[翻译]机器学习如何个性化推荐音乐
2017-10-13 07:14
609 查看
本文翻译自链接,感兴趣的朋友可以去查看原文。
我是Spltify的铁杆粉丝,尤其是每周推荐(Discover Weekly)。为什么呢?它让我感觉到它比生活中的任何一个人都更知道我的音乐偏好,并且Spotify每周的推荐都会让我惊喜它,因为推荐给我的都是我从没发现的曲目或者推荐给我的都是我喜欢的。
下面让我介绍下我的最好的虚拟朋友:
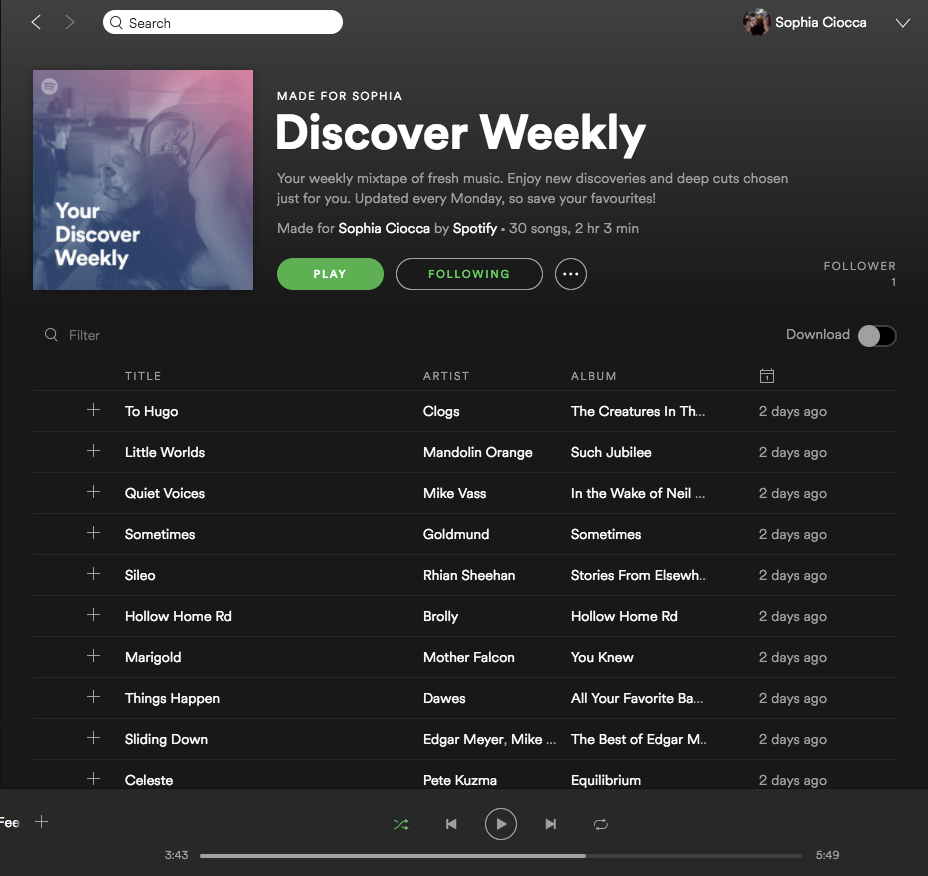
A Spotify Discover Weekly playlist — specifically, mine.
正如上图展示的,不仅仅是我深陷“每周推荐”,Spotify的用户都疯狂了,甚至于让Spotify重新考虑关注并投入更多的资源到基于算法的个性化推荐。

“每周推荐”最早追溯到2015年,我那时候还不知道它是如何工作的(我仅仅是这个公司的女粉丝,偶尔假装在那里工作并调研他们公司的产品)。经过了3周的谷歌搜索,我认为我最终得以瞥见“每周推荐”背后技术的冰山一角。
所以,Spotify是如何做到每周为每个用户推荐30首歌曲的呢?在这之前,首先让我们看看别的音乐服务商是如何做音乐推荐的吧,然后我们再介绍Spotify是如何做到更好的。

回到20世纪,Songza开启了在线音乐服务先河,那时候都是手动的为用户创建播放列表。通过组建一些音乐专家将一些听起来好听的类似歌曲手动的放在一起,然后听众只能听音乐专家们创建的播放列表。(之后,Beats Music也采用同样的策略。)人工创建播放歌单虽然效果也还行,但是比较简单以及需要依赖大量的手工操作。另外,人工创建播放歌单没有考虑到个人在音乐上的个性化偏好。
Pandora跟Songza一样,也是在线音乐服务的先驱之一,但是用的是一些更高级的方法:手动的为每一首歌打上属性标签。这个方法设想的是喜欢同一类音乐的用户会使用相同的描述歌曲的词汇去搜索,而Pandora根据这些词汇给歌曲打标签。之后,就可以很简单的根据某些标签进行过滤,将类似的歌曲放在一个歌单。
于此同时,MIT多媒体实验室的一个音乐智能机构–The Echo Nest诞生了。The Echo Nest使用的是更高级的方法进行个性化推荐,他们使用算法分析音乐的音频和文本内容,并基于此进行听曲识歌、个性化推荐、创建歌单以及分析。
最后介绍的是Last.fm使用的另一个不同的方法:协同过滤(collaborative filtering),这个方法至今依然在使用,这个方法用户辨别用户是否会喜欢这首音乐。
上面介绍了别的在线音乐服务商是如何进行音乐推荐的,Spotify是如何赶上并超越别的服务商,并且能将用户的喜好抓的死死的呢?
“每周推荐”采用了3种主要的推荐模型:
协同过滤模型( Last.fm最早使用的),用于分析不同用户之间的行为。
NLP模型,用户分析文本
音频模型,用于分析原始的音频

Image credit: Chris Johnson, Spotify
让我们深入的探索每一个推荐模块是如何工作的。

看到“协同过滤”,很多人会想到Netflix。Netflix是第一家使用协同过滤模型的公司,他们使用基于用户评分的电影排序来将电影推荐给其他类似的用户。
Netflix成功的使用该模型之后,这个模型的应用迅速推广,现在已经成为构建推荐模型最开始考虑使用的方法了。
跟Netflix不同,Spotify不需要用户对音乐进行评分。取而代之的是,Spotify使用的隐藏反馈策略,通过跟踪用户是否保存到用户播放歌单或者听了之后是否浏览艺术家的主页。
但是,什么是协同过滤呢,它是如何工作的呢?

图中的两个人都有自己的偏好,左边的人喜欢歌曲P、Q、R、S,右边的人喜欢歌曲Q、R、S、T。
协同过滤使用的就是他们的偏好数据。首先他们共同偏好歌曲Q、R、S所以他们很有可能是同一类用户。因此可以得出:他们相互都会喜欢对方的歌单,因而可以给一方推荐给另一方的歌单上的歌曲。比如给右边的人推荐T,给左边的人推荐P。
那么Spotify是如何做的呢?

如上图所示,所有的Spotify用户的偏好数据都在上图的矩阵中,一行代表一个用户的歌单,列代表的是歌曲曲目。
在得到上面的矩阵之后,使用下面的公式进行因式分解:

分解完毕之后可以得到2个向量,X代表用户向量,表征用户的音乐偏好;Y代表歌曲向量,表征一首歌。

经过计算之后得到了1.4亿的用户向量以及3千万的歌曲向量。这些向量本身是毫无意义的,但是对于推荐的时候进行对比却具有很大的帮助。比如为了寻找最类似的用户,比如寻找两首最类似的歌。

NLP处理的是非结构化文本,比如博客、网页、新闻等等。NLP用于理解人类的自然语言。
Spotify的做法是:爬取网上关于音乐的信息,并分析用户讨论的具体的艺术家或者歌曲内容,比如用的什么形容词或者哪些词用的最多。这里我并不知道Spotify具体是如何做的,但是可以分享一下我对 Echo Nest的理解。 Echo Nest通过对爬取的信息进行分析,得到“文化向量(cultural vectors)”和“高频短语(top terms)。每首歌每个艺术家都有上千个日常变化的高频短语。每一个短语都具有一个对应的权重,表明这个短语描述内容的重要程度(大致就是使用这个短语描述这首歌使用的词语的概率)。

然后,与协同过滤类似,NLP模型使用这些短语和权重得到了歌曲的向量表示,之后用于比较两首歌是否类似。
比方说:一个歌手将自己的新作长传到Spotify,但他可能之后50个听众,并且由于是新歌,所以网上基本没有关于这些新歌的资料。这个时候上述的协同过滤模型和NLP模型就失去作用了。然而语音模型并不会对新歌和流行歌曲区别对待,而是新歌依然可以出现在“每周推荐”的流行榜上。
语音模型是如何做到的呢?但按就是使用到了CNN(卷积神经网络)。
CNN也用于人脸识别。Spotify只是将人脸识别中的像素替换成音乐的音频。下面是一个神经网络架构的示例:

图中的神经网络拥有4个卷积层(左边的4个大方框)和3个密集层(3个带箭头的长框)。网络的输入是时频表示的音轨,用于形成歌曲的频谱。
音轨通过卷积层之后,可以看到“全局池化层”,这一层贯穿了整个时间轴,有效的学习到歌曲在时间上特征的统计信息。
经过处理之后,神经网络分理出了对于歌曲的理解,包括时间签名、关键词、模式、时序和响度。下图是Daft Punk的 “Around the World”的30秒波形分析图。

最终,通过对歌曲的关键特性进行分析,得到了歌曲之间的本质上的相似性。因而用户能够得到基于他们历史歌单的精准推荐。

当然啦,这些推荐模型都连接到了Spotify更大的生态上去,这个生态系统包含了大量的数据存储设备以及使用Hadopp集群,这些模型处理庞大的矩阵、无边无际的互联网音乐文本和海量的音频文件。
希望本文能够激起你对推荐系统的好奇心,现在我正在构建我自己的每周推荐,寻找我喜欢的音乐,探索背后使用到的机器学习技术。
[1]Spotify是一个起源于瑞典的音乐流服务,是全球最大的流音乐服务商,提供包括Sony Music、EMI、Warner Music Group和Universal四大唱片公司及众多独立厂牌所授权、由数字版权管理保护的音乐,使用用户在2017年6月已经达到1.4亿以上.
Collaborative Filtering at Spotify (Erik Bernhardsson, ex-Spotify)
Recommending music on Spotify with deep learning (Sander Dieleman)
How music recommendation works — and doesn’t work (Brian Whitman, co-founder of The Echo Nest)
Ever Wonder How Spotify Discover Weekly Works? Data Science (Galvanize)
The magic that makes Spotify’s Discover Weekly playlists so damn good (Quartz)
The Echo Nest’s Analyzer Documentation
个人公众号:

Spotify[1]的每周推荐:机器学习如何为你推荐新音乐-个性化推荐后面的科学
本周三,确切的说是每周三,超过1亿的Spotify用户都可以看到一个新的播放列表。这个播放列表包含了30首个性化混音曲目,这些曲目是用户从来没有听过的但很可能会喜欢。上述推荐叫做:每周推荐(Discover Weekly)。我是Spltify的铁杆粉丝,尤其是每周推荐(Discover Weekly)。为什么呢?它让我感觉到它比生活中的任何一个人都更知道我的音乐偏好,并且Spotify每周的推荐都会让我惊喜它,因为推荐给我的都是我从没发现的曲目或者推荐给我的都是我喜欢的。
下面让我介绍下我的最好的虚拟朋友:
A Spotify Discover Weekly playlist — specifically, mine.
正如上图展示的,不仅仅是我深陷“每周推荐”,Spotify的用户都疯狂了,甚至于让Spotify重新考虑关注并投入更多的资源到基于算法的个性化推荐。
“每周推荐”最早追溯到2015年,我那时候还不知道它是如何工作的(我仅仅是这个公司的女粉丝,偶尔假装在那里工作并调研他们公司的产品)。经过了3周的谷歌搜索,我认为我最终得以瞥见“每周推荐”背后技术的冰山一角。
所以,Spotify是如何做到每周为每个用户推荐30首歌曲的呢?在这之前,首先让我们看看别的音乐服务商是如何做音乐推荐的吧,然后我们再介绍Spotify是如何做到更好的。
在线音乐发展的历史梗概
回到20世纪,Songza开启了在线音乐服务先河,那时候都是手动的为用户创建播放列表。通过组建一些音乐专家将一些听起来好听的类似歌曲手动的放在一起,然后听众只能听音乐专家们创建的播放列表。(之后,Beats Music也采用同样的策略。)人工创建播放歌单虽然效果也还行,但是比较简单以及需要依赖大量的手工操作。另外,人工创建播放歌单没有考虑到个人在音乐上的个性化偏好。
Pandora跟Songza一样,也是在线音乐服务的先驱之一,但是用的是一些更高级的方法:手动的为每一首歌打上属性标签。这个方法设想的是喜欢同一类音乐的用户会使用相同的描述歌曲的词汇去搜索,而Pandora根据这些词汇给歌曲打标签。之后,就可以很简单的根据某些标签进行过滤,将类似的歌曲放在一个歌单。
于此同时,MIT多媒体实验室的一个音乐智能机构–The Echo Nest诞生了。The Echo Nest使用的是更高级的方法进行个性化推荐,他们使用算法分析音乐的音频和文本内容,并基于此进行听曲识歌、个性化推荐、创建歌单以及分析。
最后介绍的是Last.fm使用的另一个不同的方法:协同过滤(collaborative filtering),这个方法至今依然在使用,这个方法用户辨别用户是否会喜欢这首音乐。
上面介绍了别的在线音乐服务商是如何进行音乐推荐的,Spotify是如何赶上并超越别的服务商,并且能将用户的喜好抓的死死的呢?
Spotify的3种推荐模型
Spotify并没有发明一种革命性的推荐模型,而是混合多种最优策略打造了自己的强有力的推荐引擎。“每周推荐”采用了3种主要的推荐模型:
协同过滤模型( Last.fm最早使用的),用于分析不同用户之间的行为。
NLP模型,用户分析文本
音频模型,用于分析原始的音频
Image credit: Chris Johnson, Spotify
让我们深入的探索每一个推荐模块是如何工作的。
推荐模型1:协同过滤
看到“协同过滤”,很多人会想到Netflix。Netflix是第一家使用协同过滤模型的公司,他们使用基于用户评分的电影排序来将电影推荐给其他类似的用户。
Netflix成功的使用该模型之后,这个模型的应用迅速推广,现在已经成为构建推荐模型最开始考虑使用的方法了。
跟Netflix不同,Spotify不需要用户对音乐进行评分。取而代之的是,Spotify使用的隐藏反馈策略,通过跟踪用户是否保存到用户播放歌单或者听了之后是否浏览艺术家的主页。
但是,什么是协同过滤呢,它是如何工作的呢?
图中的两个人都有自己的偏好,左边的人喜欢歌曲P、Q、R、S,右边的人喜欢歌曲Q、R、S、T。
协同过滤使用的就是他们的偏好数据。首先他们共同偏好歌曲Q、R、S所以他们很有可能是同一类用户。因此可以得出:他们相互都会喜欢对方的歌单,因而可以给一方推荐给另一方的歌单上的歌曲。比如给右边的人推荐T,给左边的人推荐P。
那么Spotify是如何做的呢?
如上图所示,所有的Spotify用户的偏好数据都在上图的矩阵中,一行代表一个用户的歌单,列代表的是歌曲曲目。
在得到上面的矩阵之后,使用下面的公式进行因式分解:
分解完毕之后可以得到2个向量,X代表用户向量,表征用户的音乐偏好;Y代表歌曲向量,表征一首歌。
经过计算之后得到了1.4亿的用户向量以及3千万的歌曲向量。这些向量本身是毫无意义的,但是对于推荐的时候进行对比却具有很大的帮助。比如为了寻找最类似的用户,比如寻找两首最类似的歌。
推荐模型2:NLP
NLP处理的是非结构化文本,比如博客、网页、新闻等等。NLP用于理解人类的自然语言。
Spotify的做法是:爬取网上关于音乐的信息,并分析用户讨论的具体的艺术家或者歌曲内容,比如用的什么形容词或者哪些词用的最多。这里我并不知道Spotify具体是如何做的,但是可以分享一下我对 Echo Nest的理解。 Echo Nest通过对爬取的信息进行分析,得到“文化向量(cultural vectors)”和“高频短语(top terms)。每首歌每个艺术家都有上千个日常变化的高频短语。每一个短语都具有一个对应的权重,表明这个短语描述内容的重要程度(大致就是使用这个短语描述这首歌使用的词语的概率)。
然后,与协同过滤类似,NLP模型使用这些短语和权重得到了歌曲的向量表示,之后用于比较两首歌是否类似。
推荐模型3:音频模型
上述2个模型基本已经能够提供相当好的性能了,那为什么还需要引入本模型呢?原因有两个:1.帮助提升推荐性能;2.语音模型考虑了新歌。比方说:一个歌手将自己的新作长传到Spotify,但他可能之后50个听众,并且由于是新歌,所以网上基本没有关于这些新歌的资料。这个时候上述的协同过滤模型和NLP模型就失去作用了。然而语音模型并不会对新歌和流行歌曲区别对待,而是新歌依然可以出现在“每周推荐”的流行榜上。
语音模型是如何做到的呢?但按就是使用到了CNN(卷积神经网络)。
CNN也用于人脸识别。Spotify只是将人脸识别中的像素替换成音乐的音频。下面是一个神经网络架构的示例:
图中的神经网络拥有4个卷积层(左边的4个大方框)和3个密集层(3个带箭头的长框)。网络的输入是时频表示的音轨,用于形成歌曲的频谱。
音轨通过卷积层之后,可以看到“全局池化层”,这一层贯穿了整个时间轴,有效的学习到歌曲在时间上特征的统计信息。
经过处理之后,神经网络分理出了对于歌曲的理解,包括时间签名、关键词、模式、时序和响度。下图是Daft Punk的 “Around the World”的30秒波形分析图。
最终,通过对歌曲的关键特性进行分析,得到了歌曲之间的本质上的相似性。因而用户能够得到基于他们历史歌单的精准推荐。
总结
上文介绍了3个主要推荐模型的基本内容,基于这3个主要模型就能得到“每周推荐”上的歌单了!当然啦,这些推荐模型都连接到了Spotify更大的生态上去,这个生态系统包含了大量的数据存储设备以及使用Hadopp集群,这些模型处理庞大的矩阵、无边无际的互联网音乐文本和海量的音频文件。
希望本文能够激起你对推荐系统的好奇心,现在我正在构建我自己的每周推荐,寻找我喜欢的音乐,探索背后使用到的机器学习技术。
[1]Spotify是一个起源于瑞典的音乐流服务,是全球最大的流音乐服务商,提供包括Sony Music、EMI、Warner Music Group和Universal四大唱片公司及众多独立厂牌所授权、由数字版权管理保护的音乐,使用用户在2017年6月已经达到1.4亿以上.
参考文献:
From Idea to Execution: Spotify’s Discover Weekly (Chris Johnson, ex-Spotify)Collaborative Filtering at Spotify (Erik Bernhardsson, ex-Spotify)
Recommending music on Spotify with deep learning (Sander Dieleman)
How music recommendation works — and doesn’t work (Brian Whitman, co-founder of The Echo Nest)
Ever Wonder How Spotify Discover Weekly Works? Data Science (Galvanize)
The magic that makes Spotify’s Discover Weekly playlists so damn good (Quartz)
The Echo Nest’s Analyzer Documentation
个人公众号:

相关文章推荐
- 如何实现基于内容和用户画像的个性化推荐
- 如何进行用户与产品直接的个性化推荐?
- 推荐一个非常个性化的音乐网站:8tracks
- 机器学习讲座,如何利用Spark MLlib进行个性推荐?
- 【翻译】如何删除debian jessie 的systemd 推荐
- 博客园个性化设置:如何让【推荐】【反对】层跟随滚动条移动
- 【推荐系统】深度学习大行其道,个性化推荐如何与时俱进?
- 机器学习讲座,如何利用Spark MLlib进行个性推荐?
- 第四范式程晓澄:机器学习如何优化推荐系统
- 第四范式程晓澄:机器学习如何优化推荐系统
- 如何实现基于内容和用户画像的个性化推荐
- 如何搭建一套个性化推荐系统?
- Foursquare CEO:如何将签到数据转变为个性化推荐
- 机器学习:个性化推荐之评分预测问题
- 爱奇艺火爆的背后,个性化推荐排序是如何配合的?
- 百度推出音乐随心听频道,瞄准个性化音乐推荐市场
- 购物网站的推荐算法-个性化推荐算法中如何处理买了还推
- 如何搭建一套个性化推荐系统?
- 如何实现基于内容和用户画像的个性化推荐