超级干货 :一文读懂大数据处理框架
2017-09-25 09:56
621 查看
说起大数据处理啊,一切都起源于Google公司的经典论文。在当时(2000年左右),由于网页数量急剧增加,Google公司内部平时要编写很多的程序来处理大量的原始数据:爬虫爬到的网页、网页请求日志;计算各种类型的派生数据:倒排索引、网页的各种图结构等等。这些计算在概念上很容易理解,但由于输入数据量很大,单机难以处理。所以需要利用分布式的方式完成计算,并且需要考虑如何进行并行计算、分配数据和处理失败等等问题。
针对这些复杂的问题,Google决定设计一套抽象模型来执行这些简单计算,并隐藏并发、容错、数据分布和均衡负载等方面的细节。受到Lisp和其它函数式编程语言map、reduce思想的启发,论文的作者意识到许多计算都涉及对每条数据执行map操作,得到一批中间key/value对,然后利用reduce操作合并那些key值相同的k-v对。这种模型能很容易实现大规模并行计算。
事实上,与很多人理解不同的是,MapReduce对大数据计算的最大贡献,其实并不是它名字直观显示的Map和Reduce思想(正如上文提到的,Map和Reduce思想在Lisp等函数式编程语言中很早就存在了),而是这个计算框架可以运行在一群廉价的PC机上。MapReduce的伟大之处在于给大众们普及了工业界对于大数据计算的理解:它提供了良好的横向扩展性和容错处理机制,至此大数据计算由集中式过渡至分布式。以前,想对更多的数据进行计算就要造更快的计算机,而现在只需要添加计算节点。
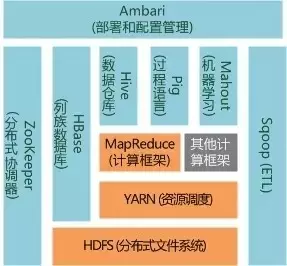
话说当年的Google有三宝:MapReduce、GFS和BigTable。但Google三宝虽好,寻常百姓想用却用不上,原因很简单:它们都不开源。于是Hadoop应运而生,初代Hadoop的MapReduce和HDFS即为Google的MapReduce和GFS的开源实现(另一宝BigTable的开源实现是同样大名鼎鼎的HBase)。自此,大数据处理框架的历史大幕正式的缓缓拉开。
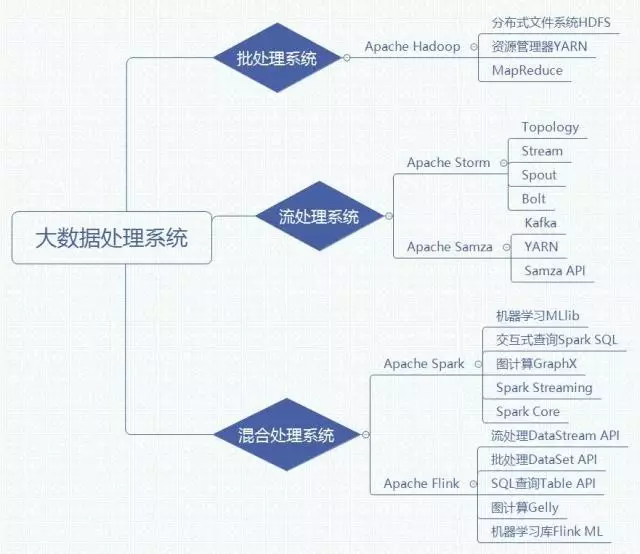
今天我们要讲的数据处理框架,按照对所处理的数据形式和得到结果的时效性分类,可以分为两类:
1.批处理系统
2.流处理系统
1批处理系统
批处理的过程包括将任务分解为较小的任务,分别在集群中的每个计算机上进行计算,根据中间结果重新组合数据,然后计算和组合最终结果。所以批处理系统主要操作大量的、静态的数据,并且等到全部处理完成后才能得到返回的结果。
由于批处理系统在处理海量的持久数据方面表现出色,所以它通常被用来处理历史数据,很多OLAP(在线分析处理)系统的底层计算框架就是使用的批处理系统。但是由于海量数据的处理需要耗费很多时间,所以批处理系统一般不适合用于对延时要求较高的场景。

然后批处理系统的代表就是Hadoop。Hadoop是首个在开源社区获得极大关注的大数据处理框架,在很长一段时间内,它几乎可以作为大数据技术的代名词。
在2.0版本以后,Hadoop由以下组件组成:
1.分布式文件系统HDFS
2.资源管理器YARN
3.MapReduce
关于它们,AI菌已经在之前的文章讨论过了。没有看过的朋友可以去翻一翻。
而且Hadoop不断发展完善,还集成了众多优秀的产品如非关系数据库HBase、数据仓库Hive、数据处理工具Sqoop、机器学习算法库Mahout、一致性服务软件ZooKeeper、管理工具Ambari等,形成了相对完整的生态圈和分布式计算事实上的标准。
2流处理系统
流处理系统好理解,那什么是流处理系统呢?小学的时候我们都做过这么一道数学题:一个水池有一个进水管和一个出水管,只打开进水管x个小时充满水,只打开出水管y个小时流光水,那么同时打开进水管和出水管,水池多长时间充满水?
流处理系统就相当于这个水池,把流进来的水(数据)进行加工,比如加盐让它变成盐水,然后再把加工过的水(数据)从出水管放出去。这样,数据就像水流一样永不停止,而且在水池中就被处理过了。所以,这种处理永不停止的接入数据的系统就叫做流处理系统。
流处理系统与批处理系统所处理的数据不同之处在于,流处理系统并不对已经存在的数据集进行操作,而是对从外部系统接入的的数据进行处理。流处理系统可以分为两种:
逐项处理:每次处理一条数据,是真正意义上的流处理。
微批处理:这种处理方式把一小段时间内的数据当作一个微批次,对这个微批次内的数据进行处理。
不论是哪种处理方式,其实时性都要远远好于批处理系统。因此,流处理系统非常适合应用于对实时性要求较高的场景,比如日志分析,设备监控、网站实时流量变化等等。
然后流处理系统的代表就是Apache Storm与Apache Samza了。
Apache Storm是一种侧重于低延迟的流处理框架,它可以处理海量的接入数据,以近实时方式处理数据。Storm延时可以达到亚秒级。
值得一提的是,一些国内的公司在Storm的基础上进行了改进,为推动流处理系统的发展做出了很大贡献。阿里巴巴的JStorm参考了Storm,并在网络IO、线程模型、资源调度及稳定性上做了改进。
提到Apache Samza,就不得不提到当前最流行的大数据消息中间件:Apache Kafka。Apache Kafka是一个分布式的消息中间件系统,具有高吞吐、低延时等特点,并且自带了容错机制。
如果已经拥有Hadoop集群和Kafka集群环境,那么使用Samza作为流处理系统无疑是一个非常好的选择。由于可以很方便的将处理过的数据再次写入Kafka,Samza尤其适合不同团队之间合作开发,处理不同阶段的多个数据流。
3混合处理系统
一些处理框架既可以进行批处理,也可以进行流处理。这些框架可以使用相同或相关的API处理历史和实时数据。
虽然专注于一种处理方式可能非常适合特定场景,但是混合框架为数据处理提供了通用的解决方案。
而当前主流的混合处理框架主要为Spark和Flink。
如果说如今大数据处理框架处于一个群星闪耀的年代,那Spark无疑就是所有星星中最闪亮的那一颗。Spark由加州大学伯克利分校AMP实验室开发,最初的设计受到了MapReduce思想的启发,但不同于MapReduce的是,Spark通过内存计算模型和执行优化大幅提高了对数据的处理能力
而且除了最初开发用于批处理的Spark Core和用于流处理的Spark Streaming,Spark还提供了其他编程模型用于支持图计算(GraphX)、交互式查询(Spark SQL)和机器学习(MLlib)。
有趣的是,同样作为混合处理框架,Flink的思想与Spark是完全相反的:Spark把流拆分成若干个小批次来处理,而Flink把批处理任务当作有界的流来处理。
除了流处理(DataStream API)和批处理(DataSet API)之外,Flink也提供了类SQL查询(Table API)、图计算(Gelly)和机器学习库(Flink ML)。而令人惊讶的是,在很多性能测试中,Flink甚至略优于Spark。
在目前的数据处理框架领域,Flink可谓独树一帜。虽然Spark同样也提供了批处理和流处理的能力,但Spark流处理的微批次架构使其响应时间略长。Flink流处理优先的方式实现了低延迟、高吞吐和真正逐条处理。
同样,Flink也并不是完美的。Flink目前最大的缺点就是缺乏在大型公司实际生产项目中的成功应用案例。相对于Spark来讲,它还不够成熟,社区活跃度也没有Spark那么高。但假以时日,Flink必然会改变数据处理框架的格局。
4大数据处理框架的选择
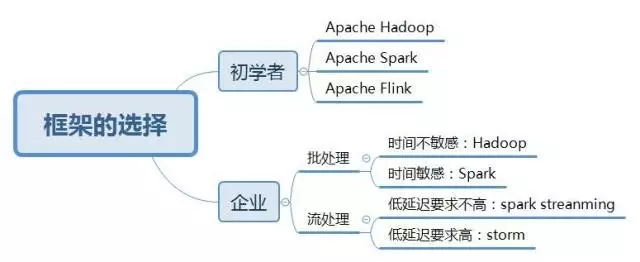
对于初学者
由于Apache Hadoop在大数据领域的广泛使用,因此仍推荐作为初学者学习数据处理框架的首选。虽然MapReduce因为性能原因以后的应用会越来越少,但是YARN和HDFS依然作为其他框架的基础组件被大量使用(比如HBase依赖于HDFS,YARN可以为Spark、Samza等框架提供资源管理)。学习Hadoop可以为以后的进阶打下基础。
Apache Spark在目前的企业应用中应该是当之无愧的王者。在批处理领域,虽然Spark与MapReduce的市场占有率不相上下,但Spark稳定上升,而MapReduce却稳定下降。而在流处理领域,Spark Streaming与另一大流处理系统Apache Storm共同占据了大部分市场(当然很多公司会使用内部研发的数据处理框架,但它们多数并不开源)。伯克利的正统出身、活跃的社区以及大量的商用案例都是Spark的优势。除了可用于批处理和流处理系统,Spark还支持交互式查询、图计算和机器学习。Spark在未来几年内仍然会是大数据处理的主流框架,推荐同学们认真学习。
另一个作为混合处理框架的Apache Flink则潜力无限,被称作“下一代数据处理框架”。虽然目前存在社区活跃度不够高、商用案例较少等情况,不过“是金子总会发光”,如果Flink能在商业应用上有突出表现,则可能挑战Spark的地位。
2.对于企业应用
如果企业中只需要批处理工作,并且对时间并不敏感,那么可以使用成本较其他解决方案更低的Hadoop集群。
如果企业仅进行流处理,并且对低延迟有着较高要求,Storm更加适合,如果对延迟不非常敏感,可以使用Spark Streaming。而如果企业内部已经存在Kafka和Hadoop集群,并且需要多团队合作开发(下游团队会使用上游团队处理过的数据作为数据源),那么Samza是一个很好的选择。
如果需要同时兼顾批处理与流处理任务,那么Spark是一个很好的选择。混合处理框架的另一个好处是,降低了开发人员的学习成本,从而为企业节约人力成本。Flink提供了真正的流处理能力并且同样具备批处理能力,但商用案例较少,对于初次尝试数据处理的企业来说,大规模使用Flink存在一定风险。
针对这些复杂的问题,Google决定设计一套抽象模型来执行这些简单计算,并隐藏并发、容错、数据分布和均衡负载等方面的细节。受到Lisp和其它函数式编程语言map、reduce思想的启发,论文的作者意识到许多计算都涉及对每条数据执行map操作,得到一批中间key/value对,然后利用reduce操作合并那些key值相同的k-v对。这种模型能很容易实现大规模并行计算。
事实上,与很多人理解不同的是,MapReduce对大数据计算的最大贡献,其实并不是它名字直观显示的Map和Reduce思想(正如上文提到的,Map和Reduce思想在Lisp等函数式编程语言中很早就存在了),而是这个计算框架可以运行在一群廉价的PC机上。MapReduce的伟大之处在于给大众们普及了工业界对于大数据计算的理解:它提供了良好的横向扩展性和容错处理机制,至此大数据计算由集中式过渡至分布式。以前,想对更多的数据进行计算就要造更快的计算机,而现在只需要添加计算节点。
话说当年的Google有三宝:MapReduce、GFS和BigTable。但Google三宝虽好,寻常百姓想用却用不上,原因很简单:它们都不开源。于是Hadoop应运而生,初代Hadoop的MapReduce和HDFS即为Google的MapReduce和GFS的开源实现(另一宝BigTable的开源实现是同样大名鼎鼎的HBase)。自此,大数据处理框架的历史大幕正式的缓缓拉开。
今天我们要讲的数据处理框架,按照对所处理的数据形式和得到结果的时效性分类,可以分为两类:
1.批处理系统
2.流处理系统
1批处理系统
批处理的过程包括将任务分解为较小的任务,分别在集群中的每个计算机上进行计算,根据中间结果重新组合数据,然后计算和组合最终结果。所以批处理系统主要操作大量的、静态的数据,并且等到全部处理完成后才能得到返回的结果。
由于批处理系统在处理海量的持久数据方面表现出色,所以它通常被用来处理历史数据,很多OLAP(在线分析处理)系统的底层计算框架就是使用的批处理系统。但是由于海量数据的处理需要耗费很多时间,所以批处理系统一般不适合用于对延时要求较高的场景。
然后批处理系统的代表就是Hadoop。Hadoop是首个在开源社区获得极大关注的大数据处理框架,在很长一段时间内,它几乎可以作为大数据技术的代名词。
在2.0版本以后,Hadoop由以下组件组成:
1.分布式文件系统HDFS
2.资源管理器YARN
3.MapReduce
关于它们,AI菌已经在之前的文章讨论过了。没有看过的朋友可以去翻一翻。
而且Hadoop不断发展完善,还集成了众多优秀的产品如非关系数据库HBase、数据仓库Hive、数据处理工具Sqoop、机器学习算法库Mahout、一致性服务软件ZooKeeper、管理工具Ambari等,形成了相对完整的生态圈和分布式计算事实上的标准。
2流处理系统
流处理系统好理解,那什么是流处理系统呢?小学的时候我们都做过这么一道数学题:一个水池有一个进水管和一个出水管,只打开进水管x个小时充满水,只打开出水管y个小时流光水,那么同时打开进水管和出水管,水池多长时间充满水?
流处理系统就相当于这个水池,把流进来的水(数据)进行加工,比如加盐让它变成盐水,然后再把加工过的水(数据)从出水管放出去。这样,数据就像水流一样永不停止,而且在水池中就被处理过了。所以,这种处理永不停止的接入数据的系统就叫做流处理系统。
流处理系统与批处理系统所处理的数据不同之处在于,流处理系统并不对已经存在的数据集进行操作,而是对从外部系统接入的的数据进行处理。流处理系统可以分为两种:
逐项处理:每次处理一条数据,是真正意义上的流处理。
微批处理:这种处理方式把一小段时间内的数据当作一个微批次,对这个微批次内的数据进行处理。
不论是哪种处理方式,其实时性都要远远好于批处理系统。因此,流处理系统非常适合应用于对实时性要求较高的场景,比如日志分析,设备监控、网站实时流量变化等等。
然后流处理系统的代表就是Apache Storm与Apache Samza了。
Apache Storm是一种侧重于低延迟的流处理框架,它可以处理海量的接入数据,以近实时方式处理数据。Storm延时可以达到亚秒级。
值得一提的是,一些国内的公司在Storm的基础上进行了改进,为推动流处理系统的发展做出了很大贡献。阿里巴巴的JStorm参考了Storm,并在网络IO、线程模型、资源调度及稳定性上做了改进。
提到Apache Samza,就不得不提到当前最流行的大数据消息中间件:Apache Kafka。Apache Kafka是一个分布式的消息中间件系统,具有高吞吐、低延时等特点,并且自带了容错机制。
如果已经拥有Hadoop集群和Kafka集群环境,那么使用Samza作为流处理系统无疑是一个非常好的选择。由于可以很方便的将处理过的数据再次写入Kafka,Samza尤其适合不同团队之间合作开发,处理不同阶段的多个数据流。
3混合处理系统
一些处理框架既可以进行批处理,也可以进行流处理。这些框架可以使用相同或相关的API处理历史和实时数据。
虽然专注于一种处理方式可能非常适合特定场景,但是混合框架为数据处理提供了通用的解决方案。
而当前主流的混合处理框架主要为Spark和Flink。
如果说如今大数据处理框架处于一个群星闪耀的年代,那Spark无疑就是所有星星中最闪亮的那一颗。Spark由加州大学伯克利分校AMP实验室开发,最初的设计受到了MapReduce思想的启发,但不同于MapReduce的是,Spark通过内存计算模型和执行优化大幅提高了对数据的处理能力
而且除了最初开发用于批处理的Spark Core和用于流处理的Spark Streaming,Spark还提供了其他编程模型用于支持图计算(GraphX)、交互式查询(Spark SQL)和机器学习(MLlib)。
有趣的是,同样作为混合处理框架,Flink的思想与Spark是完全相反的:Spark把流拆分成若干个小批次来处理,而Flink把批处理任务当作有界的流来处理。
除了流处理(DataStream API)和批处理(DataSet API)之外,Flink也提供了类SQL查询(Table API)、图计算(Gelly)和机器学习库(Flink ML)。而令人惊讶的是,在很多性能测试中,Flink甚至略优于Spark。
在目前的数据处理框架领域,Flink可谓独树一帜。虽然Spark同样也提供了批处理和流处理的能力,但Spark流处理的微批次架构使其响应时间略长。Flink流处理优先的方式实现了低延迟、高吞吐和真正逐条处理。
同样,Flink也并不是完美的。Flink目前最大的缺点就是缺乏在大型公司实际生产项目中的成功应用案例。相对于Spark来讲,它还不够成熟,社区活跃度也没有Spark那么高。但假以时日,Flink必然会改变数据处理框架的格局。
4大数据处理框架的选择
对于初学者
由于Apache Hadoop在大数据领域的广泛使用,因此仍推荐作为初学者学习数据处理框架的首选。虽然MapReduce因为性能原因以后的应用会越来越少,但是YARN和HDFS依然作为其他框架的基础组件被大量使用(比如HBase依赖于HDFS,YARN可以为Spark、Samza等框架提供资源管理)。学习Hadoop可以为以后的进阶打下基础。
Apache Spark在目前的企业应用中应该是当之无愧的王者。在批处理领域,虽然Spark与MapReduce的市场占有率不相上下,但Spark稳定上升,而MapReduce却稳定下降。而在流处理领域,Spark Streaming与另一大流处理系统Apache Storm共同占据了大部分市场(当然很多公司会使用内部研发的数据处理框架,但它们多数并不开源)。伯克利的正统出身、活跃的社区以及大量的商用案例都是Spark的优势。除了可用于批处理和流处理系统,Spark还支持交互式查询、图计算和机器学习。Spark在未来几年内仍然会是大数据处理的主流框架,推荐同学们认真学习。
另一个作为混合处理框架的Apache Flink则潜力无限,被称作“下一代数据处理框架”。虽然目前存在社区活跃度不够高、商用案例较少等情况,不过“是金子总会发光”,如果Flink能在商业应用上有突出表现,则可能挑战Spark的地位。
2.对于企业应用
如果企业中只需要批处理工作,并且对时间并不敏感,那么可以使用成本较其他解决方案更低的Hadoop集群。
如果企业仅进行流处理,并且对低延迟有着较高要求,Storm更加适合,如果对延迟不非常敏感,可以使用Spark Streaming。而如果企业内部已经存在Kafka和Hadoop集群,并且需要多团队合作开发(下游团队会使用上游团队处理过的数据作为数据源),那么Samza是一个很好的选择。
如果需要同时兼顾批处理与流处理任务,那么Spark是一个很好的选择。混合处理框架的另一个好处是,降低了开发人员的学习成本,从而为企业节约人力成本。Flink提供了真正的流处理能力并且同样具备批处理能力,但商用案例较少,对于初次尝试数据处理的企业来说,大规模使用Flink存在一定风险。

相关文章推荐
- 一文读懂大数据计算框架与平台
- 超级干货 :一文读懂LinkedIn个性化推荐模型及建模原理
- 一文读懂大数据计算框架与平台
- 超级干货 :一文读懂人工神经网络学习原理
- 一文读懂大数据计算框架与平台
- 超级干货 :一文读懂贝叶斯分类算法(附学习资源)
- 干货丨一文读懂深度学习与机器学习的差异
- 流式大数据处理的三种框架:Storm,Spark和Samza
- 流式大数据处理的三种框架:Storm,Spark和Samza
- 流式大数据处理的三种框架:Storm,Spark和Samza
- spring boot框架学习8-【干货】spring boot的web开发(4)-自定义拦截器处理权限
- 流式大数据处理的三种框架:Storm,Spark和Samza
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
- 干货|一文读懂图像局部特征点检测算法
- 目标检测101:一文带你读懂深度学习框架下的目标检测
- 流式大数据处理的三种框架:Storm,Spark和Samza
- 【大数据干货】轻松处理每天2TB的日志数据,支撑运营团队进行大数据分析挖掘,随时洞察用户个性化需求。
- 干货丨一文读懂深度学习(附学习资源,据说点赞2W+)
- 阿里HBase超详实践总结 | 一文读懂大数据时代的结构化存储
- 王家林“云计算分布式大数据Hadoop实战高手之路---从零开始”的第一讲Hadoop图文训练课程:10分钟理解云计算分布式大数据处理框架Hadoop