论文阅读:《Convolutional Pose Machines》CVPR 2016
2017-10-23 17:25
441 查看
概述
本文使用CNN进行人体姿态估计,它的主要贡献在于使用顺序化的卷积架构来表达空间信息和纹理信息。顺序化的卷积架构表现在网络分为多个阶段,每一个阶段都有监督训练的部分。前面的阶段使用原始图片作为输入,后面阶段使用之前阶段的特征图作为输入,主要是为了融合空间信息,纹理信息和中心约束。另外,对同一个卷积架构同时使用多个尺度处理输入的特征和响应,既能保证精度,又考虑了各部件之间的远近距离关系。网络结构以及流程
算法流程:1. 计算各个尺度下,各部件的相应图
2. 对于每一个部件,累加所有尺度的相应图,得到总的响应图
3. 在各部件的总响应图下,找到相应的最大点,即为该部件的位置所在
网络结构:
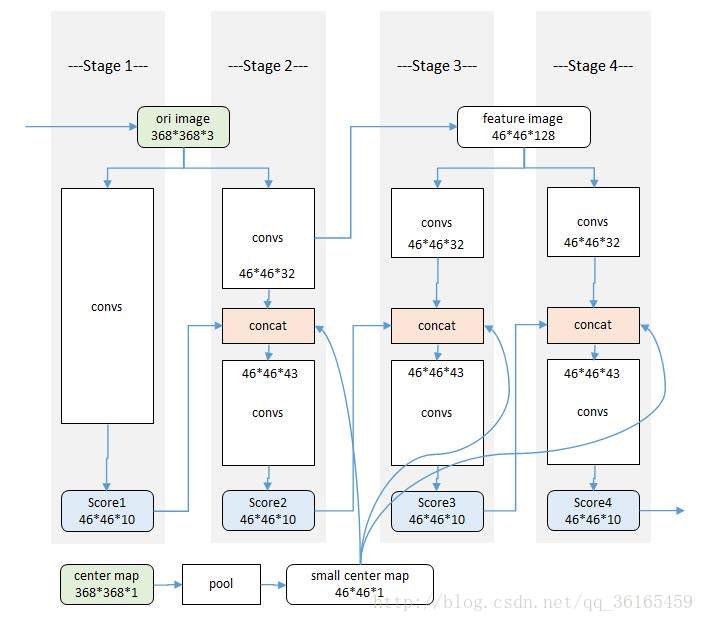
这是检测半身部件的顺序化卷积架构,其部件一共是9个(不包括背景)。绿色的ori部分是原始输入图片,绿色的center map部分是一个高斯函数模版,用于将响应归一到中心部分。白色的convs是相同的卷积架构部分。蓝色的score部分是经过卷积层的相应图,即空间信息。橙色的concat部分是串联结构,用于融合卷积层的中间结果,上一阶段的响应图以及高斯模版生成的中心约束。
具体的各个阶段的构造如下:
Stage1:原始图片经过卷积层,得到初始响应图。卷积层的结构如下:
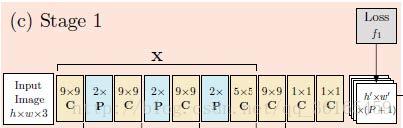
即7层卷积,3层池化层,原始输入图片是368*368,经过3次池化得到46*46大小。又因为是半身结构,只有9个关节点,加上背景1,因此输出的响应图大小是46*46*10。
Stage2:输入也是原始图片,但是在卷积层的中段,加入一个串联的结构,用来融合三部分
4000
的信息——一是stage1的响应图,二是阶段性卷积结果,三是高斯模版生成的中心约束。这里比较巧妙的是,串联后的结果尺度不变,深度变为10+32+1 = 43。
Stage3:输入的不再是原始图片,而是stage2的阶段性卷积结果,即中间层特征图。之后的结构和stage2是一样。至于stage4也和stage3结构一样。
训练细节
1. 数据增强:对原始图片进行随机缩放,旋转,镜像2. 标定:在每个关节点的位置放置一个高斯响应,来构造响应图的真值。对于含有多个人的图像,生成两种真值响应,一是在每个人的相应关节位置,放置高斯响应。二是只在标定的人的相应关节位置,放置高斯响应。
3. 中继监督,多个loss:如果直接对整个网络进行梯度下降,则输出层在经过多层反向传播会大幅度的减小,解决方法就是在每个阶段都输出一个loss,可保证底层参数正常更新。
开源实现
https://github.com/shihenw/convolutional-pose-machines-release(caffe版本)https://github.com/psycharo/cpm (tensorflow版本,但是只有用pre-trained model做predict,没有training)
Reference:http://blog.csdn.net/shenxiaolu1984/article/details/51094959

相关文章推荐
- convolutional pose machines, CVPR 2016
- 论文阅读:《Structured Feature Learning for Pose Estimation》CVPR 2016
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
- Convolutional Pose Machines 阅读小结
- 【论文阅读笔记】CVPR2015-Long-term Recurrent Convolutional Networks for Visual Recognition and Description
- 论文阅读:《Stacked Hourglass Networks for Human Pose Estimation》ECCV 2016
- 论文阅读:CVPR2016 Paper list
- 论文阅读:Pose Machines: Articulated Pose Estimation via Inference Machines
- 论文阅读:ICML 2016 Large-Margin Softmax Loss for Convolutional Neural Networks
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
- 论文阅读:CVPR2016 Paper list
- 论文阅读:《Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields》CVPR 2017
- 论文阅读笔记: 2017 cvpr Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
- 论文阅读:《Towards accurate multi-person pose estimation in the wild》CVPR 2017
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
- 论文阅读: ECCV2016 Chained Predictions Using Convolutional Neural Networks
- 【论文阅读】Convolutional Pose Machine
- 论文阅读 Multi-Scale Structure-Aware Network for Human Pose Estimation
- 论文阅读(Weilin Huang——【arXiv2016】Accurate Text Localization in Natural Image with Cascaded Convolutional Text Network)
- CVPR 2016|商汤科技论文解析:人脸检测中级联卷积神经网络的联合训练