HDFS概述
2017-08-11 06:54
211 查看
HDFS概述
标签(空格分隔): 大数据 Hadoop HDFS一、HDFS概念
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。二、HDFS架构
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。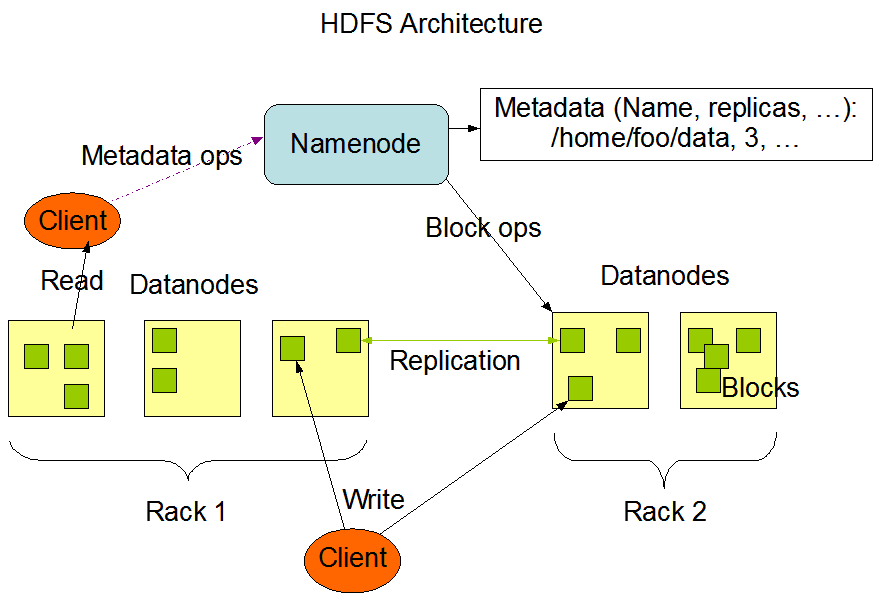
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
HDFS读写文件的过程
文件读取过程使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
客户端开发库会选取离客户端最接近的datanode来读取block;
读取完当前block的数据后,关闭与当前的datanode连接,并为读取下一个block寻找最佳的datanode;
当读完列表的bloc
93d9
k后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
写入文件过程
使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以”data queue”的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着”ack queue”,成功收到datanode返回的ack packet后会从”ack queue”移除相应的packet。
如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。

相关文章推荐
- hdfs源码namenode部分概述(二)
- (4). hdfs数据写过程概述
- HDFS概述(5)————HDFS HA
- HDFS概述(6)————用户手册
- HDFS的文件操作流(1)——写操作(客户端概述)
- (5).hdfs数据读过程概述
- HDFS 架构概述
- HDFS概述(3)————HDFS Federation
- hdfs源码namenode部分概述(一)
- hadoop hdfs总结 NameNode部分-- 概述
- HDFS:NameNode概述,DataNode 概述
- HDFS源码分析一-概述
- HDFS概述(2)————Block块大小设置
- hadoop hdfs总结 NameNode部分-- 概述
- HDFS源码分析(1)----HDFS概述
- HDFS概述
- HDFS概述(4)————HDFS权限
- Hadoop - HDFS概述
- C#、JAVA操作Hadoop(HDFS、Map/Reduce)真实过程概述。组件、源码下载。无法解决:Response status code does not indicate success: 500。