Pandas groupby apply agg 区别 运行自定义函数
2017-10-15 23:09
501 查看
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量。
对一列使用三个函数:
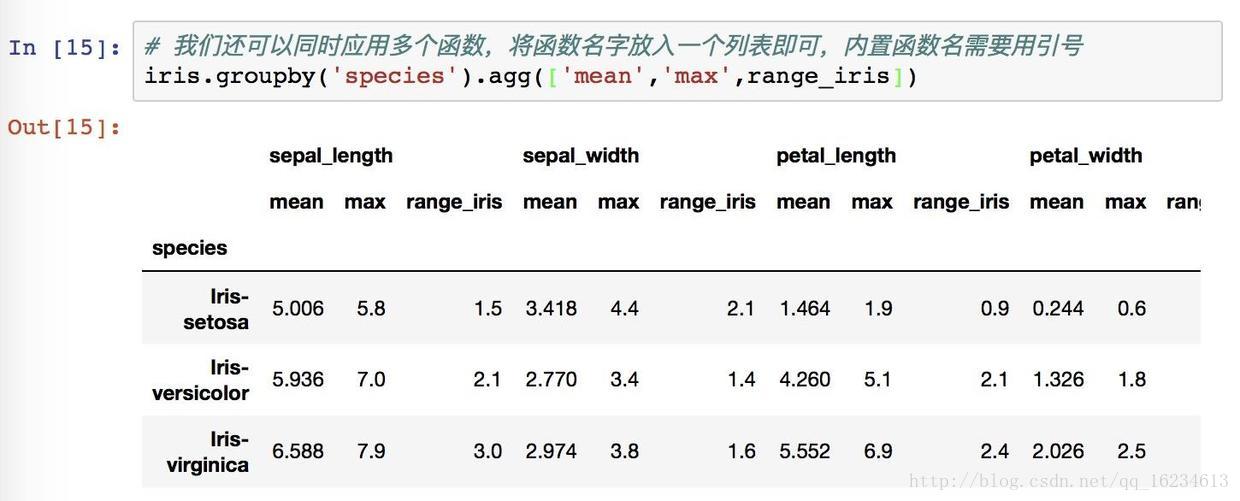
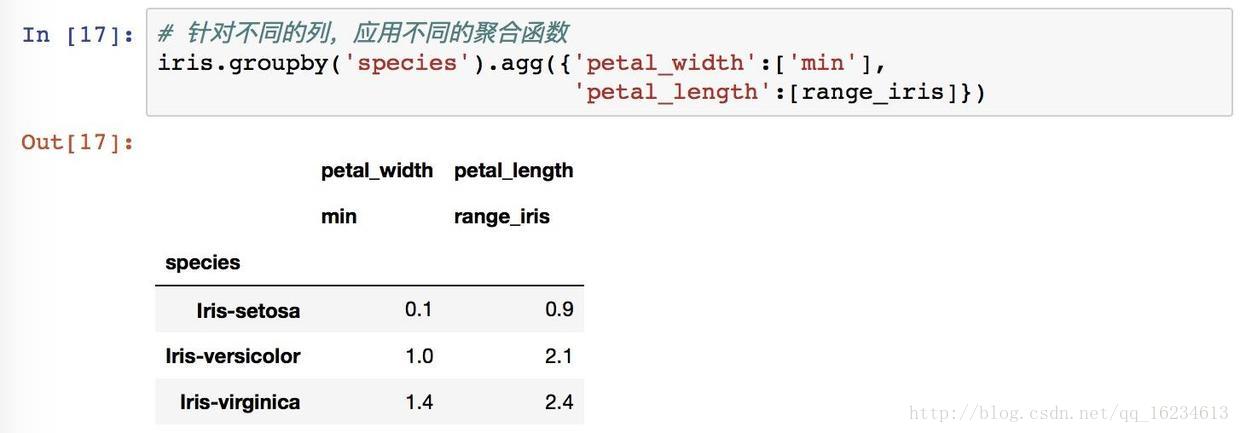
对不同列使用不同函数
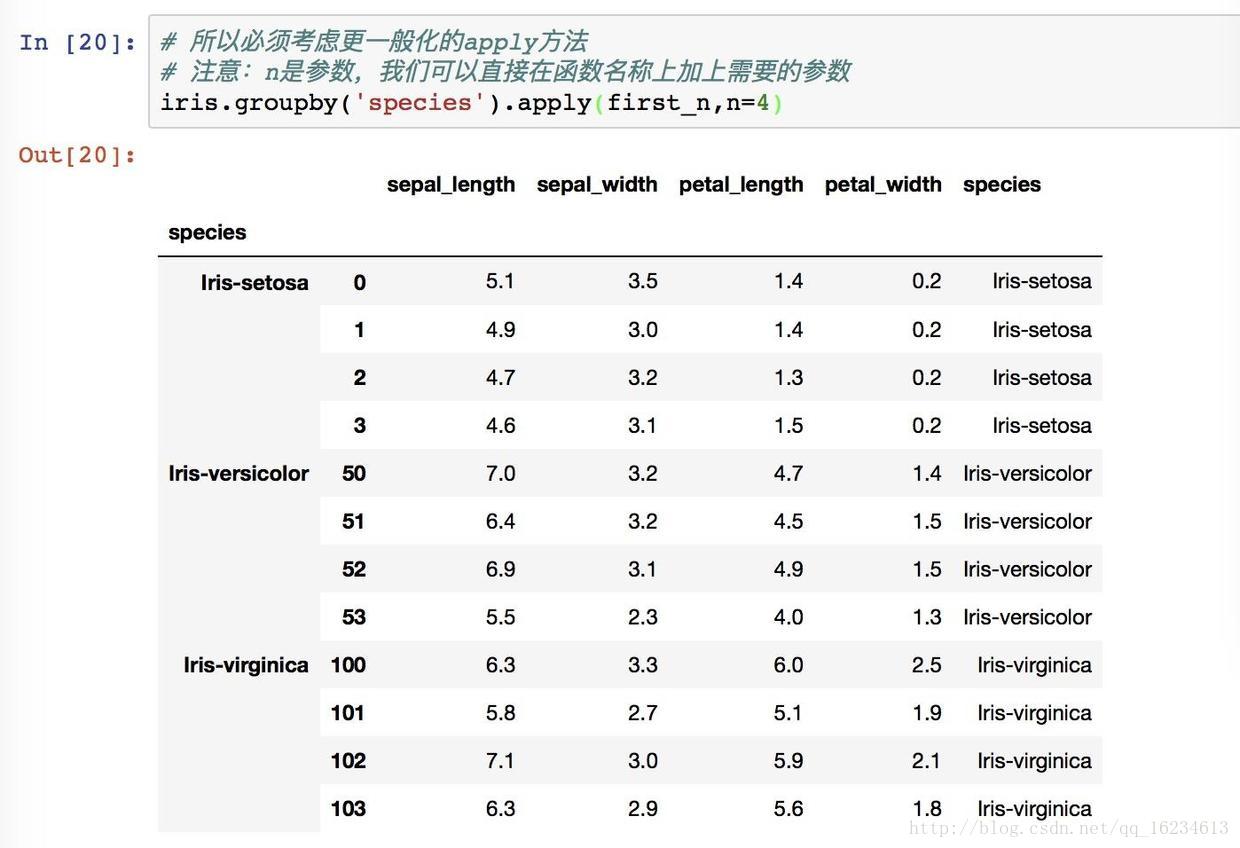
apply 是一个更一般化的方法:将一个数据分拆-应用-汇总。而apply会将当前分组后的数据一起传入,可以返回多维数据。
图片来自
实例:
1、数据如下:
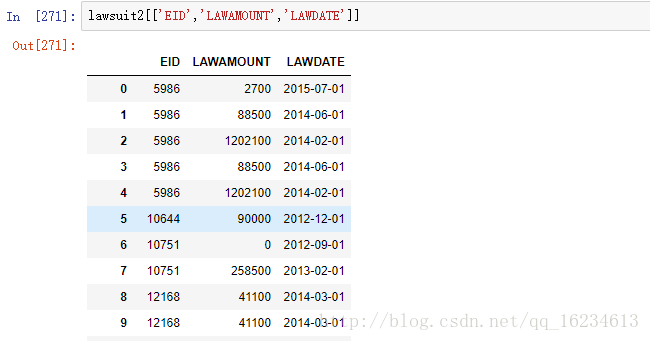
2、groupby后应用apply传入函数数据如下:
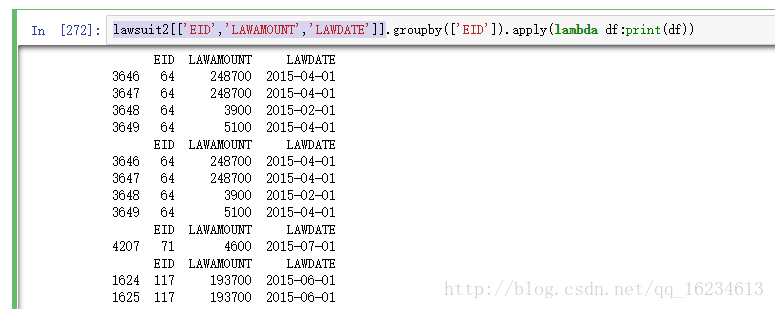
3、如果使用agg,对于两列可以处理,但对于上面的三列,打印数据如下:

可以看到agg传入的只有一列数据,如果我们使用df加列下表强行取值也能取到,但是有时会出现各种keyError问题。
4、完整代码:
判断最近一次日期的花费是否是所有的花费中最大花费。
对一列使用三个函数:
对不同列使用不同函数
apply 是一个更一般化的方法:将一个数据分拆-应用-汇总。而apply会将当前分组后的数据一起传入,可以返回多维数据。
图片来自
实例:
1、数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']]
2、groupby后应用apply传入函数数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).apply(lambda df:print(df))
3、如果使用agg,对于两列可以处理,但对于上面的三列,打印数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).agg(lambda df:print(df))
可以看到agg传入的只有一列数据,如果我们使用df加列下表强行取值也能取到,但是有时会出现各种keyError问题。
4、完整代码:
判断最近一次日期的花费是否是所有的花费中最大花费。
def handle(df): # print(df) # 找最大日期 maxdate = df['LAWDATE'].max() # 找最大费用 left = df[ df['LAWDATE']==maxdate ]['LAWAMOUNT'].max() # 取ID EID = df['EID'].values[0] # print(EID) # 从已存在的表中根据EID找到最大费用 right = LAW_AMOUNT_MAX.loc[EID,'LAW_AMOUNT_MAX'] # 判断费用是否相等 if left==right: return 1 else: return 0 LAW_AMOUNT_MAX_IS_LAST = lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).apply(handle)

相关文章推荐
- pandas函数应用篇之GroupBy.apply
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- SQL Server BUG集之"自定义函数与group by"
- Groupby shift apply 测试 计算每小时 各站的出入人数
- 【Spark系列2】reduceByKey和groupByKey区别与用法
- 函数返回值为自定义的类型与引用类型的区别
- oracle group by ,count,sum 函数 日常使用小知识
- SQL SUM() 函数、SQL GROUP BY 语句、SQL HAVING 子句
- 存储过程和自定义函数的区别
- LINQ Group by 多列值在C#与VB.Net上写法的区别