Python爬虫系列(七):提高解析效率
2017-10-24 22:34
405 查看
如果仅仅因为想要查找文档中的<a>标签而将整片文档进行解析,实在是浪费内存和时间.最快的方法是从一开始就把<a>标签以外的东西都忽略掉. SoupStrainer 类可以定义文档的某段内容,这样搜索文档时就不必先解析整篇文档,只会解析在 SoupStrainer 中定义过的文档. 创建一个 SoupStrainer 对象并作为 parse_only 参数给 BeautifulSoup 的构造方法即可
from bs4 import BeautifulSoup, NavigableString
from bs4 import SoupStrainer
only_a_tags = SoupStrainer("a")
only_tags_with_id_link2 = SoupStrainer(id="link2")
def is_short_string(string):
return len(string) < 6
only_short_strings = SoupStrainer(text=is_short_string)
soup = BeautifulSoup(html_doc, "lxml")
print('1------------找到所有a元素')
print(BeautifulSoup(html_doc, "html.parser", parse_only=only_a_tags).prettify())
print('2------------找到id=link2的元素')
print(BeautifulSoup(html_doc, "html.parser", parse_only=only_tags_with_id_link2).prettify())
print('3------------找到元素长度小于10的元素')
print(BeautifulSoup(html_doc, "html.parser", parse_only=only_short_strings).prettify())
今天,我们的爬虫系列基础就算告一段落。这些,就是公司培训新手的教程。实际上,在项目的实际过程中,还有太多坑,知识库里面的东西后面逐步分享出来。
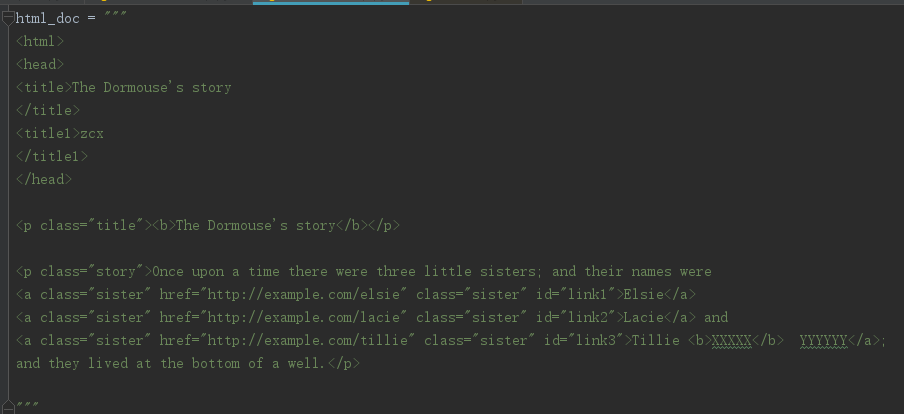
目标文档
from bs4 import BeautifulSoup, NavigableString
from bs4 import SoupStrainer
only_a_tags = SoupStrainer("a")
only_tags_with_id_link2 = SoupStrainer(id="link2")
def is_short_string(string):
return len(string) < 6
only_short_strings = SoupStrainer(text=is_short_string)
soup = BeautifulSoup(html_doc, "lxml")
print('1------------找到所有a元素')
print(BeautifulSoup(html_doc, "html.parser", parse_only=only_a_tags).prettify())
print('2------------找到id=link2的元素')
print(BeautifulSoup(html_doc, "html.parser", parse_only=only_tags_with_id_link2).prettify())
print('3------------找到元素长度小于10的元素')
print(BeautifulSoup(html_doc, "html.parser", parse_only=only_short_strings).prettify())
今天,我们的爬虫系列基础就算告一段落。这些,就是公司培训新手的教程。实际上,在项目的实际过程中,还有太多坑,知识库里面的东西后面逐步分享出来。
码字不易,期盼点赞

相关文章推荐
- Python爬虫系列(四):Beautiful Soup解析HTML之把HTML转成Python对象
- 【Python爬虫系列】内容解析之BeautifulSoup
- Python爬虫实战入门六:提高爬虫效率—并发爬取智联招聘
- python 爬虫系列教程方法总结及推荐
- python提高效率(优化)的心得总结(不断补充)
- Visual Studio 2008开发新特性系列课程(13):团队协作开发利器——VSTS2008如何提高团队开发效率
- Python爬虫请求与响应过程系列之二
- Python GIL 系列之通过设置进程运行的CPU来提高Python程序的性能(续)
- 有意思的python爬虫系列(beautifulSoup,urllib,selenium)
- 【Python爬虫系列】Python 爬取上海链家二手房数据
- 提高Python运行效率的六个窍门
- python中通过预先编译正则表达式提高效率
- Python爬虫之xlml解析库(全面了解)
- Python爬虫系列博客
- 教你用Type Hint提高Python程序开发效率
- day1:python学习爬虫抓取与解析:链家网案例
- Python爬虫Selenium和PhantomJS系列之十三
- 【Python学习系列五】Python网络爬虫框架Scrapy环境搭建
- python 提高效率的几个小技巧
- 数据科学工程师面试宝典系列之一--Python爬虫实战