ECO论文翻译:Efficient Convolution Operators for Tracking论文翻译
2017-08-30 16:11
609 查看
近些年来,在目标追踪领域,基于判别式相关滤波(DCF)的方法明显体现了最高水平。不过,曾经追求提高包括提取特征的速度和实时性等追踪性能(的研究),已经逐渐黯然失色。在将来,越来越复杂的、并且包含大量训练参数的模型,已经引入了重度过拟合的风险(意思是,越来越复杂的模型,更容易引起很严重的过拟合)。本次工作中,我们处理复杂计算和过拟合问题背后的关键问题,并且,同时改善速度和精度。
我们回顾了 DCF 的核心公式,并介绍了以下几点: (i)、对卷积操作进行因式分解,大大地减少模型中的参数。(ii)、生成一个紧凑(简洁)的训练样本分布的模型,大大地减少内存和时间复杂度。同时,提供更好的样本多样性。(iii)、一个保守的模型更新策略,提高鲁棒性和减少复杂度。我们在以下四个基准下进行综合实验: VOT2016、UAV123、OTB-2015 和 TempleColor。当使用昂贵的深度特征,我们的追踪器提供
20 倍的加速,并且在 VOT2016挑战赛上,在 Expected Average Overlap【EAO:跟踪框zhunquelv】 方面,和排名第一的方法相比,获得了13.0%的相对增益(就是准确率提高了13%)。此外,我们一个快速的版本,使用 hand-crafted特征【即直接设计特征本身,根据仿照人类视觉的特点对什么样的特征敏感,什么样的特征不敏感提取图像中有区分能力的特征,因此提取出来的特征每一维往往都有具体的物理含义。比如sift surf等都属于】,在单CPU下以60HZ 速度,在OTB-2015上获得了65.0%的AUC。
1.Introduction
一般的视觉追踪是计算机视觉领域的基本问题之一。它是这样一种任务:只给定初始状态(即在第一帧中框选出目标),然后估计目标在图像序列中的轨迹。在线视觉追踪在许多实时视觉应用中,扮演着重要角色,比如智能监控系统、自动驾驶、无人机监控、智能交通管制、人机交互等。因为在线跟踪的本质,一个理想的追踪器应该在实时视觉系统的严格约束下,还保持精确度和鲁棒性。近些年来,基于判别式相关滤波(DCF)的一些方法 ,在追踪基准测试中,就准确性和鲁棒性而言,不断呈现出性能上的改进。近来的一些DCF方法在改善追踪性能上,有采用多维特征的、鲁棒的尺度估计、非线性内核、长期记忆元件、复杂的学习模型、减少边界效应。但是,这些在精度上的改进,都是以牺牲速度为代价。例如,由Bolme等人设计的具有开创意义的 MOSSE 滤波器,比VOT2016挑战赛中最好的DCF滤波器——C-COT速度快了1000倍,但是仅仅获得其一半的精度。
正如上文所提到的,DCF跟踪的改进版本主要归功于强大的特征和复杂的学习公式。这在本质上产生了更大的models,需要成百上千的训练参数。另一方面,如此复杂而又庞大的模型, 已经极有可能导致严重的过拟合。在这篇文章中,我们在最近的追踪器上,当恢复他们的实时能力时,处理过拟合问题。【这句话翻译的不对,原文是这样的:In this paper,we tackle the issues of over-fitting in recent
DCF trackers,while restoring their hallmark real-time capabilities.如果你有比较好的翻译,望告知】。
1.1 Motivation
我们在最先进的 DCF 追踪器上,总结出出导致计算复杂性和过拟合的三个关键因素。模型大小(Model size)[还可以理解为特征的复杂度]:高维特征图的集成,比如深度特征,会导致外观模型参数数量上的根本性的提高,(这参数的维度)往往会超过输入图像的维度。比如说,C-COT 在每次在线学习模型的时候,需要更新 800000 个参数。由于在追踪中,训练数据的固有不足,如此高维度的参数空间很容易引起过拟合。此外,这高维度还提高了计算的复杂性,进而导致较慢的跟踪速度。
训练集的大小(Trainng set size):包括C-COT在内的非常先进的DCF追踪器,由于依赖迭代优化算法,(追踪算法)需要存储一个大量的训练样本集。但在实际中,内存空间始终是有限的,特别是在使用高维度特征时。保持内存空间充足的典型策略是舍弃旧的数据。但是最新的样本特征的变化仍然会引起过拟合和模型漂移【比如说,如果目标被遮挡或者丢失,比较新的样本数据本身就是错误的】。此外,大量的训练集也增加了计算负担。
模型更新(Model update):绝大多数基于DCF的追踪器采用持续学习策略,对于每一帧,都严格地更新一次模型。相反地,最近的一些工作:使用Siamese networks【一种相似性度量方法】,不进行模型更新,也显示出较好的效果。在这些发现的推动下,我们发现,DCF 持续更新的模型对样本的突然变化非常敏感。这些变化包括尺度变化、(目标)变形和平面外的旋转。这种过度的更新策略会导致低帧率和鲁棒性的退化,因为,(追踪器)会对最新的几帧数据过拟合。
1.2 Contribution
我们提出一个新的构想,来处理上述列举的 DCF 追踪器的问题。我们的第一个贡献是:我们引入了一个分解卷积运算符,大大减少了 DCF 模型中参数的数量。第二个贡献是简化训练样本空间,有效减少了样本的数量,同时还可以保持样本的多样性。我们最后一个贡献是,引入了一个模型更新策略,同时改善了追踪速度和精度。综合实验清楚地表明,我们的方法可以同时改善速度和精度,从而在VOT2016、UAV123、OTB-2015 和 TempleColor 四个测试基准上重新设立了最高标准。和 baseline 相比,我们的方法减少了80%的模型参数,90%的训练样本和优化迭代的80%。在 VOT 2016挑战赛上,我们的方法胜过了排名第一的 C-COT,同时获得了较高的 frame-rate。
同时,我们还整出一个快速简洁版本,性能还是很不错的,在单个CPU上能跑出60FPS,从而更适合计算能力受限的机器平台。
2.Baseline Approach:C-COT
本次工作中,我们共同解决DCF追踪器中的计算复杂度和过拟合问题。我们采用之前的研究成果C-COT作为baseline.C-COT 在VOT2016挑战赛中,获得了第一名,并且在其它测试平台上表现出色。与标准DCF公式不同,Danelljan 等人提出在连续空间域学习滤波器。在C-COT中的广义公式给我们的相关工作带来了两个优点。第一个优点是,C-COT 通过在连续域中进行卷积,来使多分辨率的特征图自然集成。这使得我们可以独立灵活地选择每个视觉特征的 cell size,即分辨率,而不需要显式地重采样。第二个优点是,预测目标检测的得分,可以像连续函数一样获得,从而使子网格sub-grid 定位更准确。
现在,我们简要描述一下C-COT的公式。为了方便起见,我们采用和文献【12】相同的数学符号。【由于公式在CSDN上太难编辑,所以我在word上编辑好,然后截图】


3.Our Approach
正如前面讨论的一样,在DCF的学习中的过拟合和计算复杂性,均来自于常见的因素。因此,我们集中处理这些问题,以提高算法的速度和精度。Robust learning(鲁棒性学习):正如之前所提到的那样,因为数据集是有限的,在公式(3)中,大量的优化参数可能会引起过拟合。我们通过3.1介绍因式分解卷积滤波器来缓解这个问题,当提高追踪性能的时候,,就深度特征(deep features)来说,这个策略减少了了80%的模型参数。此外,在3.2中,我们提出一个紧凑的生成的样本滤波模型,促进样本的多样性,避免存储大量的数据集。最后,在3.3中,我们提出了模型更新策略,以较低的频率更新滤波器,从而使跟踪更鲁棒。
Computational complexity(计算复杂性): 在优化DCF算法时(比如说C-COT),学习步骤是计算瓶颈。 C-COT中的外观模型(appearance model)优化的计算复杂性是通过分析公式(5)的共轭梯度法。这复杂度是
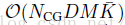
,其中,NCG是CG(共轭梯度法)的迭代次数。
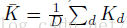
是每一个filter
channel 的傅里叶级数的平均值。最后,我们提出方法,减小D,M,和NCG
3.1 Factorized Convolution Operator(因式分解卷积)
我们是第一次介绍因式分解卷积,为的是减少参数模型的数量。我们发现,在C-COT中,学习到的滤波器 f 很多都是可以被忽略的。这对于高维的深度特征更加明显,如图2所示。这些滤波器并不会有助于目标定位,反而会影响训练时间。我们不给每一个通道 d 都分别学习出来一个滤波器,我们采用一组更小的基滤波器 f1,f2,...fC,其中 C < D。然后,特征层 d 的滤波器由基滤波器 fC和系数Pd,c组成:这个系数Pd,c可以被写成一个 D * C维的矩阵 P=(Pd,c)。接着,这新的多通道滤波器可以被表示为矩阵矢量积 Pf。我们获得因式分解卷积操作符:
【今天就先翻译到这儿吧,明天接着翻译】

相关文章推荐
- 开始翻译Fielding的博士论文
- Raft一致性算法论文的中文翻译
- 关于论文《Towards an Elastic Distributed SDN Controller》的翻译与理解
- Very Deep Convolutional Networks for Large-Scale Image Recognition—VGG论文翻译—中文版
- zZ 分布式系统领域经典论文翻译集
- 【深度学习论文翻译】Learning Spatiotemporal Features with 3D Convolutional Networks全文对照翻译
- BWA-MEM原始论文算法部分翻译
- HMM经典介绍论文【Rabiner 1989】翻译(四)——HMM的五个基本元素
- HMM经典介绍论文【Rabiner 1989】翻译(十七)——多观测序列
- fast-rcnn论文翻译
- 目标追踪——相关滤波追踪论文翻译:Visual Object Tracking using Adaptive Correlation Filters
- Raft算法官方论文中文翻译
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
- 分布式系统领域经典论文翻译集
- RCNN学习笔记(7):Faster R-CNN 英文论文翻译笔记
- Heron 论文翻译及理解
- KDD 2011 最佳工业论文中机器学习的实践方法-翻译
- 论文翻译
- 经典论文翻译导读之《Finding a needle in Haystack: Facebook’s photo storage》
- Raft算法国际论文全翻译