【大数据干货】轻松处理每天2TB的日志数据,支撑运营团队进行大数据分析挖掘,随时洞察用户个性化需求。
2017-04-04 00:00
731 查看
“用户每天产生的日志量大约在2TB。我们需要将这些海量的数据导入云端,然后分天、分小时的展开数据分析作业,分析结果再导入数据库和报表系统,最终展示在运营人员面前。”墨迹天气运维部经理章汉龙介绍,整个过程中数据量庞大,且计算复杂,这对云平台的大数据能力、生态完整性和开放性提出了很高的要求。
“用户每天产生的日志量大约在2TB。我们需要将这些海量的数据导入云端,然后分天、分小时的展开数据分析作业,分析结果再导入数据库和报表系统,最终展示在运营人员面前。”墨迹天气运维部经理章汉龙介绍,整个过程中数据量庞大,且计算复杂,这对云平台的大数据能力、生态完整性和开放性提出了很高的要求。 之前墨迹使用国外某云计算服务公司的云服务器存储这些数据,利用Hadoop的MapReducer和Hive对数据进行处理分析,但是存在以下问题:
1.成本:包括存储、计算及大数据处理服务成本对比阿里云成本很高。
2.网络带宽:移动端业务量大,需要大量的网络带宽资源支持,但数据上传也需要占用网络带宽,彼此之间相互干扰造成数据传输不稳定。
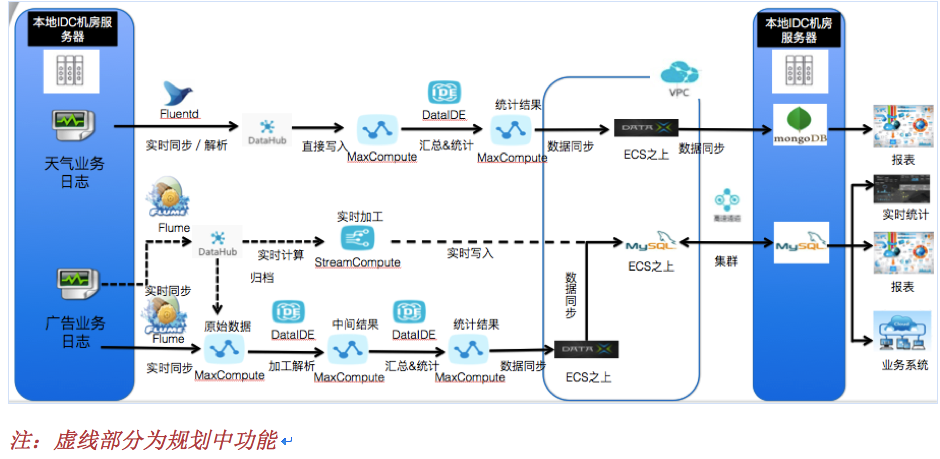
新的日志分析架构如页面下方架构图所示。
方案涉及的阿里云数加平台组件有:
• 阿里云数加-大数据计算服务MaxCompute产品地址:https://www.aliyun.com/product/odps
• 大数据开发套件(DataIDE)https://data.aliyun.com/product/ide
• 流计算(StreamCompute,规划中)https://data.aliyun.com/product/sc
• 流式数据发布和订阅(DataHub)
另外,由于每天产生的数据量较大,上传数据会占用带宽,为了不影响业务系统的网络资源,客户开通了阿里云高速通道,用于数据上传。通过此种手段解决了网络带宽的问题。
通过阿里云数加日志分析解决方案,墨迹的业务得到以下提升:
1.充分利用移动端积累下来的海量日志数据。
2.对用户使用情况和广告业务进行大数据分析。
3.利用阿里云数加大数据技术,基于对日志数据的分析,支持运营团队和广告团队优化现有业务。
2.存储方面,MaxCompute的表按列压缩存储,更节省存储空间,整体存储和计算的费用比之前省了70%,性能和稳定性也有很大提升。
3.可以借助MaxCompute上的机器学习算法,对数据进行深度挖掘,为用户提供个性化的服务。
4.阿里云MaxCompute提供更为易用、全面的大数据分析功能。MaxCompute可根据业务情况做到计算资源自动弹性伸缩,天然集成存储功能。通过简单的几项配置操作后,即可完成数据上传,同时实现了多种开源软件的对接。
关于墨迹天气
北京墨迹风云科技股份有限公司于2010年成立,是一家以“做卓越的天气服务公司”为目标的新兴移动互联网公司,主要开发和运营的“墨迹天气”是一款免费的天气信息查询软件。“墨迹天气”APP目前在全球约有超过5亿人在使用,支持196个国家70多万个城市及地区的天气查询,分钟级、公里级天气预报,实时预报雨雪。提供15天天气预报,5天空气质量预报,实时空气质量及空气质量等级预报,其短时预报功能,可实现未来2小时内,每10分钟一次,预测逐分钟逐公里的天气情况。特殊天气提前发送预警信息,帮助用户更好做出生活决策。在墨迹天气上,每天有超过 5 亿次的天气查询需求和将近20亿次的广告请求,这个数字甚至要大于 Twitter 每天发帖量。墨迹天气已经集成了多语言版本,可根据手机系统语言自动适配,用户覆盖包括中国大陆、港澳台,日韩及东南亚、欧美等全球各地用户。挑战
墨迹运营团队每天最关心的是用户正在如何使用墨迹,在他们操作中透露了哪些个性化需求。这些数据全部存储在墨迹的API日志中,对这些数据分析,就变成了运营团队每天的最重要的工作。墨迹天气的API每天产生的日志量大约在2TB左右,主要的日志分析场景是天气查询业务和广告业务。“用户每天产生的日志量大约在2TB。我们需要将这些海量的数据导入云端,然后分天、分小时的展开数据分析作业,分析结果再导入数据库和报表系统,最终展示在运营人员面前。”墨迹天气运维部经理章汉龙介绍,整个过程中数据量庞大,且计算复杂,这对云平台的大数据能力、生态完整性和开放性提出了很高的要求。 之前墨迹使用国外某云计算服务公司的云服务器存储这些数据,利用Hadoop的MapReducer和Hive对数据进行处理分析,但是存在以下问题:
1.成本:包括存储、计算及大数据处理服务成本对比阿里云成本很高。
2.网络带宽:移动端业务量大,需要大量的网络带宽资源支持,但数据上传也需要占用网络带宽,彼此之间相互干扰造成数据传输不稳定。
解决方案及架构
针对上述情况,墨迹将日志分析业务逐步迁移到阿里云大数据平台-数加平台之上。新的日志分析架构如页面下方架构图所示。
方案涉及的阿里云数加平台组件有:
• 阿里云数加-大数据计算服务MaxCompute产品地址:https://www.aliyun.com/product/odps
• 大数据开发套件(DataIDE)https://data.aliyun.com/product/ide
• 流计算(StreamCompute,规划中)https://data.aliyun.com/product/sc
• 流式数据发布和订阅(DataHub)
另外,由于每天产生的数据量较大,上传数据会占用带宽,为了不影响业务系统的网络资源,客户开通了阿里云高速通道,用于数据上传。通过此种手段解决了网络带宽的问题。
通过阿里云数加日志分析解决方案,墨迹的业务得到以下提升:
1.充分利用移动端积累下来的海量日志数据。
2.对用户使用情况和广告业务进行大数据分析。
3.利用阿里云数加大数据技术,基于对日志数据的分析,支持运营团队和广告团队优化现有业务。
收益
1.迁移到MaxCompute后,流程上做了优化,省掉了编写MR程序的工作,日志数据全部通过SQL进行分析,工作效率提升了5倍以上。2.存储方面,MaxCompute的表按列压缩存储,更节省存储空间,整体存储和计算的费用比之前省了70%,性能和稳定性也有很大提升。
3.可以借助MaxCompute上的机器学习算法,对数据进行深度挖掘,为用户提供个性化的服务。
4.阿里云MaxCompute提供更为易用、全面的大数据分析功能。MaxCompute可根据业务情况做到计算资源自动弹性伸缩,天然集成存储功能。通过简单的几项配置操作后,即可完成数据上传,同时实现了多种开源软件的对接。
架构图

相关文章推荐
- 【大数据干货】轻松处理每天2TB的日志数据,支撑运营团队进行大数据分析挖掘,随时洞察用户个性化需求。
- 没有大数据的支撑,如何发现用户需求?(分享一些收费课程讲的内容,运营纯干货)
- hadoop学习(Map、Reduce、日志分析和数据挖掘、大数据处理)
- 用Apache Spark进行大数据处理之用Spark GraphX图数据分析(6)
- 机锋网2012年Q2运营数据分析:用户与开发者对应用的需求存在巨大差异
- 针对Ubuntu系统日志的数据挖掘及分析处理
- 使用Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析【公安大数据】
- 用Apache Spark进行大数据处理 - 第六部分: 用Spark GraphX进行图数据分析
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 基于用户行为的数据分析与挖掘+分布式日志管理系统
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 数据分析与挖掘学习日志之数据处理阶段(二)
- 大数据日志分析系统-spark进行日志计算
- 数据分析与数据挖掘在常规工作中的应用——日期处理
- 团队项目作业第二项:利用NABCD模型进行竞争性需求分析
- 如何利用数据挖掘进行分析的方法
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
- C++遍历日志log目录,并提取数据进行分析
- 面向移动互联网的用户行为分析和数据挖掘