从RGB,LAB,HOG 三种特征描述方式建立bag-of-words 的“词典”,对于每一个像素的特征可以定义为bs,它的cross neighborhood voted response Xs 用以下公式计算:
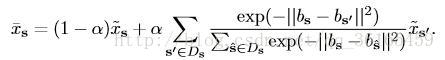
对于每一个超像素的邻接区域,查看周围与该像素的相似程度,若相似程度
越高,则投票权重越大。这两步操作有点类似池化的操作。
训练中的全连接层的dropout 比例是0.3,不是多数的0.5;采取带动量的梯度下降方法,batch-size = 12,学习率设为0.001,每30 epoch 缩小10 倍,总共训练90 个epochs。网络的对单张图片的测试速度非常快,达到0.15 秒/张,超过之前的state-of-the-art。
https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Liang_Human_Parsing_With_ICCV_2015_paper.pdf
概述
论文主要是提出了一个local-to-global-to-local 的框架结构,主要目的是从低层加入情境化的信息,这个框架是将交叉层内容(cross-layer context),全局图像层内容(global image-level context)和局部超像素内容(local super-pixel context)整合成一个统一的网络。这个网络在ATR 数据集和Fashionista 数据集上都取得了state-of-the-art 的效果。同时,作者又扩增了Chictopia 数据集,增加了10K张图片作为训练集,使得准确率又有所提高。local-to-global-to-local framework
首先,输入网络的图片大小是150*100,这是根据卷积核的大小以及实验环境所决定的图片尺寸,对于不符合图片尺寸的,采用传统的resize 的方式。对于图片,先做三次下采样的操作,分别得到150*100,75*50, 37*25, 18*12 四种尺寸的图片。对于这四个尺寸的图片,经过逐步上采样,分别将之前和其相同分辨率的early, fine layers 的图像信息以及deep, coarse layer 的图像信息相结合,从而获取cross layer 的内容。这是局部的操作。
接着,一个辅助性的操作是将最小尺度的图像经过两个全连接层得到图像的预测标签,加在即将进行上采样的图像流中。同时,这些预测结果也会结合到上采样的最后一步中,用来重新定位pixel-wise 的预测权重。这是全局的操作。
最后对于已经和输入图片相同大小的预测图做一些局部的滤波优化处理,包
括within-super-pixel smoothing 和cross-super-pixel neighborhood
voting,最终得到pixel-wise prediction。
框架细节
local-to-global-to-local
使用这个框架的优点在于能够获取cross layer 的信息,这样同时可以获取local fine 细节信息,又可以获取global 结构信息。对输入图像使用下采样是通过卷积层池化后得到的特征图,卷积核的大小是5*5。高分辨率的图像具有更多的低层语义的全局细节信息,低分辨率的图像具有更多高层的结构化信息,通过结合低层的cross layer 和上采样带有结构信息的高层特征图,能够同时获取这两个层次的特征。框架最终得到的预测结果是对每一个像素有C 个特征分数图,C 是分类的标签数。训练采用的loss function 是所有像素的交叉熵。global image-level context
这个辅助性的操作是将分辨率最低的特征图(18*12)输入到全连接层中,最终输出结果是C 类分类标签。将这些分类预测标签与中间卷积层的结果联系起来,这样就得到结合后的特征图。相邻层的特征图要经过以下卷积操作作为下一层的输出。对于经过第三次image label 结合后的150*100 的特征图, 再使用element-wise 的相加方法,将全局预测标签加到特征图上。这和之前的image label 结合方式是不相同的,之前的结合方式是上采样后进过卷积操作,才输出到下一层;这种相加的方式对每一个特征元素直接相加。这样经过下一个阶段的滤波优化操作后,预测概率低的标签就会被消除掉,只保留预测概率高的标签。
local super-pixel context
<b9ae
p>对于局部超像素内容, 主要有两个操作, 一是within-super-pixel smoothing,二是cross-super-pixel neighborhood voting。
Within-super-pixel smoothing 实际上就是对每一张图片产生500 个超像素,超像素实际上就是将图像聚类分割成500 个区域。然后使用以下的公式进行滤波,进行平滑处理:
Cross-super-pixel neighborhood voting 主要是一种投票机制。对于每一超像素s,首先从RGB,LAB,HOG 三种特征描述方式建立bag-of-words 的“词典”,对于每一个像素的特征可以定义为bs,它的cross neighborhood voted response Xs 用以下公式计算:
对于每一个超像素的邻接区域,查看周围与该像素的相似程度,若相似程度
越高,则投票权重越大。这两步操作有点类似池化的操作。
训练细节
论文使用的数据集是ATR database,总共有18 个标签,包括7700 张图片,其中6000 张训练,1000 张测试,700 张验证。另一个小的数据集是fashionista,只有685 张图片,其中229 张用来测试。论文提升准确率的另一个方法是增大数集,搜集了10000 张真实世界的human picture,构造了一个更大的数据集Chictopia 10K,网络在这个数据上的表现又提升了几个百分点的准确率。训练中的全连接层的dropout 比例是0.3,不是多数的0.5;采取带动量的梯度下降方法,batch-size = 12,学习率设为0.001,每30 epoch 缩小10 倍,总共训练90 个epochs。网络的对单张图片的测试速度非常快,达到0.15 秒/张,超过之前的state-of-the-art。
实验结果
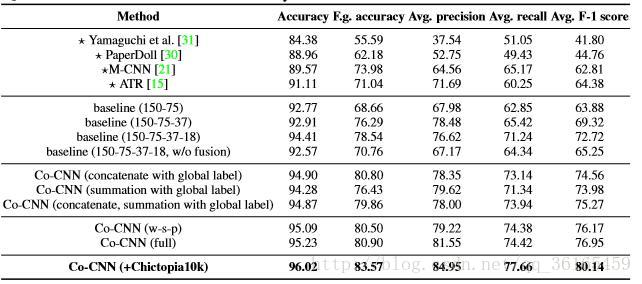
由以下这张表可以看出Co-CNN 的框架设计比之前的baseline 都有所提升,并且其后期的局部优化处理也有显著提升效果。其实从数据结果上可以看出,比较显著的提升还是加入了Chictopia 10K 数据集,因为模型是拟合数据集的,好的数据集才能让模型拟合的更好,足够的训练数据才能训练出理想的模型。

相关文章推荐
- 论文阅读笔记(一)——Deep Convolutional Neural Network with Independent
- 论文阅读:《Visual Tracking with Fully Convolutional Networks》ICCV 2015
- Human Action Recognition Using a Modified Convolutional Neural Network(经典文献阅读)
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
- 论文阅读(Weilin Huang——【arXiv2016】Accurate Text Localization in Natural Image with Cascaded Convolutional Text Network)
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 论文阅读ImageNet Classification with Deep Convolutional Neural Networks &Going Deeper with Convolutions
- 论文阅读笔记:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- 论文阅读(1)——ImageNet Classification with Deep Convolutional Neural Networks
- 论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
- Human Action Recognition Using a Modified Convolutional Neural Network(经典文献阅读)
- 论文阅读《Edge Detection Using Convolutional Neural Network》
- Heterogeneous Multi-task Learning for Human Pose Estimation with Deep Convolutional Neural Network
- 【论文阅读】TextBoxes: A Fast Text Detector with a Single Deep Neural Network
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- TextBoxes: A Fast Text Detector with a Single Deep Neural Network论文阅读
- 【论文笔记】Image Classification with Deep Convolutional Neural Network
- 《3D Convolutional Neural Networks for Human Action Recognition》论文阅读笔记
- 知识蒸馏(Distillation)相关论文阅读(1)——Distilling the Knowledge in a Neural Network(以及代码复现)
- 基于2-channel network的图片相似度判别_2015Learning to Compare Image Patches via Convolutional Neural Networks