CNTK与深度强化学习笔记之二: Cart Pole游戏示例
2017-08-22 17:50
429 查看
如需转载,请指明出处。
上一篇文章之后,有几个问题可能是比较让人困惑的,先列举在这里,然后我们通过示例看看是如何解决的:
一开始没有任何的训练数据和标记,深度神经网络是如何被训练的呢?是不是能像上文提到的,从一堆垃圾数据里面,学到有意义的东西?
经历重放技术确实有效吗?
ε-greedy exploration算法如何实现,确实有效吗?
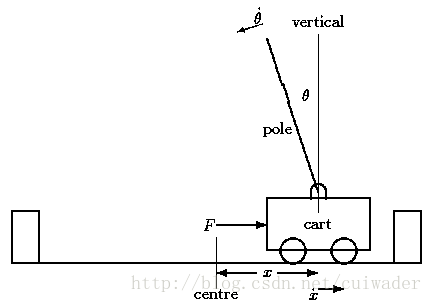
在gym的Cart Pole环境(env)里面,左移或者右移小车的action之后,env都会返回一个+1的reward。到达200个reward之后,游戏也会结束。
该环境的详细描述在这里。在这个链接里面大家可以看到别人的模型和玩的成绩。另外每个state和action值的含义也在这里:CartPole-v0 wiki。
下面几个词后面的代码会用到(通过变量名体现):
observation: 代表了对环境的观察,即环境的State
Spaces: 包括action space,表示有哪些action,和observation space,表示有哪些state。
这段代码建立了CartPole-v0的环境。n_state保存了observation数组的大小,即环境用多大的数组来表示状态。n_action保存了系统中action的数目。对于Cart Pole来说,这两个值分别是4和2。
这段代码设定了一些参数。reward_target是我们想要拿到的一局游戏中reward的总数,超过了这个总数程序就可以退出了。reward_discount是折扣率。这个游戏是一个action,马上会有一个reward,所以设置成0.99应该是比较合适的。max_epsilon,min_epsilon和epsilon_decay是为了实现上一节提到的ε-greedy exploration算法。reward_target设置为195和epoch_baseline设置为100的原因是,根据官方的定义,如果连续100个epoch的平均reward超过195,那么CartPole-v0这个问题就被认为是解决了。这样大家的成绩就有了一个衡量标准:使用的epoch越少越好。
这个类叫做Brain,就是对应的深度神经网络模型。模型的数据输入是observation,即当前的环境State。模型有两层,第一层是Dense层,即一个全连接层,有64个节点,使用RELU作为激活函数。第二个Dense层,有n_action个节点,作为模型的输出,即每个Action对应的Reward。注意这里的Action,实际上是Action的index。另外还有一个输入q_target是目标值,即最大的未来奖励。我们还定义了loss function和measure function,都是模型输出和q_target的方差。
Memory类存储了State(s),Action(a),Reward(r)和下一个State(s_)。
Agent类实现了MDP的Agent。
方法act和observe实现了ε-greedy exploration算法。初始的时候,epsilon接近1,所以act方法的“andom.random() < self.epsilon”总是为True,因此Agent总是会随机选择一个Action。随着observe执行的次数增加,step越来越大,epsilon越来越小,那么随机选择的概率越来越小,act方法会越来越多的选择Brain预测的Reward最大的Action。这正是在上一章中描述的探索和开发困境的解决方法。
方法replay从Momory中随机选择样本,然后按照batch_size构建Brain的训练数据集。这里面有一个可能让人困惑的地方是“t = p[0][i]”,为啥要先取0这个index。这个是因为predict方法调用的CNTK的eval方法,返回的是一个list,而0这个index下面包含了shape为(batch_size, n_action)的数组。另外t[a]的赋值,用到了上一章说的折扣的未来奖励的概念。这里我们还可以看到,Brain的训练数据,是从Memory中取样,并且使用了Brain自己的predict方法,为每一个采样的(s, a)产生新的Reward,即最大的未来奖励,然后再用这些(s, a)去训练模型。
run方法运行一次游戏。首先重置游戏环境,然后不停的用act方法从agent中读取一个动作,用step方法输入到游戏环境,拿到环境的反馈,用observe和replay方法将反馈更新到Agent并且训练神经网络模型,直到游戏结束。这里我们也可以看到上一章讲的经历重放:每一个Action之后,新的(s, a, r, s_)会被observe,即添加到Memory,然后会随机从Memory抽取batch_size个样本进行模型训练。
最后循环调用run方法,不停的玩游戏,直到按照gym的定义,CartPole-v0问题被解决了。按照目前的算法,大概需要2500个epoch才能解决问题(在gym的官网,一个叫Svalorzen的用户,用了42个epoch就解决了这个问题)。在调用的过程中,通过log我们可以发现,随着玩游戏的局数增加,Brain的能力确实在增强。所以Brain确实是从不会玩游戏,到玩2500次游戏之后,就玩得很好了。第一个epoch的时候,动作完全是随机的,有戏可能很快就结束了,这样的未来奖励会很低。通过选择高未来奖励的Action,Brain玩游戏的能力也越来越强。同样未来奖励也不断在增加。
最后再强调一下(如果你还没有意识到),我们在Agent的replay方法中,准备训练数据y的时候,给出的值的含义,实际上是在当前State,采取Action之后,能得到的最大的未来奖励Reward,参看上一章的贝尔曼方程。Brain的输出,实际上是去逼近这个值。这样本章开头的问题应该都被解决了。
前言
前面一篇文章,CNTK与深度强化学习笔记之一: 环境搭建和基本概念,非常概要的介绍了CNTK,深度强化学习和DQN的一些基本概念。这些概念希望后面还有文章继续展开深入:),但是只看理论不写代码,很容易让人迷惑。学习应该是一个理论和实践反复的过程。上一章的公式太多,这一章没有公式,只有代码。建议大家这两章来回看,把理论和代码对应起来。我们先来一个简单的例子看一下。这个例子来自CNTK的官方文档:CNTK 203: Reinforcement Learning Basics,做了一些修改。上一篇文章之后,有几个问题可能是比较让人困惑的,先列举在这里,然后我们通过示例看看是如何解决的:
一开始没有任何的训练数据和标记,深度神经网络是如何被训练的呢?是不是能像上文提到的,从一堆垃圾数据里面,学到有意义的东西?
经历重放技术确实有效吗?
ε-greedy exploration算法如何实现,确实有效吗?
gym的Cart Pole环境
Cart Pole在OpenAI的gym模拟器里面,是相对比较简单的一个游戏。游戏里面有一个小车,上有竖着一根杆子。小车需要左右移动来保持杆子竖直。如果杆子倾斜的角度大于15°,那么游戏结束。小车也不能移动出一个范围(中间到两边各2.4个单位长度)。如下图所示:在gym的Cart Pole环境(env)里面,左移或者右移小车的action之后,env都会返回一个+1的reward。到达200个reward之后,游戏也会结束。
该环境的详细描述在这里。在这个链接里面大家可以看到别人的模型和玩的成绩。另外每个state和action值的含义也在这里:CartPole-v0 wiki。
下面几个词后面的代码会用到(通过变量名体现):
observation: 代表了对环境的观察,即环境的State
Spaces: 包括action space,表示有哪些action,和observation space,表示有哪些state。
CNTK的DQN模型实现
针对这个游戏和DQN,我们来看看如何实现模型。下面分段讲解代码。准备工作
import numpy as np
import math
import os
import random
import gym
import cntk as C
env = gym.make('CartPole-v0')
n_state = env.observation_space.shape[0]
n_action = env.action_space.n
print('CartPole-v0 environment: %d states, %d actions' % (n_state, n_action))这段代码建立了CartPole-v0的环境。n_state保存了observation数组的大小,即环境用多大的数组来表示状态。n_action保存了系统中action的数目。对于Cart Pole来说,这两个值分别是4和2。
reward_target = 195 epoch_baseline = 100 reward_discount = 0.99 hidden_size = 64 # hidden layer size batch_size = 64 learning_rate = 0.00025 max_epsilon = 1 min_epsilon = 0.01 epsilon_decay = 0.0001
这段代码设定了一些参数。reward_target是我们想要拿到的一局游戏中reward的总数,超过了这个总数程序就可以退出了。reward_discount是折扣率。这个游戏是一个action,马上会有一个reward,所以设置成0.99应该是比较合适的。max_epsilon,min_epsilon和epsilon_decay是为了实现上一节提到的ε-greedy exploration算法。reward_target设置为195和epoch_baseline设置为100的原因是,根据官方的定义,如果连续100个epoch的平均reward超过195,那么CartPole-v0这个问题就被认为是解决了。这样大家的成绩就有了一个衡量标准:使用的epoch越少越好。
Brain
class Brain:
def __init__(self):
self.params = {}
self.model, self.trainer, self.loss = self._create()
def _create(self):
observation = C.sequence.input_variable(n_state, np.float32, name='s')
q_target = C.sequence.input_variable(n_action, np.float32, name='q')
l1 = C.layers.Dense(hidden_size, activation=C.relu)
l2 = C.layers.Dense(n_action)
unbound_model = C.layers.Sequential([l1, l2])
self.model = unbound_model(observation)
self.params = dict(W1=l1.W, b1=l1.b, W2=l2.W, b2=l2.b)
self.loss = C.reduce_mean(C.square(self.model-q_target), axis=0)
meas = C.reduce_mean(C.square(self.model-q_target), axis=0)
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(self.model.parameters,
lr_schedule,
gradient_clipping_threshold_per_sample=10)
progress_printer = C.logging.ProgressPrinter(500)
self.trainer = C.Trainer(self.model, (self.loss, meas), learner, progress_printer)
return self.model, self.trainer, self.loss
def train(self, x, y):
arguments = dict(zip(self.loss.arguments, [x,y]))
updated, results = self.trainer.train_minibatch(arguments, outputs=[self.loss.output])
def predict(self, s):
return self.model.eval([s])这个类叫做Brain,就是对应的深度神经网络模型。模型的数据输入是observation,即当前的环境State。模型有两层,第一层是Dense层,即一个全连接层,有64个节点,使用RELU作为激活函数。第二个Dense层,有n_action个节点,作为模型的输出,即每个Action对应的Reward。注意这里的Action,实际上是Action的index。另外还有一个输入q_target是目标值,即最大的未来奖励。我们还定义了loss function和measure function,都是模型输出和q_target的方差。
Memory
class Memory: # stored as ( s, a, r, s_ ) samples = [] def __init(self): pass def add(self, sample): self.samples.append(sample) def sample(self, n): n = min(n, len(self.samples)) return random.sample(self.samples, n)
Memory类存储了State(s),Action(a),Reward(r)和下一个State(s_)。
Agent
class Agent: steps = 0 epsilon = max_epsilon def __init__(self): self.brain = Brain() self.memory = Memory() def act(self, s): if random.random() < self.epsilon: return random.randint(0, n_action-1) else: return np.argmax(self.brain.predict(s)) def observe(self, sample): # in (s, a, r, s_) format self.memory.add(sample) self.steps += 1 self.epsilon = min_epsilon + (max_epsilon - min_epsilon) * math.exp(-epsilon_decay * self.steps) def replay(self): batch = self.memory.sample(batch_size) no_state = np.zeros(n_state) states = np.array([ o[0] for o in batch ], dtype=np.float32) states_ = np.array([ (no_state if o[3] is None else o[3]) for o in batch ], dtype=np.float32) p = self.brain.predict(states) p_ = self.brain.predict((states_)) x = np.zeros((len(batch), n_state)).astype(np.float32) y = np.zeros((len(batch), n_action)).astype(np.float32) for i in range(len(batch)): s, a, r, s_ = batch[i] t = p[0][i] # CNTK: [0] because of sequence dimension if s_ is None: t[a] = r else: t[a] = r + reward_discount * np.amax(p_[0][i]) bcb8 x[i] = s y[i] = t self.brain.train(x, y)
Agent类实现了MDP的Agent。
方法act和observe实现了ε-greedy exploration算法。初始的时候,epsilon接近1,所以act方法的“andom.random() < self.epsilon”总是为True,因此Agent总是会随机选择一个Action。随着observe执行的次数增加,step越来越大,epsilon越来越小,那么随机选择的概率越来越小,act方法会越来越多的选择Brain预测的Reward最大的Action。这正是在上一章中描述的探索和开发困境的解决方法。
方法replay从Momory中随机选择样本,然后按照batch_size构建Brain的训练数据集。这里面有一个可能让人困惑的地方是“t = p[0][i]”,为啥要先取0这个index。这个是因为predict方法调用的CNTK的eval方法,返回的是一个list,而0这个index下面包含了shape为(batch_size, n_action)的数组。另外t[a]的赋值,用到了上一章说的折扣的未来奖励的概念。这里我们还可以看到,Brain的训练数据,是从Memory中取样,并且使用了Brain自己的predict方法,为每一个采样的(s, a)产生新的Reward,即最大的未来奖励,然后再用这些(s, a)去训练模型。
run
def run(agent):
s = env.reset()
R = 0
while True:
env.render()
a = agent.act(s.astype(np.float32))
s_, r, done, info = env.step(a)
if done:
s_ = None
agent.observe((s, a, r, s_))
agent.replay()
s = s_
R += r
if done:
return R
agent = Agent()
epoch = 0
reward_sum = 0
while epoch < 30000:
reward = run(agent)
reward_sum += reward
epoch += 1
if epoch % epoch_baseline == 0:
print('Epoch %d, average reward is %f, memory size is %d'
% (epoch, reward_sum / epoch_baseline, len(agent.memory.samples)))
if reward_sum / epoch_baseline > reward_target:
print('Task solved in %d epoch' % epoch)
break
reward_sum = 0run方法运行一次游戏。首先重置游戏环境,然后不停的用act方法从agent中读取一个动作,用step方法输入到游戏环境,拿到环境的反馈,用observe和replay方法将反馈更新到Agent并且训练神经网络模型,直到游戏结束。这里我们也可以看到上一章讲的经历重放:每一个Action之后,新的(s, a, r, s_)会被observe,即添加到Memory,然后会随机从Memory抽取batch_size个样本进行模型训练。
最后循环调用run方法,不停的玩游戏,直到按照gym的定义,CartPole-v0问题被解决了。按照目前的算法,大概需要2500个epoch才能解决问题(在gym的官网,一个叫Svalorzen的用户,用了42个epoch就解决了这个问题)。在调用的过程中,通过log我们可以发现,随着玩游戏的局数增加,Brain的能力确实在增强。所以Brain确实是从不会玩游戏,到玩2500次游戏之后,就玩得很好了。第一个epoch的时候,动作完全是随机的,有戏可能很快就结束了,这样的未来奖励会很低。通过选择高未来奖励的Action,Brain玩游戏的能力也越来越强。同样未来奖励也不断在增加。
最后再强调一下(如果你还没有意识到),我们在Agent的replay方法中,准备训练数据y的时候,给出的值的含义,实际上是在当前State,采取Action之后,能得到的最大的未来奖励Reward,参看上一章的贝尔曼方程。Brain的输出,实际上是去逼近这个值。这样本章开头的问题应该都被解决了。

相关文章推荐
- 深度强化学习入门:用TensorFlow构建你的第一个游戏AI
- anychart学习笔记之二获取数据源及简单示例
- 七月算法深度学习 第三期 学习笔记-第九节 强化学习与Deep Q-Network
- tensorflow40《TensorFlow实战》笔记-08-01 TensorFlow实现深度强化学习-策略网络 code
- tensorflow41《TensorFlow实战》笔记-08-02 TensorFlow实现深度强化学习-估值网络 code
- 【深度学习介绍系列之二】——深度强化学习:卷积神经网络
- 深入浅出的强化学习笔记(二)——使用OpenAI Gym实现游戏AI
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
- Windows游戏开发学习笔记之二
- MyBatis增删改示例——MyBatis学习笔记之二
- 【深度学习】学习笔记:Caffe上配置和运行Cifar10的示例
- Log4j2官方文档翻译、学习笔记之二——Appender的分类及常用类型示例
- 计算机视觉学习笔记:深度学习基础——CS231n_assignment1
- 【JfaceTextFramework学习笔记之二】内容提示
- Java NIO学习笔记之二-图解ByteBuffer
- Python学习笔记之二——Python的运行机制
- EX07学习笔记之二:安装之后(2)-安全配置向导
- 【 Visual C++】游戏开发笔记之二——最简单的DirectX,vc窗口的编写
- Deep Learning(深度学习)学习笔记整理系列之(二)
- JQuery 学习笔记 选择器之二