python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码
2017-09-13 12:58
896 查看
目前知乎使用了点击图中倒立文字的验证码:
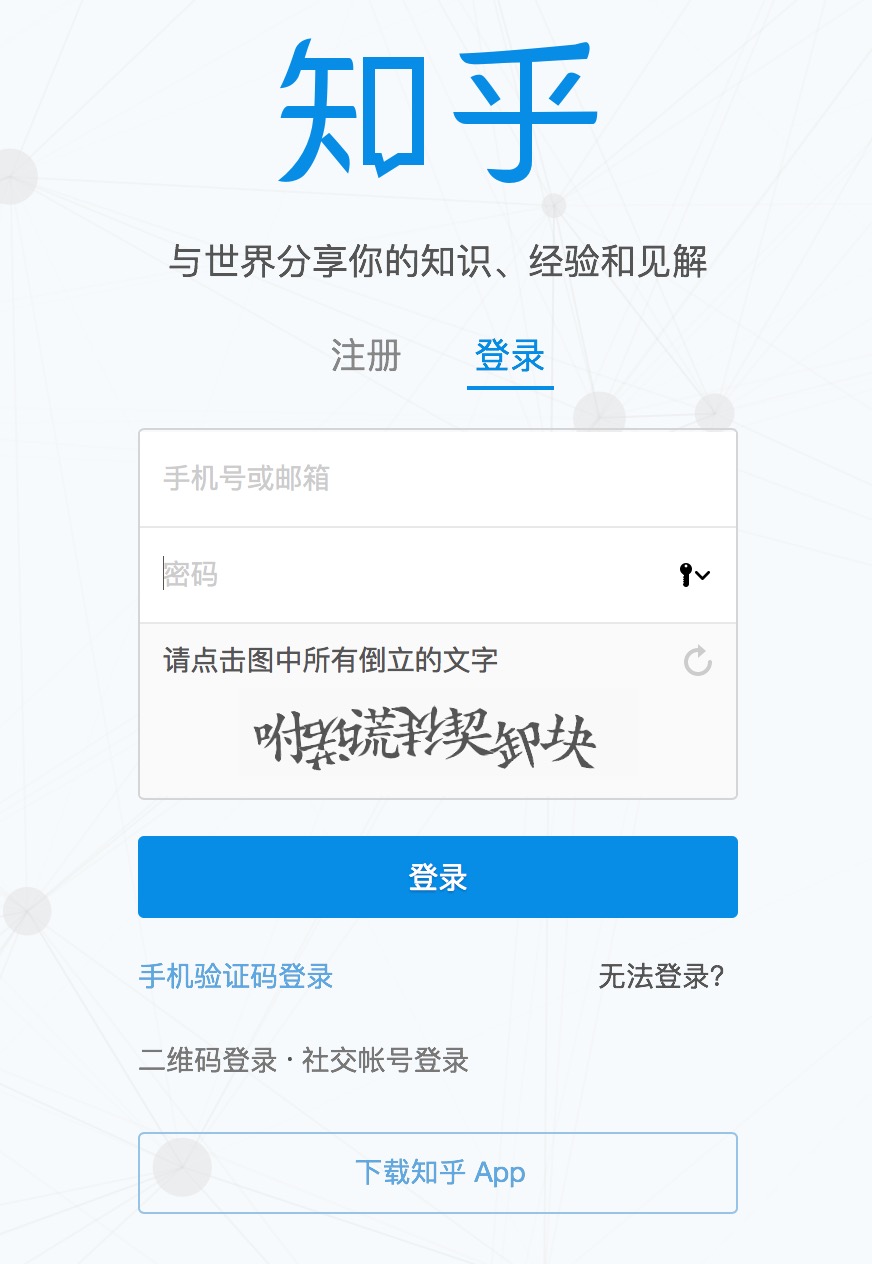
用户需要点击图中倒立的文字才能登录。
这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一道来。
我们学习爬虫首先就要知道浏览器给服务器传输有什么字段(我用的是Safari浏览器进行演示,当然Chrome、Firefox都可以)
我们点击了第一个和第二个文字:
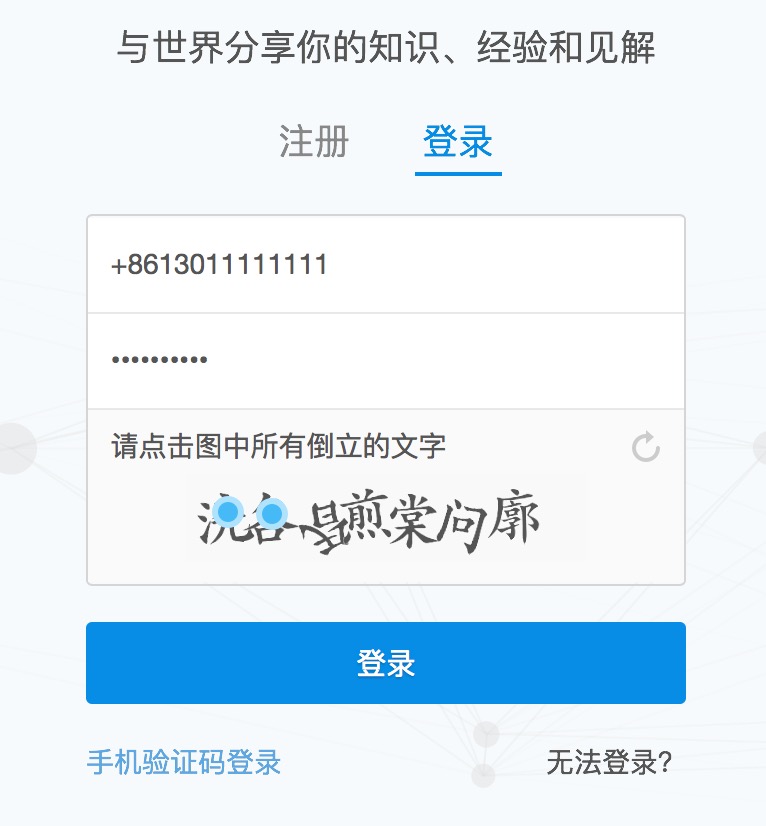
右键审查元素-->点击登录 后可以看到:

从右面可以得到:报文发送的URL是:https://www/zhihu/com/login/phone_num
这不难理解,知乎的登录是把手机和邮箱区分开来,我们用的是手机登录,经过测试邮箱的URL是:https://www/zhihu/com/login/email,这里就不截图了。
把右面的资源往下拉:
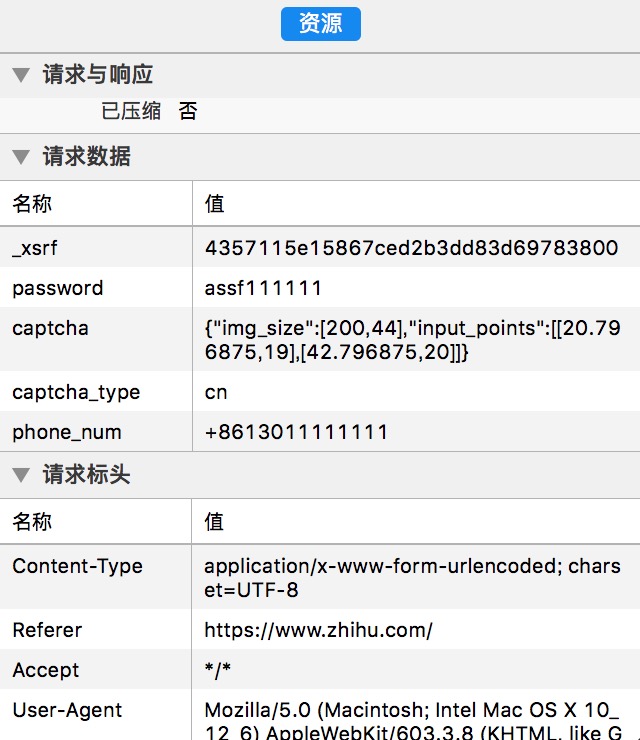
除了phone_num是用户名,password是密码,我们还看到了几个重要信息:_xsrf、captcha、captcha_type
那么重点来了,这都分别是什么意思呢?经过反复查询,直接把简介明了的解释给大家:
_xsrf:是“跨站请求伪造”(CSRF / XSRF)(Cross Site Request Forgery),这是知乎的一个安全协议,当你第一次访问知乎主页www.zhihu.com的时候,知乎会自动往你的浏览器发送一个_xsrf字段并且和你的主机绑定,之后的你每次访问知乎服务器时,你的浏览器都会带上这个字段,知乎发现你发送的_xsrf是我给你的_xsrf时才能有权访问,如果_xsrf错误或者不填都无法访问。顺便一提,这是一个安全机制,基本所有的网站都会设置一个
XSRF/CSRF 的字段,防止黑客攻击。
我们既然知道浏览器每次向知乎发送请求时都会带上_xsrf字段,那么我们的爬虫就必须要模拟浏览器访问知乎首页获取这个 _xsrf 字段并在登录时提交这个字段,才能登录成功。
captcha:里的"img_size"字段是固定的,每次都是[200,44],应该就是图片大小的意思。后面的"input_points"是你点击验证码中倒立文字的坐标,由于验证码中七个文字位置是固定的,我们只要每个字都点一下再进行登录,再审查元素来确定每个字的坐标就能模拟点击了(是不是豁然开朗),这个步骤自行点击来获取坐标,我把我测试好的七个文字坐标依次拿出来:[22.796875,22],[42.796875,22],[63.796875,21],[84.796875,20],[107.796875,20],[129.796875,22],[150.796875,22]。
captcha_type:这个字段就有意思了,其中有一个小技巧来切换成数字英文验证码。如果把它设置成 "cn" 就是倒立文字验证码,设置成 "en" 就是数字英文验证码,我没就这里设置成"cn",数字英文验证码网上很多,大家可自行寻找。(经测试不填这个字段也是数字英文验证码)
到这里思路就很清晰了,我们知道了这三个重要信息,就知道如何让爬虫登录知乎了,不多说直接上代码:
想必大家看代码都能看的懂了,我再简单说一嘴重要的
非常要注意的地方是:必须要用session来请求验证码再用session来提交报文,为什么不能用requests呢?一个session就是一个会话,如果用一个session访问了一个网站,后面再拿着这个session再请求这个网站,它会把网站带给我们的cookie或者说网站放到字段里面的session完全的给带回去,这里面的cookie就非常重要,在我们访问知乎的时候,不管我们有没有登录,服务器都可以往我们的header里面放一些值,我们用pycharm的debug来看一下session:
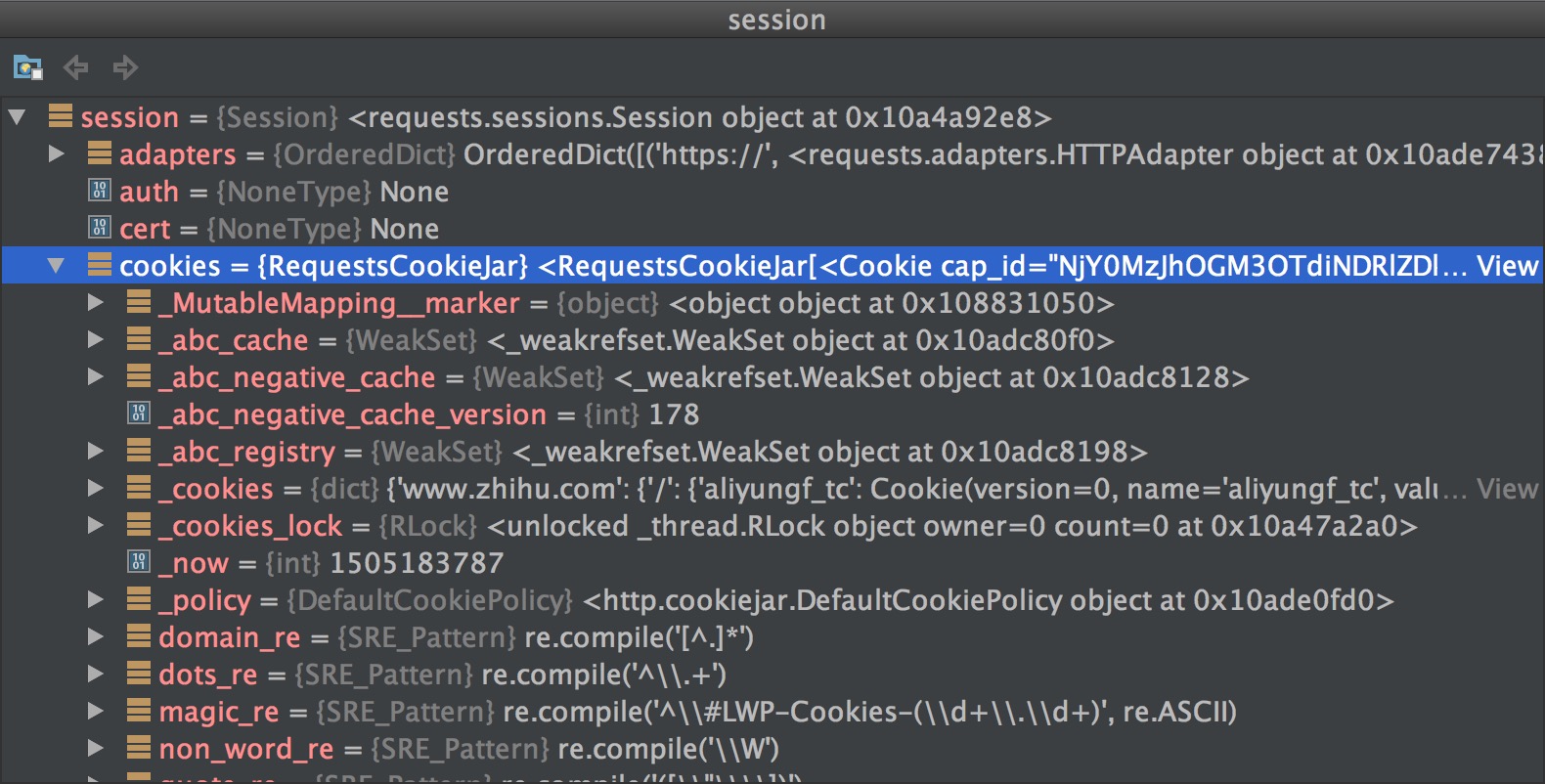
可以看到里面有很多cookie,获取验证码时服务器给我们发的这些cookie,必须在登录时再传给知乎服务器才算认证成功。如果在登录时用requests,它会再建立一次session,就无法把获取验证码带来的cookies传给服务器,这样固然认证失败。
好了,大功告成!只要输入第几个文字是倒立的就行了,比如第二个和第四个文字是倒立的,输入:24 按回车后就自动添加坐标,是不是很开心!
用户需要点击图中倒立的文字才能登录。
这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一道来。
我们学习爬虫首先就要知道浏览器给服务器传输有什么字段(我用的是Safari浏览器进行演示,当然Chrome、Firefox都可以)
我们点击了第一个和第二个文字:
右键审查元素-->点击登录 后可以看到:
从右面可以得到:报文发送的URL是:https://www/zhihu/com/login/phone_num
这不难理解,知乎的登录是把手机和邮箱区分开来,我们用的是手机登录,经过测试邮箱的URL是:https://www/zhihu/com/login/email,这里就不截图了。
把右面的资源往下拉:
除了phone_num是用户名,password是密码,我们还看到了几个重要信息:_xsrf、captcha、captcha_type
那么重点来了,这都分别是什么意思呢?经过反复查询,直接把简介明了的解释给大家:
_xsrf:是“跨站请求伪造”(CSRF / XSRF)(Cross Site Request Forgery),这是知乎的一个安全协议,当你第一次访问知乎主页www.zhihu.com的时候,知乎会自动往你的浏览器发送一个_xsrf字段并且和你的主机绑定,之后的你每次访问知乎服务器时,你的浏览器都会带上这个字段,知乎发现你发送的_xsrf是我给你的_xsrf时才能有权访问,如果_xsrf错误或者不填都无法访问。顺便一提,这是一个安全机制,基本所有的网站都会设置一个
XSRF/CSRF 的字段,防止黑客攻击。
我们既然知道浏览器每次向知乎发送请求时都会带上_xsrf字段,那么我们的爬虫就必须要模拟浏览器访问知乎首页获取这个 _xsrf 字段并在登录时提交这个字段,才能登录成功。
captcha:里的"img_size"字段是固定的,每次都是[200,44],应该就是图片大小的意思。后面的"input_points"是你点击验证码中倒立文字的坐标,由于验证码中七个文字位置是固定的,我们只要每个字都点一下再进行登录,再审查元素来确定每个字的坐标就能模拟点击了(是不是豁然开朗),这个步骤自行点击来获取坐标,我把我测试好的七个文字坐标依次拿出来:[22.796875,22],[42.796875,22],[63.796875,21],[84.796875,20],[107.796875,20],[129.796875,22],[150.796875,22]。
captcha_type:这个字段就有意思了,其中有一个小技巧来切换成数字英文验证码。如果把它设置成 "cn" 就是倒立文字验证码,设置成 "en" 就是数字英文验证码,我没就这里设置成"cn",数字英文验证码网上很多,大家可自行寻找。(经测试不填这个字段也是数字英文验证码)
到这里思路就很清晰了,我们知道了这三个重要信息,就知道如何让爬虫登录知乎了,不多说直接上代码:
import requests
try:
import cookielib
except:
import http.cookiejar as cookielib
import re
import time
def get_xsrf():
# 获取xsrf code
response = session.get('https://www.zhihu.com', headers=header)
# print(response.text)
match_obj = re.match('[\s\S]*name="_xsrf" value="(.*?)"', response.text)
if match_obj:
return match_obj.group(1)
return ''
def get_captcha():
# 验证码URL是按照时间戳的方式命名的
captcha_url = 'https://www.zhihu.cdom/captcha.gif?r=%d&type=login&lang=cn' % (int(time.time() * 1000))
response = session.get(captcha_url, headers=header)
# 保存验证码到当前目录
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
# 自动打开刚获取的验证码
from PIL import Image
try:
img = Image.open('captcha.gif')
img.show()
img.close()
except:
pass
points = [[22.796875, 22], [42.796875, 22], [63.796875, 21], [84.796875, 20], [107.796875, 20], [129.796875, 22], [150.796875, 22]]
seq = input('请输入倒立字的位置\n>')
s = ''
for i in seq:
s += str(points[int(i)-1]) + ','
return '{"img_size":[200,44],"input_points":[%s]}' % s[:-1]
def zhihu_login(account, password):
# 知乎登录
if re.match('1\d{10}', account):
print('手机号码登录')
post_url = 'https://www.zhihu.com/login/phone_num'
post_data = {
'captcha_type': 'cn',
'_xsrf': get_xsrf(),
'phone_num': account,
'password': password,
'captcha': get_captcha(),
}
response_text = session.post(post_url, data=post_data, headers=header)
if __name__ == '__main__':
agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8'
header = {
'HOST': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com',
'User-agent': agent,
}
session = requests.session()
zhihu_login('输入登录的手机号', '输入登录的密码')想必大家看代码都能看的懂了,我再简单说一嘴重要的
非常要注意的地方是:必须要用session来请求验证码再用session来提交报文,为什么不能用requests呢?一个session就是一个会话,如果用一个session访问了一个网站,后面再拿着这个session再请求这个网站,它会把网站带给我们的cookie或者说网站放到字段里面的session完全的给带回去,这里面的cookie就非常重要,在我们访问知乎的时候,不管我们有没有登录,服务器都可以往我们的header里面放一些值,我们用pycharm的debug来看一下session:
可以看到里面有很多cookie,获取验证码时服务器给我们发的这些cookie,必须在登录时再传给知乎服务器才算认证成功。如果在登录时用requests,它会再建立一次session,就无法把获取验证码带来的cookies传给服务器,这样固然认证失败。
好了,大功告成!只要输入第几个文字是倒立的就行了,比如第二个和第四个文字是倒立的,输入:24 按回车后就自动添加坐标,是不是很开心!

相关文章推荐
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(1)
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
- Python爬虫倒立文字验证码登录知乎
- 如何用Python+人工识别处理知乎的倒立汉字验证码
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
- 【python爬虫03】使用Scrapy框架模拟登录知乎
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
- Python爬虫之自动登录与验证码识别
- python爬虫之自动登录与验证码识别
- python爬虫框架scrapy实现模拟登录操作示例
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
- Python 半自动登录知乎-验证码需要识别
- python爬虫实战(四)--------豆瓣网的模拟登录(模拟登录和验证码的处理----scrapy)
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
- Python 爬虫框架 scrapy
- Python的爬虫程序编写框架Scrapy入门学习教程
- Python开源爬虫框架:Scrapy架构分析