使用Python抓取网易云音乐所有歌手信息
2017-09-09 15:05
671 查看
思路
1. 构造请求页面的URL
每个页面由歌手分类和歌手名字的大写字母值构成,比如,”http://music.163.com/discover/artist/cat?id=1001&initial=65“,就是请求华语男歌手,字母为”A”的所有歌手
2. 请求数据
请求数据使用的是requests包,当请求的网址没有错误并且status_code为200时,返回网页的内容。
注意:这里并没改变请求的headers,也没有使用代理
3. 解析数据
使用lxml包进行html解析,抓取包括歌手id,name,cat,userhome四个信息
4. 存储到MongoDB
存储时将歌手id作为数据表的’_id’,由于歌手id唯一性,可以防止数据库中的文档重复插入
import requests
from requests.exceptions import RequestException
from lxml import etree
from pymongo import MongoClient
from concurrent import futures
CATS = {
'1001': '华语男歌手',
'1002': '华语女歌手',
'1003': '华语组合/乐队',
'2001': '欧美男歌手',
'2002': '欧美女歌手',
'2003': '欧美乐队/组合',
'6001': '日本男歌手',
'6002': '日本女歌手',
'6003': '日本乐队/组合',
'7001': '韩国男歌手',
'7002': '韩国女歌手',
'7003': '韩国乐队/组合',
'4001': '其他男歌手',
'4002': '其他女歌手',
'4003': '其他乐队/组合'
}
def get_artists(args):
'''
根据不同参数请求不同页面,并返回歌手信息
:param args:
:return:
'''
url = 'http://music.163.com/discover/artist/cat?id={}&initial={}'.format(args[0],arg
4000
s[1])
result = fetch(url)
if result is not None:
artists = parse(result,args[0])
return artists
def fetch(url):
'''
请求连接,成功时(200)返回页面内容
:param url:
:return:
'''
try:
resp = requests.get(url)
except RequestException:
return None
if resp.status_code == 200:
return resp.text
else:
return None
def parse(page,cat_id):
'''
页面解析,返回当前页面所有的歌手信息
:param page:
:param cat_id:
:return:
'''
html = etree.HTML(page)
ul = html.xpath('//ul[@id="m-artist-box"]')
lis = ul[0].xpath('li')
artists = []
for li in lis:
tmp = {}
href = li.xpath('a|p/a')
tmp['cat'] = CATS[cat_id]
tmp['name'] = href[0].text
# 使用'_id'存储歌手的id,能够保证插入数据的唯一性
tmp['_id'] = href[0].attrib['href'].split('=')[1]
# 如果歌手有主页的话,添加主页的信息
if len(href) == 2:
tmp['userhome'] = href[1].attrib['href']
else:
tmp['userhome'] = None
artists.append(tmp)
return artists
def get_args(hot=False):
'''
根据hot生成请求参数
:param hot:
:return:
'''
if hot is False:
initials = [i for i in range(65, 91)]
initials.append(0)
else:
initials = [-1]
return [[cat_no,initial] for cat_no in CATS.keys() for initial in initials]
def get_all_artists(hot=False):
'''
1. 初始化请求参数
2. 初始化存储信息
3. 获取并保存
:param hot:
:return:
'''
args = get_args(hot)
client = MongoClient()
db = client['py_netease']
if not hot:
artists = db['artists']
else:
artists = db['hot_artists']
# 多线程下载,用时约24秒
with futures.ThreadPoolExecutor(4) as executor:
res = executor.map(get_artists,args)
for result in res:
try:
artists.insert_many(result)
except:
pass
# 单线程下载,用时约1分33秒
# for arg in args:
# result = get_artists(arg)
# try:
# artists.insert_many(result)
# except:
# pass
if __name__ == '__main__':
get_all_artists()其他
1. 关于多线程
最简单的方法就是使用concurrent.futures包,其他也可以使用threading包。由于抓取属于IO密集型,因此使用多线程会明显改善效率。
2. 关于抓取失败
有可能是IP被禁止访问,返回503错误
3. 最后,发一下效果图,所有歌手一共有3w+条数据,而热门歌手有1500条数据
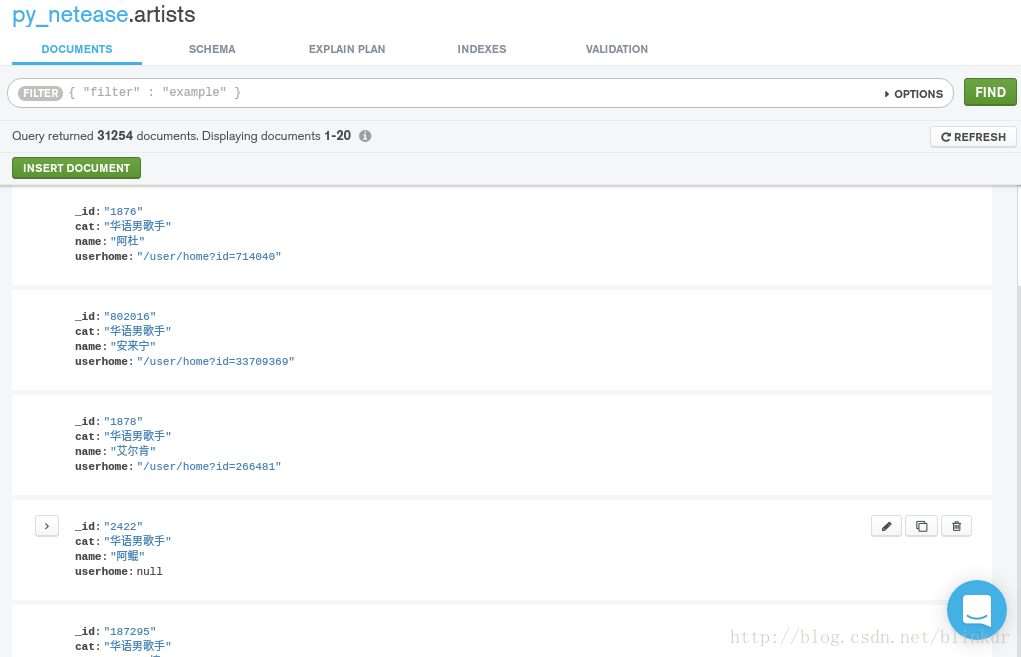
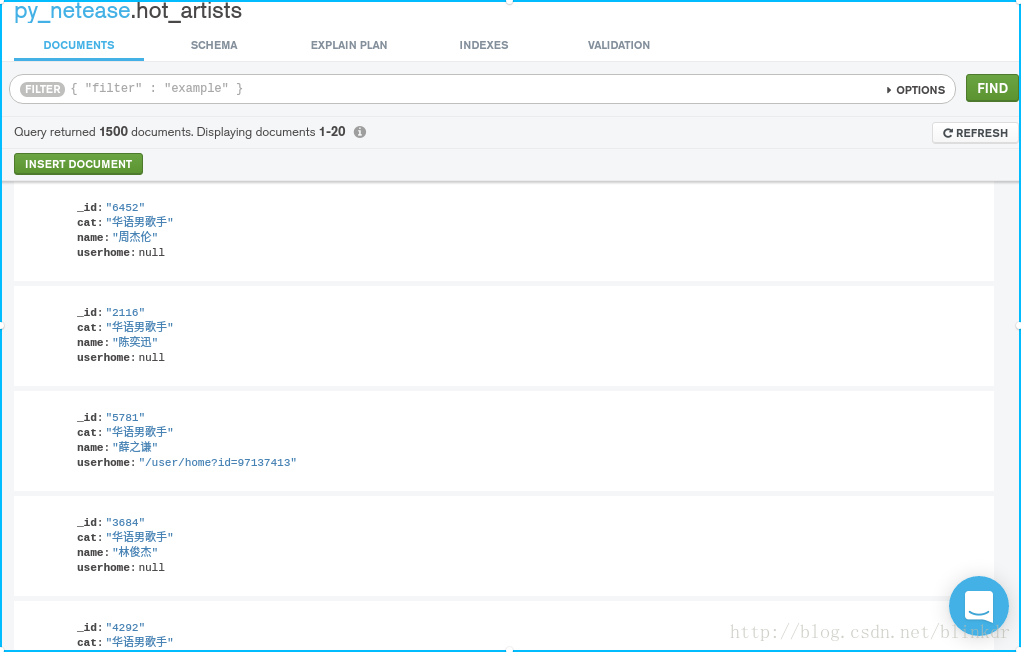

相关文章推荐
- 使用python抓取有路网图书信息(原创)
- 使用python抓取网页(以人人网新鲜事和团购网信息为例)
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- 使用Python程序抓取新浪在国内的所有IP的教程
- 使用python抓取网站信息
- 使用Python获取所有非偶数尺寸图片资源信息
- 使用python抓取网页(以人人网新鲜事和团购网信息为例)
- Python爬虫实战一之使用Beautiful Soup抓取百度招聘信息并存储excel文件
- Python使用Selenium模块模拟浏览器抓取斗鱼直播间信息示例
- 使用python抓取豆瓣电影信息
- 使用python BeautifulSoup库抓取58手机维修信息
- 使用Python抓取网页信息
- 使用Python3.x抓取58同城(南京站)的演出票的信息
- 使用Python+selenium+BeautifulSoup抓取动态网页的关键信息
- 在Python中使用cookielib和urllib2配合PyQuery抓取网页信息
- python爬虫抓取豆瓣所有恐怖片信息(利用多线程和构建免费ip代理池)
- 使用python抓取58手机维修信息
- Win7,64位,Python使用Beautiful Soup 4抓取网易云音乐歌单中的歌曲
- 使用python BeautifulSoup库抓取58手机维修信息
- 使用Python程序抓取新浪在国内的所有IP的教程