Machine Learning - II. Linear Regression with One Variable单变量线性回归 (Week 1)
2017-08-14 00:00
513 查看
http://blog.csdn.net/pipisorry/article/details/43115525
机器学习Machine Learning - Andrew NG courses学习笔记
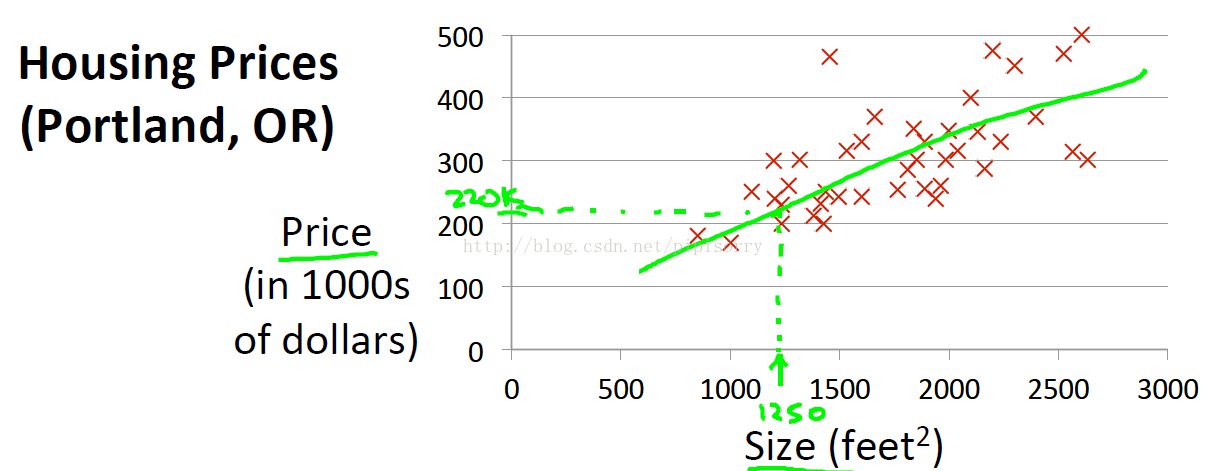
这是单变量线性回归Univariate linear regression。
变量定义Notation(术语terminology):
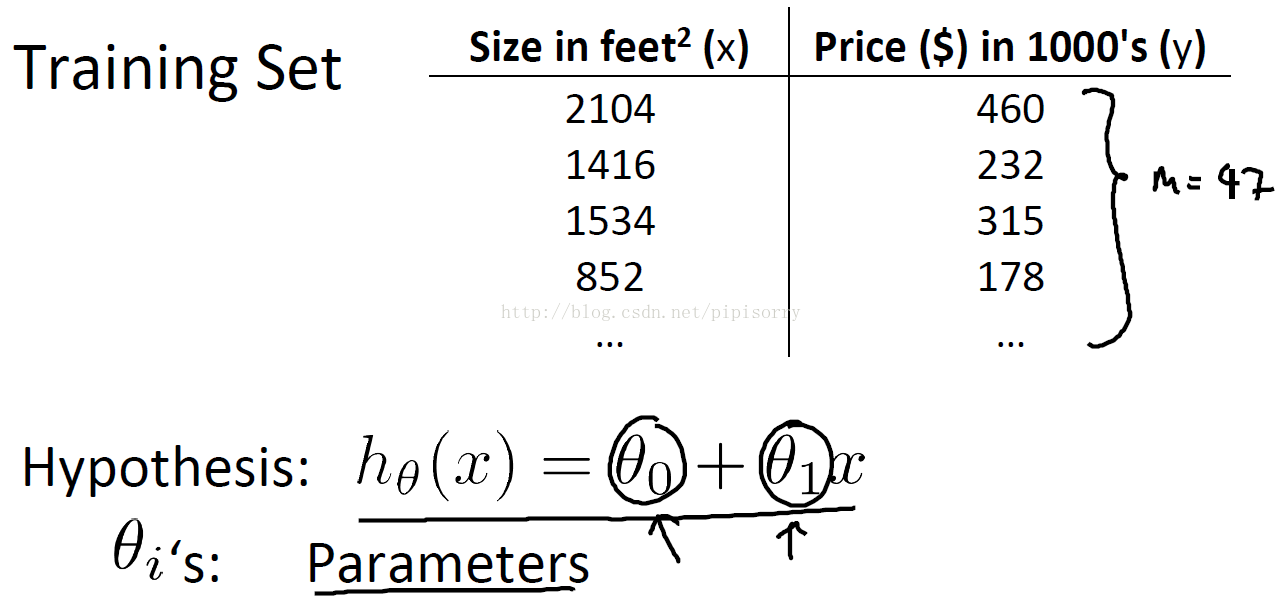
m = Number of training examples
x’s = “input” variable / features
y’s = “output” variable / “target” variable
e.g. (x,y)表示一个trainning example 而 (xi,yi)表示ith trainning example.
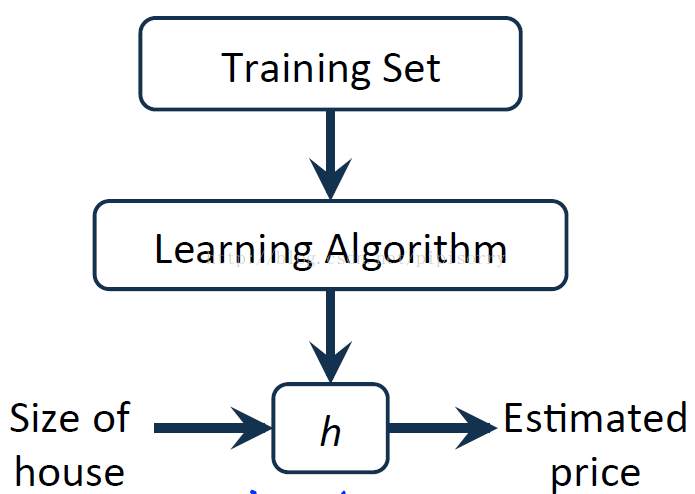
Model representation
成本函数cost function
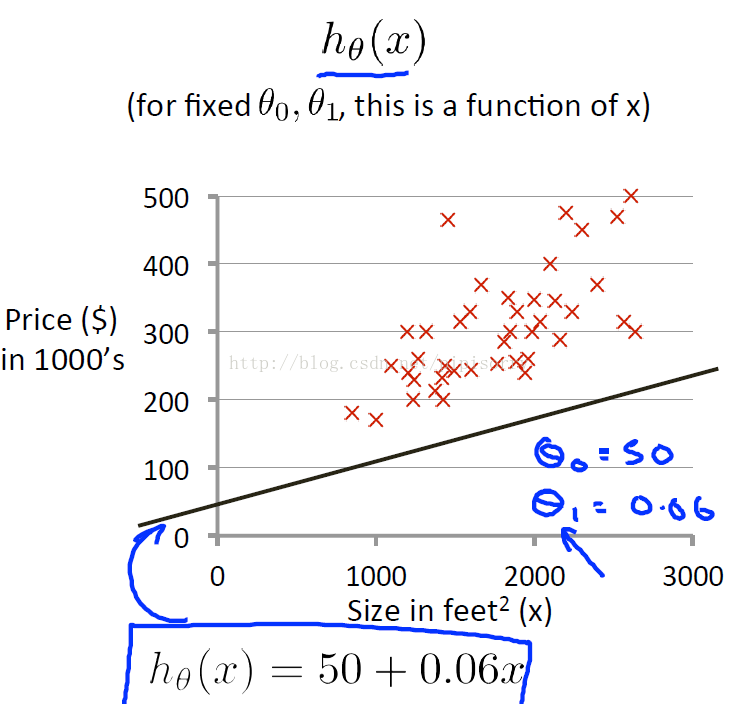
上个例子中h设为下图中的式子,我们要做的是
how to go about choosing these parameter values, theta zero and theta one.
try to minimize the square difference between the output of the hypothesis and the actual price of the house.
the mathematical definition of the cost function
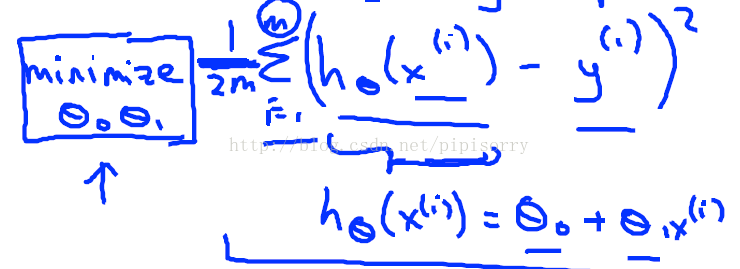
定义这个函数为(J函数就是cost function的一种)
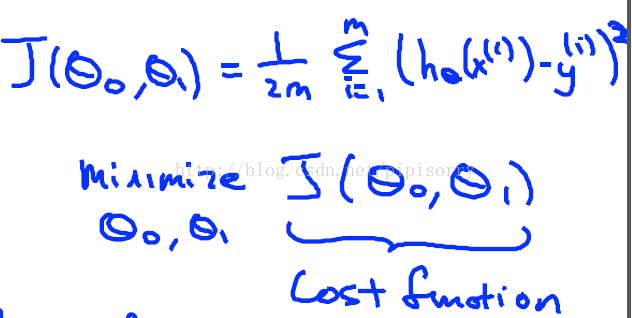
why do we minimize one by 2M?
going to minimize one by 2M.Putting the 2, the constant one half, in front it just makes some of the math a little easier.
why do we take the squares of the errors?
It turns out that the squared error cost function is a reasonable choice and will work well for most problems, for most regression problems. There are other cost functions that will work pretty well, but the squared error cost function is probably the most commonly used one for regression problems.
cost function intuition I

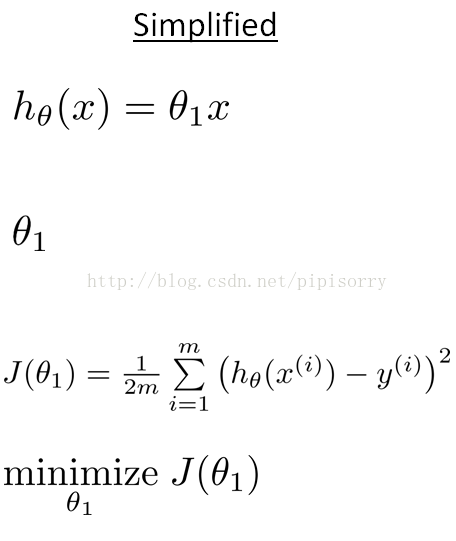
{简化起见:将theta0设为0, 即h函数过原点}
Each value of theta one corresponds to a different hypothesis, or to a different straight line fit on the left. And for each value of theta one, we could then derive a different value of j of theta one.
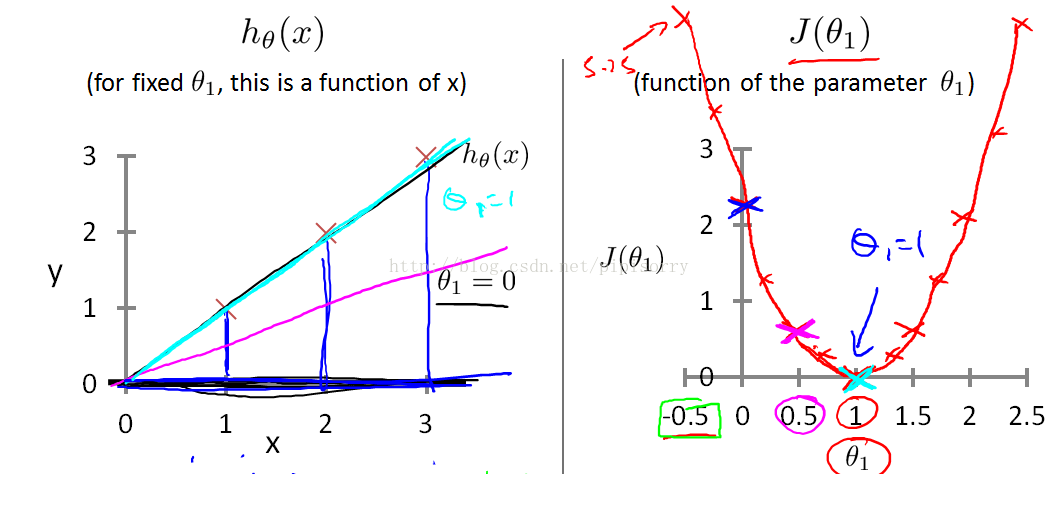
for example, theta one=1,corresponded to this straight line through the data. for each value of theta one we wound up with a different value of J of theta one
cost function intuition II
在这里我们又keep both of my parameters, theta zero, and theta one.
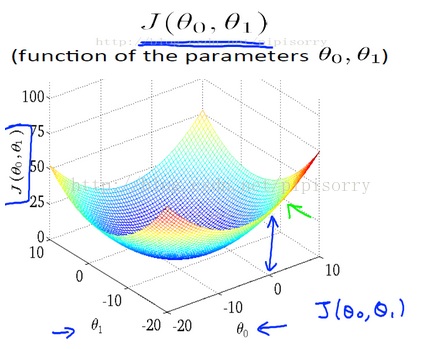
cost function用3D图表示(不同theta0\theta1取值下h(x)图形和cost fun J的变化)
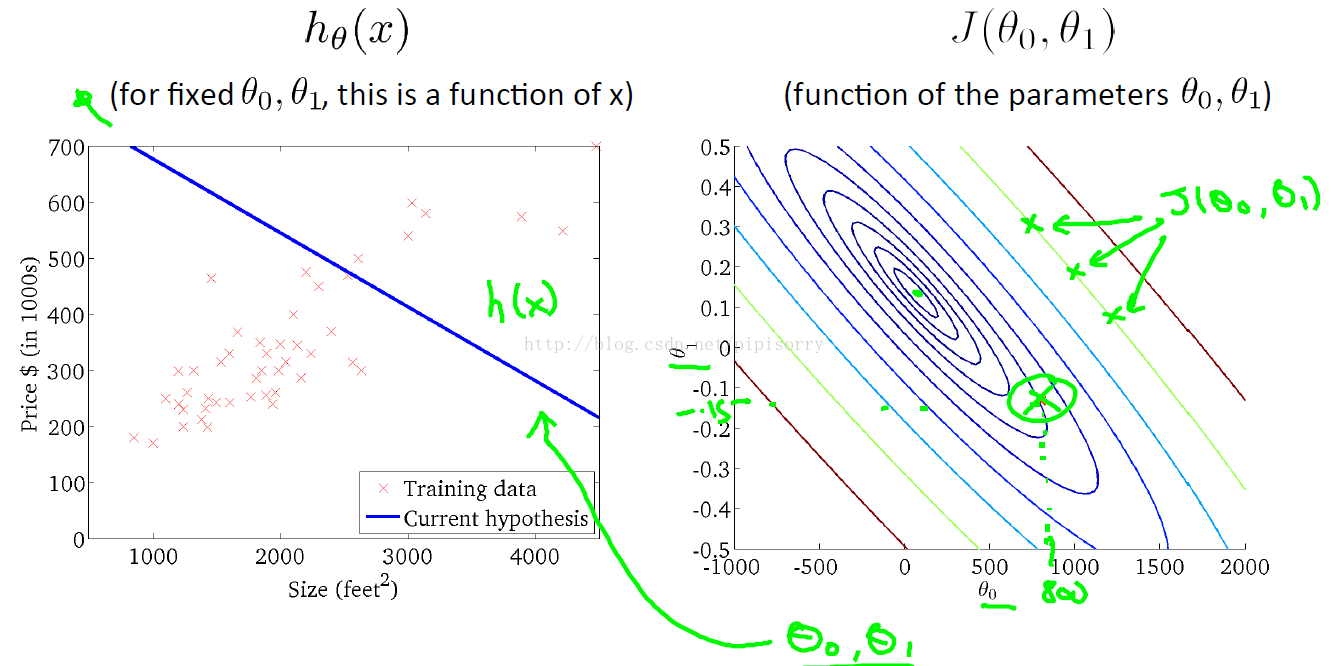
cost function用等高线图contour plot/figure表示
梯度下降Gradient descent
问题:

解决:

(将gradient descent应用到linear regression中)

对linear regression model中的cost func求偏导
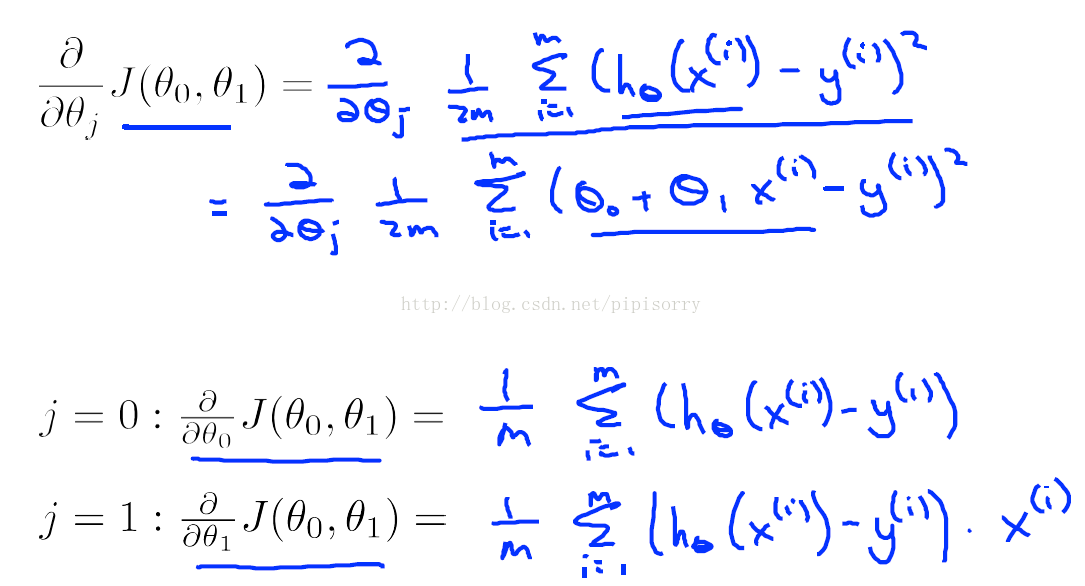
求偏导结果代入gradient descent algorithm中

local optima
(linear regression中应用gradient descent没有局部极小值问题)
One of the issues we solved gradient descent is that it can be susceptible to local optima.
depending on where you're initializing, you can end up with different local optima.
But, it turns out that the cost function for gradient of cost function for linear regression is always going to be abow-shaped function like this.
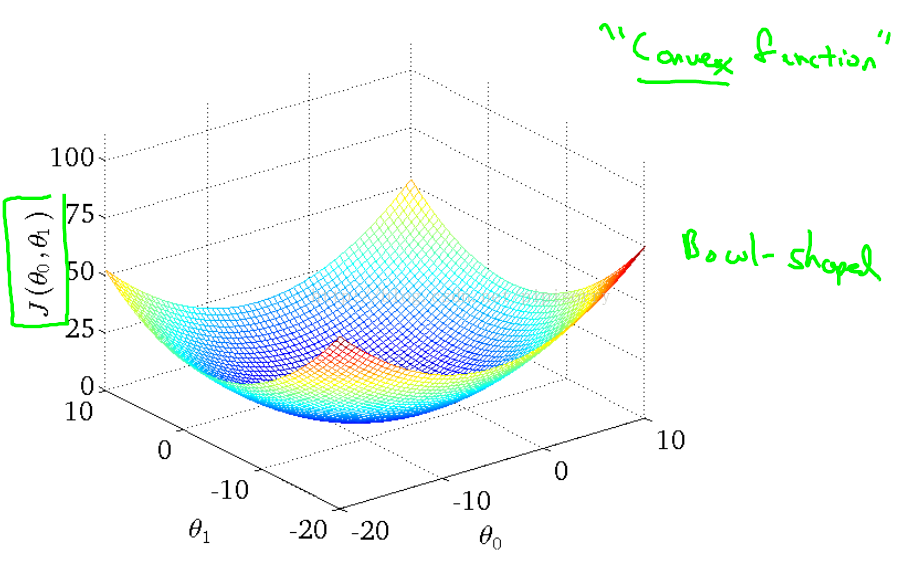
The technical term for this is that this is called a convex function.
informally a convex function means a bow-shaped function, this function doesn't have any local optima, except for the one global optimum.
And does gradient descent on this type of cost function which you get whenever you're using linear regression, it will always convert to the global optimum, because there are no other local optima other than global optimum.
算法迭代过程
(如右图沿梯度负方向下降,直到最小值点【左图是theta取值对应的函数图像】)
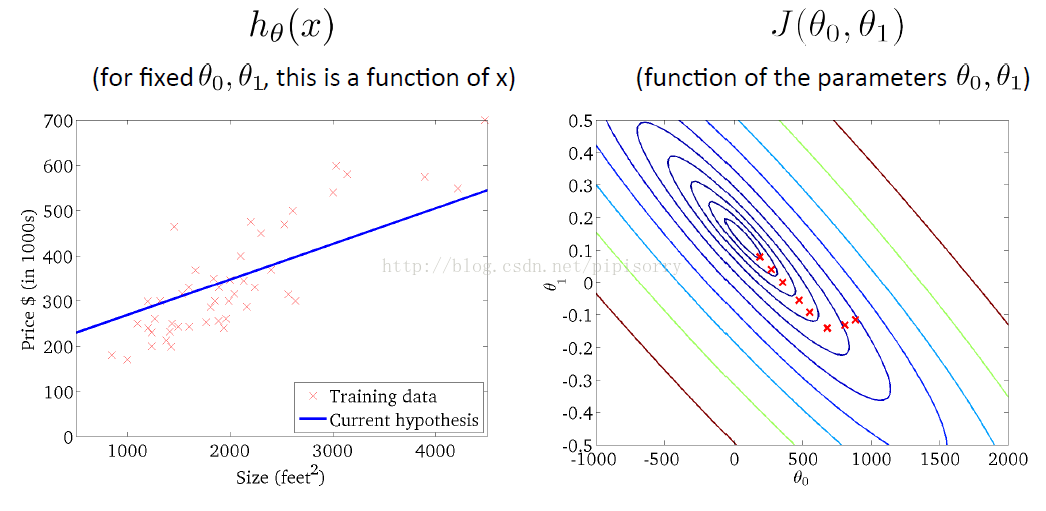
batch gradient descent
(上面gradient descent方法的别名)
the algorithm that we just went over is sometimes called batch gradient descent, means that refers to the fact that, in every step of gradient descent we're looking at all of the training examples.

随机梯度下降参见:Machine Learning - XVII. Large Scale Machine Learning大规模机器学习 (Week 10)
Cost func最小值求解的其它方法
gradient descent V.S. normal equals method(直接求解cost func最小值)
there exists a solution for numerically solving for the minimum of the cost function J, without needing to use and iterative algorithm like gradient descent that we had to iterate multiple times.And there is no longer a learning rate alpha that you need to worry about and set. And so it can be much faster for some problems.
out gradient descent will scale better to larger data sets than that normal equals method.
数据量小的时候,可以对cost func求偏导,然后联立方程组,求解每个theta的值(就如最小二乘法一样);
但是当数据量大的时候(如下图中feature有好多个,就得用多个theta建立一个更复杂的函数J),方程组过大,求解几乎无法进行,就得用gradient descent通过迭代的方法解决。
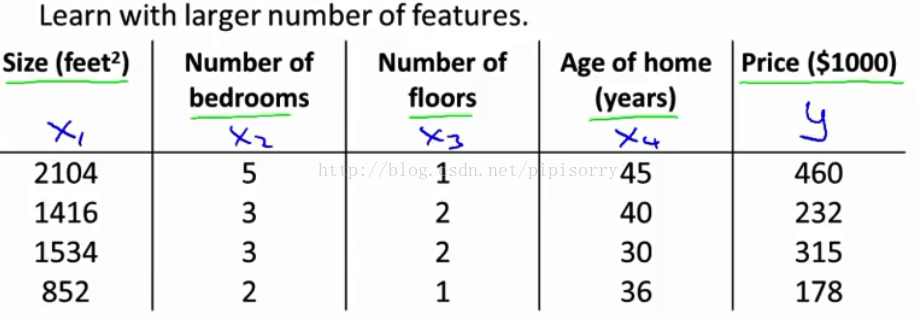
【Linear Regression with Multiple Variables】
from:http://blog.csdn.net/pipisorry/article/details/43115525
ref:《10 types of regressions. Which one to use?》10种回归类型介绍以及如何选择
[《A Neat Trick to Increase Robustness of Regression Models | CleverTap Blog》by Jacob Joseph]
机器学习Machine Learning - Andrew NG courses学习笔记
Linear regression with one variable单变量线性回归
模型表示Model representation
预测房价示例这是单变量线性回归Univariate linear regression。
变量定义Notation(术语terminology):
m = Number of training examples
x’s = “input” variable / features
y’s = “output” variable / “target” variable
e.g. (x,y)表示一个trainning example 而 (xi,yi)表示ith trainning example.
Model representation
成本函数cost function
上个例子中h设为下图中的式子,我们要做的是how to go about choosing these parameter values, theta zero and theta one.
try to minimize the square difference between the output of the hypothesis and the actual price of the house.
the mathematical definition of the cost function
定义这个函数为(J函数就是cost function的一种)
why do we minimize one by 2M?
going to minimize one by 2M.Putting the 2, the constant one half, in front it just makes some of the math a little easier.
why do we take the squares of the errors?
It turns out that the squared error cost function is a reasonable choice and will work well for most problems, for most regression problems. There are other cost functions that will work pretty well, but the squared error cost function is probably the most commonly used one for regression problems.
cost function intuition I
{简化起见:将theta0设为0, 即h函数过原点}
Each value of theta one corresponds to a different hypothesis, or to a different straight line fit on the left. And for each value of theta one, we could then derive a different value of j of theta one.
for example, theta one=1,corresponded to this straight line through the data. for each value of theta one we wound up with a different value of J of theta one
cost function intuition II
在这里我们又keep both of my parameters, theta zero, and theta one.
cost function用3D图表示(不同theta0\theta1取值下h(x)图形和cost fun J的变化)
cost function用等高线图contour plot/figure表示
梯度下降Gradient descent
问题:
解决:
梯度下降算法
[最优化方法:梯度下降(批梯度下降和随机梯度下降) ]线性回归的梯度下降求解
apply gradient descent to minimize our squared error cost function in linear regression.(将gradient descent应用到linear regression中)
对linear regression model中的cost func求偏导
求偏导结果代入gradient descent algorithm中
local optima
(linear regression中应用gradient descent没有局部极小值问题)
One of the issues we solved gradient descent is that it can be susceptible to local optima.
depending on where you're initializing, you can end up with different local optima.
But, it turns out that the cost function for gradient of cost function for linear regression is always going to be abow-shaped function like this.
The technical term for this is that this is called a convex function.
informally a convex function means a bow-shaped function, this function doesn't have any local optima, except for the one global optimum.
And does gradient descent on this type of cost function which you get whenever you're using linear regression, it will always convert to the global optimum, because there are no other local optima other than global optimum.
算法迭代过程
(如右图沿梯度负方向下降,直到最小值点【左图是theta取值对应的函数图像】)
batch gradient descent
(上面gradient descent方法的别名)
the algorithm that we just went over is sometimes called batch gradient descent, means that refers to the fact that, in every step of gradient descent we're looking at all of the training examples.
随机梯度下降参见:Machine Learning - XVII. Large Scale Machine Learning大规模机器学习 (Week 10)
Cost func最小值求解的其它方法
gradient descent V.S. normal equals method(直接求解cost func最小值)there exists a solution for numerically solving for the minimum of the cost function J, without needing to use and iterative algorithm like gradient descent that we had to iterate multiple times.And there is no longer a learning rate alpha that you need to worry about and set. And so it can be much faster for some problems.
out gradient descent will scale better to larger data sets than that normal equals method.
数据量小的时候,可以对cost func求偏导,然后联立方程组,求解每个theta的值(就如最小二乘法一样);
但是当数据量大的时候(如下图中feature有好多个,就得用多个theta建立一个更复杂的函数J),方程组过大,求解几乎无法进行,就得用gradient descent通过迭代的方法解决。
【Linear Regression with Multiple Variables】
from:http://blog.csdn.net/pipisorry/article/details/43115525
ref:《10 types of regressions. Which one to use?》10种回归类型介绍以及如何选择
[《A Neat Trick to Increase Robustness of Regression Models | CleverTap Blog》by Jacob Joseph]

相关文章推荐
- Machine Learning - II. Linear Regression with One Variable单变量线性回归 (Week 1)
- Stanford公开课机器学习---week1-2.单变量线性回归(Linear Regression with One Variable)
- 斯坦福大学ML(2)单变量线性回归(Linear Regression with One Variable)
- Coursera公开课笔记: 斯坦福大学机器学习第二课“单变量线性回归(Linear regression with one variable)”
- 机器学习第2课:单变量线性回归(Linear Regression with One Variable)
- 斯坦福机器学习实验之1-单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- Linear Regression with one variable 单变量线性回归
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- Standford 机器学习—第一讲 Linear Regression with one variable(单变量线性回归)
- Coursera公开课笔记: 斯坦福大学机器学习第二课“单变量线性回归(Linear regression with one variable)”
- Coursera公开课笔记: 斯坦福大学机器学习第二课“单变量线性回归(Linear regression with one variable)”
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- 机器学习 Machine Learning(by Andrew Ng)----第二章 单变量线性回归(Linear Regression with One Variable)
- Stanford ML - Linear regression with one variable 单变量线性回归
- Coursera《machine learning》--(2)单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- Andrew NG机器学习课程笔记系列之——机器学习之单变量线性回归(Linear Regression with One Variable)