人工智能第一次作业
2017-10-22 16:35
113 查看
第一章
1.1:
(a)智能:
智能为智慧的人,它能够仅仅以少量的物质,却能感知,理解,预测和操纵一个远大于自身且复杂的多的世界。
(b)人工智能:
能够像人一样思考,能够合理地思考,能够像人一样行动,能够合理地行动。
(c)Agent:
Agent就是能够行动的某种东西,它可以比普通计算机程序做更多的事情:自主的操作,感知环境,长期
持续,适应变化并能创建和追求目标。
(d)理性:
我们将理性定义为一个系统的属性,它做了“正确的事情”,它知道该做什么。
(e)逻辑推理:
我们将逻辑推理定义为从旧的句子中衍生出新的句子,如果旧的句子是真的,那么新的句子一定是正确的。
1.3 :
理性?
它是一种理性的行为,因为如果不缩回自己的手会对手造成伤害,因此缩回自己的手是一种理性的行为。
智能?
反射行动是一种动物的本能。它不需要经过思考也不需要学习,在某些情况下它不能算是一种智能。
1.11 :
当我们写了一个普通的计算机程序时,计算机只能做我们告诉它们的。比如你写了一个简单的计算器程序,那么计算机只能执行我们已经写好的计算规则;当我们写了一个使用机器学习方法的程序时,比如我们写了一个垃圾邮件分类程序,那么我们要告诉它们的就是让它们正确地去将邮件分类,但是我们并没有给它们具体的规则,而是让它们自己学习,从某种程度上说,我们认为它们是智能的,因为它们可以自我学习,我们并没有告诉它们具体的规则,但是它们做的事却又是程序员事先告诉它们的-正确分类邮件。从某种程度上说,计算机只能做程序员告诉它们的,但是我们可以认为它们是智能的。
1.15 :
DARPA挑战赛机器人汽车:
美国国防部高级研究计划局(DARPA)在2004年对机器人汽车发起了大挑战,最大的挑战是240千米赛跑穿过莫哈维沙漠。最好的团队,CMU,只完成了12公里。在2005年的比赛中,五支队伍完成了,斯坦福得到了第一名。这被誉为机器人技术的伟大成就的挑战。2007年,城市挑战赛把汽车放在城市里,他们必须遵守交通规则,避开其他车辆。这一次,CMU击败了斯坦福,这似乎是一个把理论付诸实践的很好的试验场。
国际规划比赛:
1998年,五个计划者:Blackbox,HSP,IPP,SGP,和STAN。声明“所有的计划者都执行了很好”,与几年前的状况相比。大多数计划都是30步或40步,有超过100步。2008年,竞争扩大了不少。有大约25名计划者。总之,这个领域在参与、广度和力量方面都有了很大的进步。
Robocup 机器人足球赛:
事实证明,这种竞争非常受欢迎,2009年来自43个国家的407支球队(1997年来自11个国家的38支球队)。
机器人平台已经发展到一个更有能力的人形形态,以及战略战术也在进步。尽管竞争已经刺激了在分布式控制中的创新,近年来获胜的团队更多地依赖于个人控球能力,而不是高级团队合作。竞争加剧了兴趣和参与机器人技术。
TREC信息检索比赛:
这是最古老的比赛之一,开始于1992年。这些竞赛使一个社区的研究人员聚在一起,已经导致了大量的出版物文献,并看到了参与的进展。在最初的几年里,TREC服务过它的目的是作为在文本集合上对检索算法进行评估的地方当时规模很大。然而,从2000年开始,TREC变得不那么重要了,万维网的出现创造了一个人人都可以使用的语料库而且比TREC创造的任何东西都要大得多。
语言识别比赛:
这一系列的评估自2001年以来,没有贴上“竞争”的标签。从那时起,我们就看到了伟大的提高了机器翻译质量和语言的覆盖范围。7个占主导地位的方法从一种语法规则转变为一种语法规则主要依赖于统计数据。NIST的评估似乎很好地跟踪这些变化,但似乎并没有推动这些变化。
总结:
我们看到,无论你采取什么措施都必然会随着时间的推移而增加。这些比赛大部分时间里,测量是有用的。在ICAPS的案例中,一些计划研究人员担心过于关注在比赛本身上挥霍。在某些情况下,进步已经落后于竞争对手,和TREC一样,商业搜索引擎的资源超过了这些用于学术研究人员。在这种情况下,TREC的竞争是有用的,帮助了训练许多最终在商业搜索引擎中工作的人,并没有被吸引能量而远离新思想。
第二章
2.4(1-4):
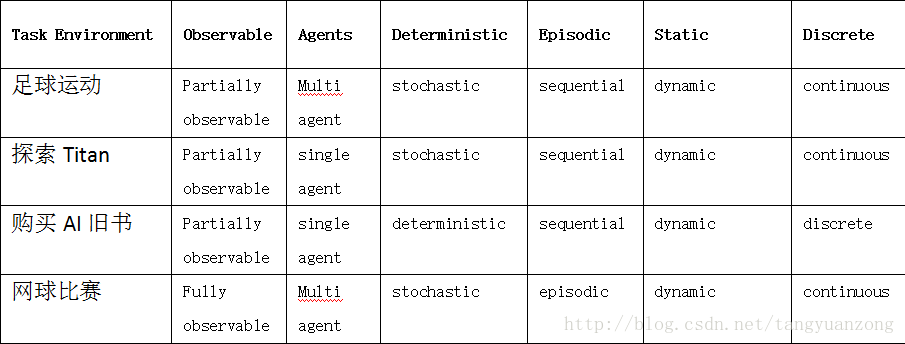
2.9 :
(defun reflex-rational-vacuum-agent (percept)
(destructuring-bind (location status) percept
(cond ((eq status ’Dirty) ’Suck)
((eq location ’A) ’Right)
(t ’Left))))
性能评分为 1999, 1998, 1998, 2001
2.11 :
a: 不是完美理性:
简单反射agent不能记录历史状态信息,只能根据当前感知信息作出决策,这样就容易陷入一种无限循环中,除非我们可以将agent的行动随机化,可以避免无限循环。而完美是指实际的性能最大化,理性是指期望的性能最大化,由于可能会出现无限循环的情况,因此就不能使得性能最大化,所以就不是完美理性的。
b: 使用随机Agent函数的简单反射Agent
(defun randomized-reflex-vacuum-agent (percept)
(destructuring-bind (location status) percept
(cond ((eq status ’Dirty) ’Suck)
(t (random-element ’(Left Right Up Down))))))
两种Agent在一般情况时性能上差不多,当遇到一些特殊情况,比如陷入无限循环,使用随机函数的Agent性能更好。
c:环境
性能比简单反射Agent要差
d:
有内部状态的Agent会优于简单反射Agent。简单反射Agent具有极好的简洁性,但是它们的智能也有限,由于只根据当前的感知信息作出决策,很有可能作出错误的决策。而具有内部状态的Agent,可以根据感知历史维持内部状态。这样有利于作出更理性的决策。
第三章
3.3 :
a:形式化:
状态:所有可能的城市pair(i,j),表示第一位在城市i,第二位在城市j。
初始状态:任何状态都可能是初始状态。
目标测试:检测两个朋友是否到达同一个城市。即达到状态(i,i)。
路径耗散函数:每一次的耗费为max(d(i1,j1),d(i2,j2)),总耗费为每一次的耗费总和。
后继函数:假如当前状态为(i,j),第一位前进到x,第二位前进到y,则下一状态为(x,y)。
b: 选择第三个D(i,j)/2
因为在最理想的情况下,两个人都走过相同的步长D1(i,j)/2,则会减少2倍的距离,即D1(i,j)。
c:存在
假如该图只有2个节点,却只有一条边,那么它们只会交换彼此位置,不能到达同一位置。
d:存在
假如该图只有2个节点,然后在其中一个点上添加一条自旋边。这样该点就会被访问2次。
3.4 :
证明:
首先我们定义整数N,N=空方格所在的行号+状态中所有的逆序数。比如下图:
初始状态的N=2(行号)+3(<7,2>,<8,3>,<3,1>)=5,
目标状态的N=1(行号)+0=1。
我们发现目标状态和初始状态的N%2的值是不变的,即初始状态的N是奇数,那么不管如何变化,N都是奇数。因此我们可以把八数码的所有状态划分为2个状态。即N为奇数和N为偶数。因为N在滑块移动的过程中保持不变,所以处于同一子集中的状态之间可以互相到达,处在不同状态之间必不可达。
算法:
求出一个给定状态的N的值,判断N为奇数还是偶数来判断它属于哪个集合。
求出目标状态的N的值,然后在生成随机状态时,先求出随机状态的N的值,然后判断和目标状态是否属于同一集合,如果不是同一状态就可以舍弃,因为是肯定不可能存在解得。所以可以避免无用的求解。
3.9 :
a:形式化:
初始状态:六个人都在河的另外一边。
目标测试:是否六个人都在河的另外一边。
路径耗散函数:当前状态下船从一侧到另外一侧的代价为1个单位
所有合法状态:
(3,3,1/0),(3,2,1/0),(3,1,1/0),(3,0,1/0),(3,0,1/0),
(2,2,1/0),(1,1,1/0),(0,3,1/0),(0,2,1/0),(0,0,1/0)
第一元素表示在河的左岸的传教士,第二个元素表示在河的左岸的野人数目,第三个元素为1表示在左岸,为0表示在右岸。
状态转换图:
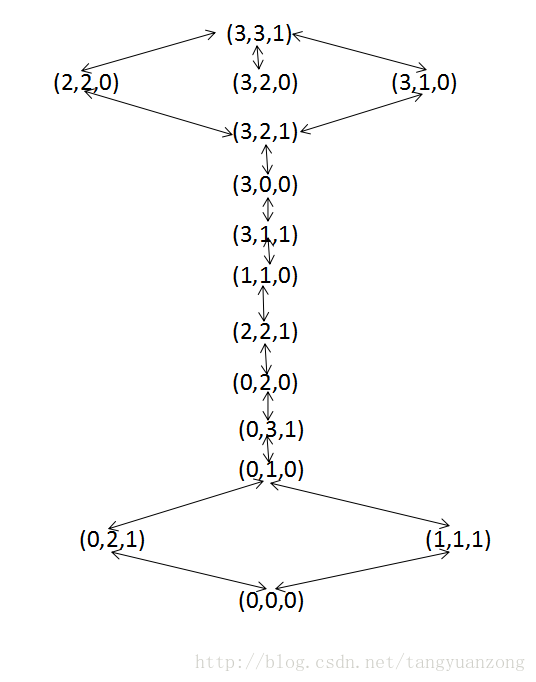
b: 采用深搜,广搜都可以,重复状态检测是个好主意,因为可以避免陷入无限状态。
c:状态空间是比较简单,但是重复状态检测比较麻烦,同时选取下一个状态,以及需要回溯时都比较困难。
3.21 :
a: 证明:
宽度优先搜索通过组织成FIFO队列来实现,按节点加入队列的先后顺序来扩展。而一
bd3d
致代价搜索每次扩展的都是路径消耗g(n)最小的节点n。当所有节点的g(n)=depth(n)时,即所有处于同一层的节点具有相同的路径耗费,这样每次扩展就是按节点加入队列的先后顺序来扩展。
b: 证明:
宽度优先搜索每次扩展节点集中最深的节点。最佳优先搜索每次扩展f(n)最小的节点。当所有节点的f(n)=depth(n)时,深度优先搜索成为最佳优先搜索的一种特殊情况。
c:证明:
A*搜索每次选择f(n)最小的节点进行扩展,其中f(n)=g(n)+h(n),而一致代价搜索每次都是选择g(n)最小的节点进行扩展,所以当h(n)=0时,f(n)=g(n),即一致代价搜索成为A*搜索算法的一种特殊情况。
3.29:
证明:
可采纳性是指它从不会过高的估计到达目标的代价。
而一致性可以等效为三角不等式h(n) ≤ c(n, a, n′) + h(n′)。
所以如果启发式是一致性的话,那么每次选择的h(n)都是最小的,因为三角形中任何一条边的长度不大于另外2条边之和。这样使得总代价是最小的,即它是到达目标的代价下界。所以实际的代价只会大于等于估计代价,这样就会满足启发式的可采纳性–它从不会过高的估计到达目标的代价。
构造:
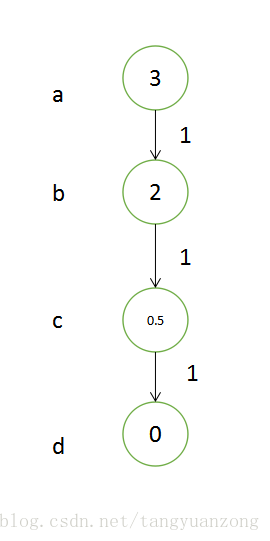
在上图中 h(b)=2 h(c)=0.2 h(b)>h(c)+1 ,所以是一个非一致的可采纳启发式。
