Standford 机器学习—第一讲 Linear Regression with one variable(单变量线性回归)
2017-03-11 16:29
477 查看
Linear Regression with one variable(单变量线性回归)
Linear Regression with one variable单变量线性回归什么是线性回归
代价函数 cost function
公式
作用
Gradient Descent 梯度下降算法
Batch gradient descent 批量梯度下降
公式
学习率alpha的大小
对代价函数求导
本栏目(Machine learning)包括单参数的线性回归、多参数的线性回归、Octave Tutorial
4000
、Logistic Regression、Regularization、神经网络、机器学习系统设计、SVM(Support Vector Machines 支持向量机)、聚类、降维、异常检测、大规模机器学习等章节。所有内容均来自Standford公开课machine learning中Andrew NG老师的讲解。
什么是线性回归
线性回归是给出一系列点假设拟合直线为h(x)=θ0+θ1x, 记Cost Function为J(θ0,θ1)之所以说单参数是因为只有一个变量x,即影响回归参数θ1,θ0的是一维变量,或者说输入变量只有一维属性。
代价函数 cost function
1. 公式:
J(θ0,θ1)=12m∑i=1m(hθ(x(i))−y(i))22. 作用:
能够帮助我们找到最适合我们训练集的线。代价函数也叫作平方误差函数。对大多数问题,特别是回归问题,是一个合理的选择。Gradient Descent 梯度下降算法
梯度下降是用来求最小值的算法,我们可以用这个算法来求出代价函数J(θ0,θ1) 最小值思路:
将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快。
Batch gradient descent 批量梯度下降
1. 公式:
θj:=θj−α∂∂θjJ(θ0,θ1) for j=0 and j=1其中α表示学习率(learning rate), 决定了下降的速度有多快。
注意:必须同时更新θ0和θ1
具体更新如下:
temp0:=θ0−α∂∂θjJ(θ0,θ1)
temp1:=θ1−α∂∂θjJ(θ0,θ1)
θ0:=temp0
θ1:=temp1
2. 学习率α的大小
如果α太小,那么会导致速度很慢,需要很多步骤才能找到全局最低点。如果α太大,那么梯度下降算法可能会越过最低点,导致结果无法收敛,甚至发散
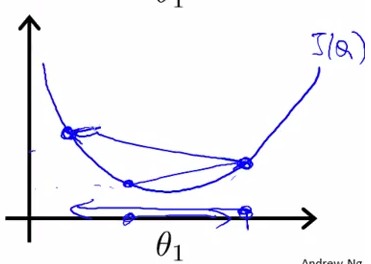
问题:如果θ1初始化在局部最低点,梯度下降算法会怎样工作?
答:θ1在局部最低点,表示倒数等于0,斜率为0,梯度下降算法将什么都不做
3.对代价函数求导
θ0:=θ0−α1m∑i=1m(hθ(x(i))−y(i))θ1:=θ1−α1m∑i=1m((hθ(x(i))−y(i))∗x(i))

相关文章推荐
- Stanford公开课机器学习---week1-2.单变量线性回归(Linear Regression with One Variable)
- Coursera公开课笔记: 斯坦福大学机器学习第二课“单变量线性回归(Linear regression with one variable)”
- 机器学习第2课:单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- 机器学习 Machine Learning(by Andrew Ng)----第二章 单变量线性回归(Linear Regression with One Variable)
- Coursera公开课笔记: 斯坦福大学机器学习第二课“单变量线性回归(Linear regression with one variable)”
- Andrew NG机器学习课程笔记系列之——机器学习之单变量线性回归(Linear Regression with One Variable)
- Coursera公开课笔记: 斯坦福大学机器学习第二课“单变量线性回归(Linear regression with one variable)”
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- Coursera《machine learning》--(2)单变量线性回归(Linear Regression with One Variable)
- Stanford机器学习网络课程---第一讲. Linear Regression with one variable
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
- Stanford机器学习---第一讲. Linear Regression with one variable(补充版)
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
- 斯坦福机器学习实验之1-单变量线性回归(Linear Regression with One Variable)
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable