论文阅读:Reading Text in the Wild with Convolutional Neural Networks
2016-08-27 21:41
941 查看
Preface
这篇 Paper: Reading Text in the Wild with Convolutional Neural Networks 产自大名鼎鼎的 VGG 实验室,发表在 IJCV 上。实验步骤分为两部分,基于 region proposal mechanism 的检测文字部分,以及基于 CNN 的文字识别部分。
在第一部分的 region proposal 部分,首先保证较高的 recall,尽量把所有可能的文字区域先检测出来;然后经过一个 filtering 阶段,保证文字检测的精度。
在第二部分的 word recognition 部分,不同于传统的一个字母,一个字母的识别文字,再组合成单词;本文采用 CNN 去一次性的识别出单词。
训练单词识别 CNN 网络时,所用的数据是人工生成的,并不需要人工去从自然场景的数据去标注,所以有大量的标注数据用于训练。
同时,我这篇文章重在这篇文章的理解,下一篇博文我会详细的记录、分析我对这篇文章的代码实现。并且目前,我个人只对思路实现到 Bounding Box Regression 部分。Word Recognition 部分,我还未实现。
Introduction
传统的文档识别 OCR 技术对于自然场景图像,并不管用。由于自然场景文字的外形、排列布局都十分多变;更甚的,自然场景文字的光照条件的差异、遮挡、文字排列方向的多样性、一些噪声,这些都会对文字检测识别造成巨大的干扰。所以传统的文档识别 OCR 技术对于自然场景图像中的文字识别毫无作用。一般的对于自然场景下的文字识别过程,分为两部分:文字区域的检测(detection)+文字区域的识别(recognition)。
这篇文章对于文字识别有较大的突破与贡献之一,即将整张图像读进 CNN 网络,直接一次性的完成文字识别过程,而不像原先的分割成单个的字母识别,再组合成单词。
因为这篇文章创新性的将文字的 recognition ,转变成为 classification 问题。只不过分类的类别数非常非常多,是一个个的单词,总共有 90K 个单词。
要完成这么多类别的分类所需要的样本数量是非常巨大的,所以文本采用的是人工生成训练数据。即将单词 粘贴 到场景图片上。
文本的另一点创新点在于:
进行文字区域的 proposal 检测时,所采用的方法是结合了 region proposal 以及 sliding window detector 。所以再第一步的 region proposal 的 recall 很高,在 ICDAR2003、Street View Text 数据集上均达到了 98% 的 recall;
之后再采用 random forest 分类器去过滤掉非文字的 proposal;
再经过一个创新性的 bounding box regression 过程,对刚刚过滤剩下的 proposal 进行 adjust,调整检测的窗口,使之尽可能的将文字区域框住。因为文字区域如果不是完整,残缺的,对于 recognition 过程将会极为的不利。想象一下一个只有半部分的文字区域的 proposal,送进 recognition 的 CNN 网络,基本很难识别(classification)正确。
文章在这部分还说,本文的另一个贡献在于,本文提出的方法可以在大规模的视频中进行文字的检索。不过这部分并不是本文的核心,先按下不讨论。
Overview of the Approach
这部分介绍了本文提出的方法的流程:word bounding box proposal generation
proposal filtering and adjustments
text recognition
具体的看方法的流程图:
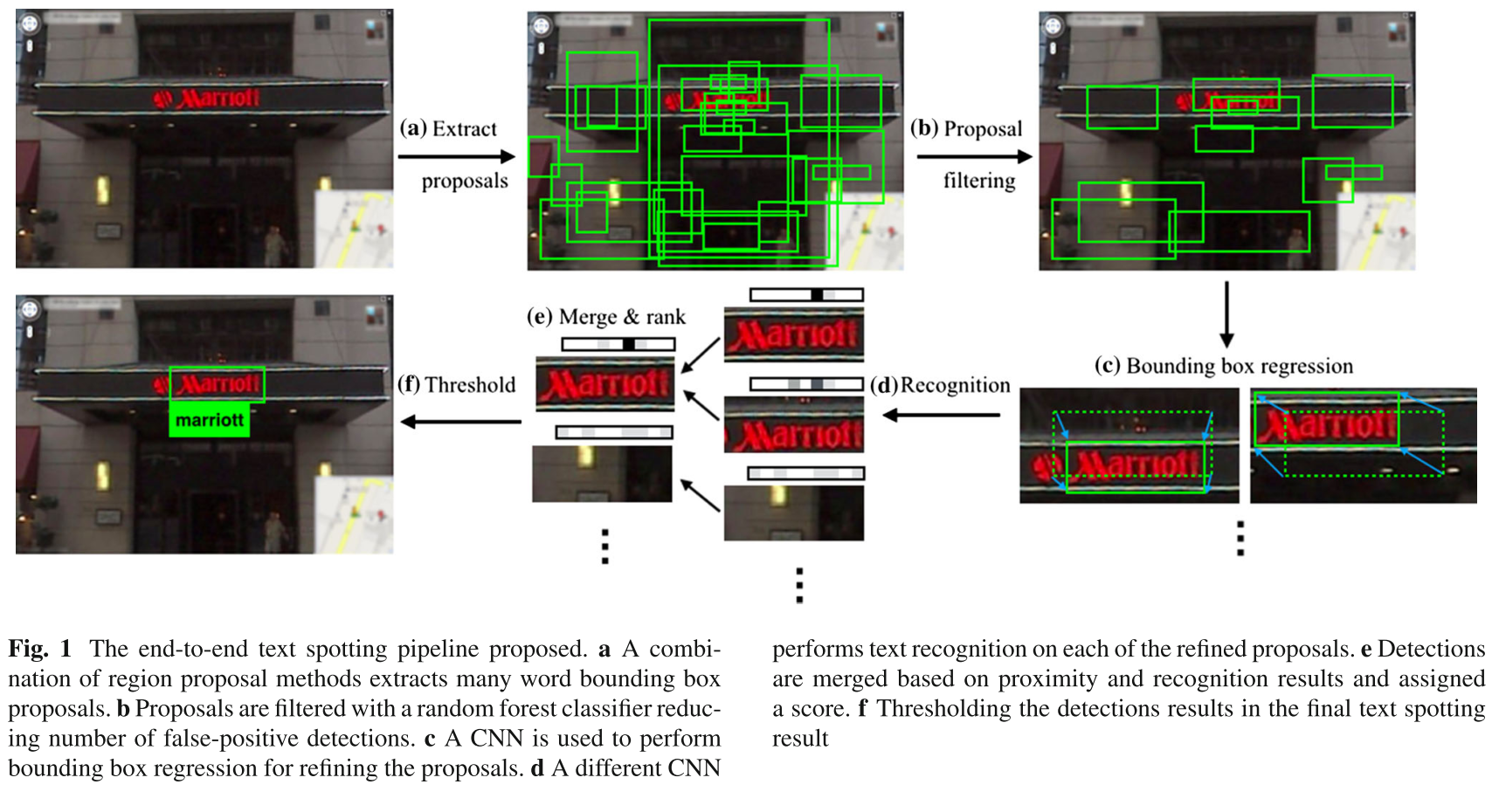
word bounding box proposal generation
更具体一点,在第一部分,先结合文献 Edge boxes: Locating object proposals from edges 提出的 Edge Box Proposal 的方法,以及文献 Fast Feature Pyramids for Object Detection 提出的 Aggregate channel features detector,先检测出大量的文字区域的 candidate word bounding boxes;下一步,由于上一步产生的 candidate word bounding boxes 有许多的错检测。因此,本文训练一个 random forest classifier 去过滤掉错检测的 proposals;同时,这样做也可以控制 bounding boxes 的数量。
proposal filtering and adjustments
再下一步,受到 DPM(Felzenszwalb et al. 2010)、R-CNN (Felzenszwalb et al. 2010) 中的 bounding box regression 的启发,文本通过 bounding box regression 来进一步的提高 region proposals 与 ground truth 之间的 overlap。这样在下一阶段的 word recognition 部分会提高准确率。text recognition
再下一步,即 word recognition 部分。即从上一阶段的 detection 产生的 proposals,去 recognition 出文字。在 recognition 时,采用的是直接将整个 region of the word 输入进 CNN 中,以分类的方式进行 recognition。
分类的类别超乎想象,90K 个单词的分类。这么多的类别,所需要的训练样本也是相当相当的多的;因此,本文采用的是 synthetic data,纯自动生成的数据,这样也解决了数据的 label 问题。
这一部分的最后,作者还提到,本文的 detection 与 recognition 部分并不是割裂开来的:在 word recognition 之后,还会根据 recognition 的信息,通过多轮的 non-maximal suppression 以及 bounding box regression 来 update detection 部分。
Proposal Generation
在检测出的 bounding boxes 中,如果这个 bounding box 与 ground truth 之间的 overlap 面积大于设定的阈值 threshold,则定义其为 true-positive detection。bounding box b1 与 bounding box b2 的 overlap 定义为 交除并(intersection over union, IoU):
IoU=|b1∩b2||b1∪b2|
尽管在本文之前,region proposal 还没有用于文字检测,但 region proposal 方法早已在物体检测方面大放异彩。
region proposal 方法产生较高的 recall 的结果,但同时也产生了 false-positive detections;相比于 sliding window 的方法,region proposal 方法也大大大的节省了检测时间。因此,region proposal 方法可以看作为一种 weak detector .
在本文的 proposal 检测阶段,本文使用了两种检测算法:
文献 Edge boxes: Locating object proposals from edges 提出的 Edge Box region proposal 的方法;
文献 Fast Feature Pyramids for Object Detection 提出的 Aggregate channel features detector 方法
Edge Boxes
Edge Boxes 的想法比较简单:The key intuition behind Edge Boxes is that since objects are generally self contained, the number of contours wholly enclosed by a bounding box is indicative of the likelihood of the box containing an object.
图像中的物体都是 self contained,那么一个 bounding box 中包含的这种完全自闭合的边界的数目,代表了这个 bounding box 包含物体的可能性。
这种 idea 用来检测文字是可行的,因为文字区域显然是 self contained(自闭合)。
本文用了文献 Structured Forests for Fast Edge Detection、Fast Edge Detection Using Structured Forests 提出的 Structured Edge detector 来检测得到 边缘响应图(Edge response map);同时,检测出来的 boxes 都带有一个 score:sb,代表了可能性的大小。
之后,进行了 Non-Maximal Supression(非极大值抑制) 去除交叉面积太大的 boxes:对上面的每一个 boxes 按 score 的大小排序,进行非极大值抑制。
这个结果为一集合: candidate bounding boxes Be 。
Aggregate Channel Feature Detector
本文同时也使用了传统的检测算法:Aggregate Channel Features(ACF)算法是传统的 sliding window 的检测方法,检测 ACF 特征,同时用一个 AdaBoost 分类器。
这部分的代码我没有调的通,也就不再深究了。总之,这部分的目的在于将 proposal 的方法与传统的方法相结合。求两种检测算法检测出的 bounding box 的并集(B={Be∪Bd}),使得最后的 bounding box 的 recall 尽可能的高。
本文中,这两种方法的结合,使得最后的 recall 达到了 98% 的水平。这样使得文字尽可能的被检测到,而不造成漏检。至于错检,在下一步的 filter stage 会被过滤掉。
Filtering and Refinement
这部分是对上一阶段的文字检测结果的精细化处理。上一阶段,得到 region proposal 的集合:candidate bounding boxes,B。这里面包含了许多 false-positive 的 bounding boxes,要将其过滤掉,并做 finement。这阶段的处理分为两部分:
一是过滤掉错检的 bounding boxes;
二是通过 bounding box regression 对过滤后剩下的 bounding boxes 进行调整,以使其尽量的更完整的包含文字区域,以便在 recognition 阶段正确识别单词。
Word Classification
那么怎么样过滤掉 false-positive 的 bounding boxes 呢?本文是先从自然场景图像中的文字区域(需要 fixed 到固定的大小),提取 HOG 特征;
再用 Random Forest 训练出一个分类器,这个分类器我是用 ICDAR2011 训练数据提供的 ground truth 作为正样本,自己再采集了 300 个负样本。
用这个分类器来过滤掉 false-positive 的 bounding boxes。
流程图如下:

最后得到正确的文字区域的 bounding boxes,Bf。这部分的详细 python 实现代码,我会在下一篇博文给出分析。
Bounding Box Regression
在检测到的 bounding box 中,有一些特殊情况,虽然其也满足与正确的文字区域之间的 overlap 大于等于 0.5 ,但却很难被识别出来。看下图:
上图中的情形下,虽然 IoU 也大于等于 0.5,但由于文字区域不完全,所以在 recognition 阶段很难被正确识别出来。
这是文字不同于一般的物体检测的地方,文字检测出的 bounding boxes 必须完整的覆盖住文字,都则很难被准确识别。
因此,这时候,受到 R-CNN 的 bounding box regression 的启发。本文通过训练一个 CNN 网络(regression framework)来调整 bounding boxes 的边界,使之尽可能的覆盖住文字区域。原理图如下:
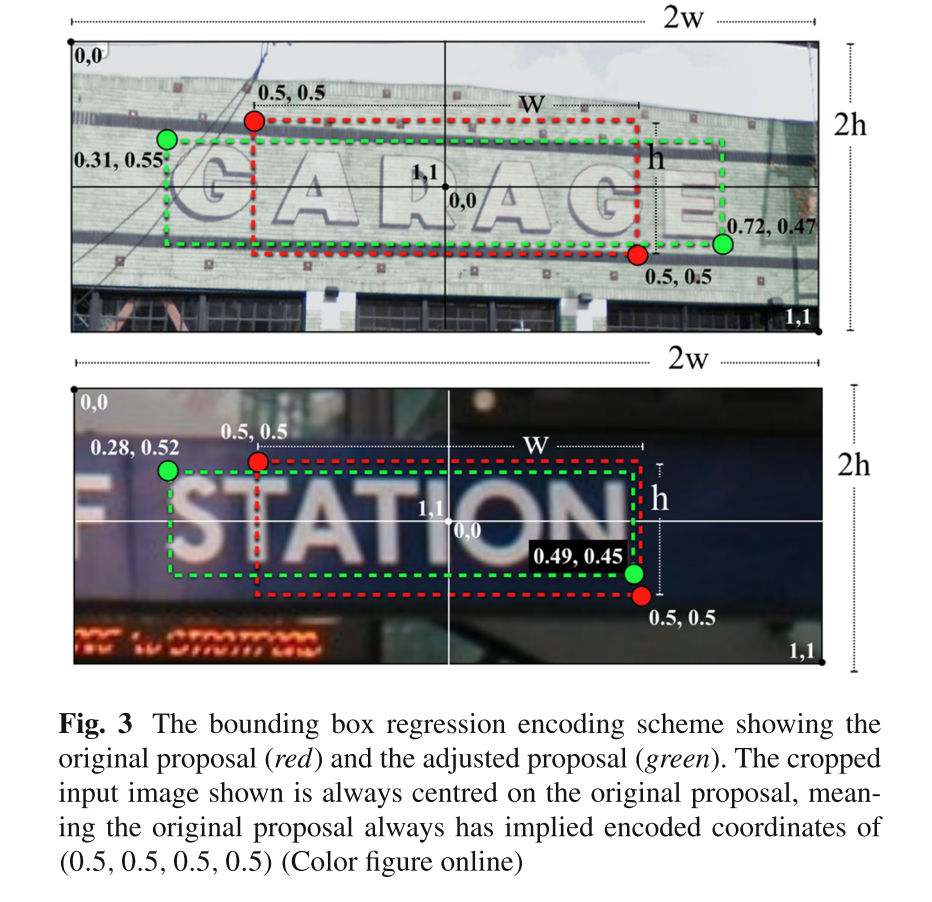
这个 bounding box regressor 输入的是 bounding box;同时,在 ICDAR2011 数据集中,训练数据中每张图像也给了每一个 groundtruth 的坐标以及内容。用左上角、右下角的坐标来表示:b=(x1,y1,x2,y2),如对于下面的一张训练图像:

其 groundtruth 文件内容为:

这里的 ground truth 数据 (x1,y1,x2,y2),将被作为训练这个 bounding box regression CNN 的 label。这个 CNN 网络的输入即为前面一系列处理之后剩下来的 bounding boxes(并已经做过了 width、height 方向上的 2 倍的拉伸,以及 fixed to 100×32 的大小)。
这个 CNN 网络的目的就是在于:通过输入的 bounding boxes,以及其 ground truth 的 label,训练这个网络,使得每个 bounding box 尽可能的 拉到 ground truth 的区域上。
Postscript
接着上面,这样的话,每个样本的 label 就不是一个纯量,而是 (x1,y1,x2,y2),对于这样的标签,其数据该如何组织,如何训练?我在下一篇博文会详细阐述。这篇博文重点在于文章的分析与理解。先到 word detection 这部分吧。

相关文章推荐
- 论文阅读:Reading Text in the Wild with Convolutional Neural Networks
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
- 深度学习论文笔记--Recover Canonical-View Faces in the Wild with Deep Neural Network
- 文本检测论文阅读-Object Proposals for Text Extraction in the WildSelective Search for Object Recoginition。
- 论文阅读ImageNet Classification with Deep Convolutional Neural Networks &Going Deeper with Convolutions
- 论文阅读(Weilin Huang——【arXiv2016】Accurate Text Localization in Natural Image with Cascaded Convolutional Text Network)
- 【论文笔记】Recover Canonical-View Faces in the Wild with Deep Neural Network
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
- 论文阅读(1)——ImageNet Classification with Deep Convolutional Neural Networks
- AlphaGo论文的译文,用深度神经网络和树搜索征服围棋:Mastering the game of Go with deep neural networks and tree search
- Deep learning论文笔记一:ImageNet Classification with Deep Convolutional Neural Networks
- 经典计算机视觉论文笔记——《ImageNet Classification with Deep Convolutional Neural Networks》
- [深度学习论文笔记][Image Classification] ImageNet Classification with Deep Convolutional Neural Networks
- 【论文笔记】Recursive Recurrent Nets with Attention Modeling for OCR in the Wild
- [深度学习论文笔记][Video Classification] Large-scale Video Classification with Convolutional Neural Networks
- 论文笔记 Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
- 论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
- Recurrent Convolutional Neural Networks for Text Classification阅读笔记
- 论文阅读:ICML 2016 Large-Margin Softmax Loss for Convolutional Neural Networks