java程序员的大数据之路(6):定制的Writable类型
2017-09-20 17:51
453 查看
序列化
序列化是指将结构化对象转化为字节流,以便在网络上传输或写入磁盘。反序列化是指将字节流转回结构化对象的过程。在Hadoop中,系统中多个节点上进程间的通信是通过“远程过程调用”(RPC)实现的。RPC协议是将消息序列化成二进制流后进行传输。通常情况下,RPC序列化格式如下:
紧凑
紧凑的格式能够使我们充分利用网络带宽
快速
进程间通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化的开销
可扩展
协议为了满足新的需求而不断变化,所以在控制客户端和服务器的过程中,需要直接引用相应的协议。
互操作
对某些系统来说,希望能够支持以不同语言写的客户端与服务器交互,所以需要设计一种特定的格式来满足这一需求。
Hadoop的序列化格式
Hadoop使用自己的序列化格式Writable,它格式紧凑,速度快,但很难用Java以外的语言进行扩展或使用。Avro在一定程度上解决了这一不足。想了解的朋友可以看一下Avro总结(RPC/序列化)Writable类对Java基本类型提供了封装(short和char除外),所有封装都包含get()和set()两个方法用于读取和设置封装的值。
| Java基本类型 | Writable实现 | 序列化大小 |
|---|---|---|
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
| int | IntWritable VintWritable | 4 1~5 |
| float | FloatWritable | 4 |
| long | LongWritable VlongWritable | 8 1~9 |
| double | DoubleWritable | 8 |
实现定制的Writable
Hadoop的Writable可以满足大部分需求,但有些情况下我们需要根据自己的需求构造一个新的实现,这里举一个栗子,叫做TextPair,就是一对Text。主要代码
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public void setFirst(Text first) {
this.first = first;
}
public Text getSecond() {
return second;
}
public void setSecond(Text second) {
this.second = second;
}
public int compareTo(TextPair tp) {
// int cmp = first.compareTo(tp.first);
// if (cmp != 0) {
// return cmp;
// }
// return second.compareTo(tp.second);
return new FirstComparator().compare(this, tp);
}
public void write(DataOutput dataOutput) throws IOException {
first.write(dataOutput);
second.write(dataOutput);
}
public void readFields(DataInput dataInput) throws IOException {
first.readFields(dataInput);
second.readFields(dataInput);
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public String toString() {
return first + "\t" + second;
}
public static class FirstComparator extends WritableComparator {
public static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if(a instanceof TextPair && b instanceof TextPair) {
4000
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}
}测试结果
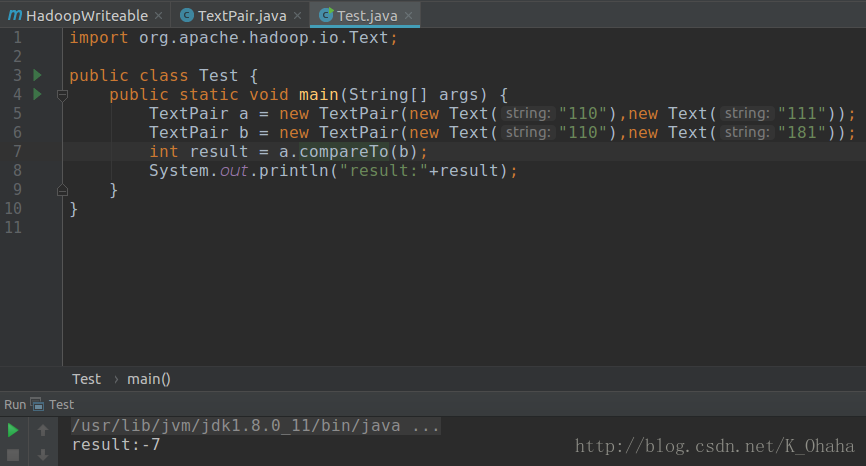
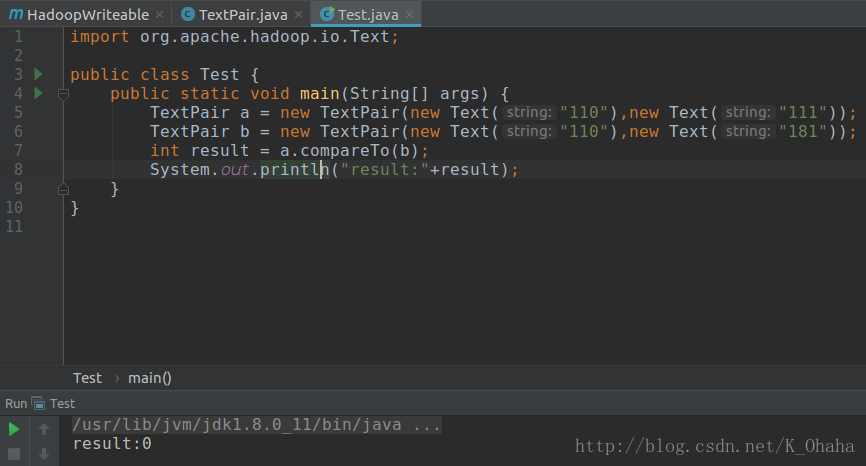
说明
上面两个运行结果,第一个是使用默认比较器的结果,第二个是定制比较器FirstComparator(只比较第一个Text)。需要注意的是:由于Writable实例具有易变性并且通常可以重用,所以要尽量避免在write()和readFields()函数中分配对象。
相关文章推荐
- java程序员的大数据之路(12):Hadoop的守护进程
- java程序员的python之路(数据类型)
- java程序员的大数据之路(9):MapReduce的类型
- java程序员的大数据之路(13):Pig入门
- java程序员的大数据之路(5):HDFS压缩与解压缩
- java程序员的大数据之路(8):MapReduce的工作机制
- java程序员的大数据之路(15):Pig Latin用户自定义函数
- java程序员的大数据之路(4):编程调用HDFS
- java程序员的大数据之路(7):基于文件的数据结构
- java程序员的大数据之路(16):Hive简介
- java程序员的大数据之路(10):MapReduce的排序
- java程序员的大数据之路(11):MapReduce的连接
- Java程序员从笨鸟到菜鸟之(四十四)细谈struts2(七)数据类型转换详解
- Java程序员从笨鸟到菜鸟之(四十三)细谈struts2(六)获取servletAPI和封装表单数据
- Java程序员成长之路
- 2012北京地区Java程序员的平均工资调查数据分析
- JAVA程序员成长之路
- 2012北京地区Java程序员的平均工资调查数据分析
- Java程序员从笨鸟到菜鸟之(一百零四)java操作office和pdf文件(二)利用POI实现数据导出excel报表
- Java程序员从笨鸟到菜鸟之(一百零五)java操作office和pdf文件(三)利用jxl实现数据导出excel报表以及与POI的区别