HDFS的文件操作流(1)——写操作(客户端概述)
2011-11-06 18:48
357 查看
大家可能对本地文件系统中的文件I/O流已经是非常的熟悉了,那么,像HDFS这种分布式的文件I/O流——基于网络I/O流的数据流,又是如何实现的呢?这就是本文的重点之一:HDFS的文件写入流。
熟悉HDFS的人可能知道,当我们调用DistributedFileSystem的create方法时,将会返回一个FSDataOutputStream对象,通过这个对象来对文件进行数据的写入。还是贴一张该对象的类图吧!
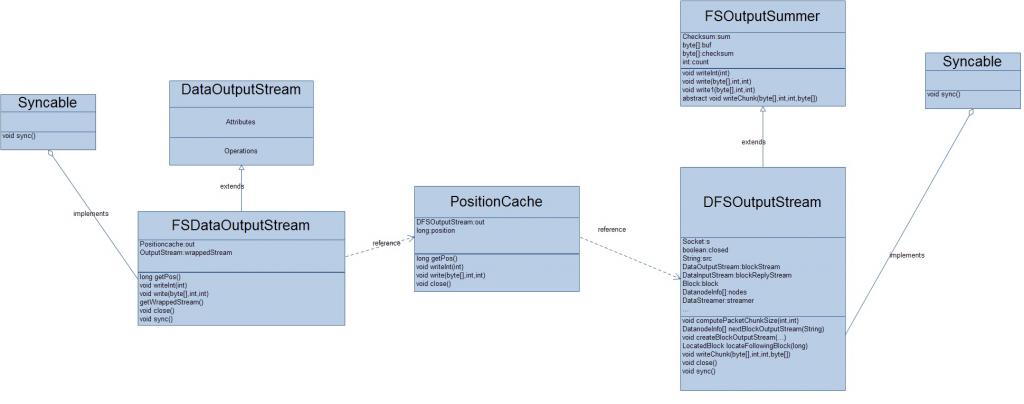
现在,我们以调用FSDataOutputStream的write(byte[],int,int)为例来看看HDFS是如何完成文件的数据写入操作的。先see一下这个过程的序列图:
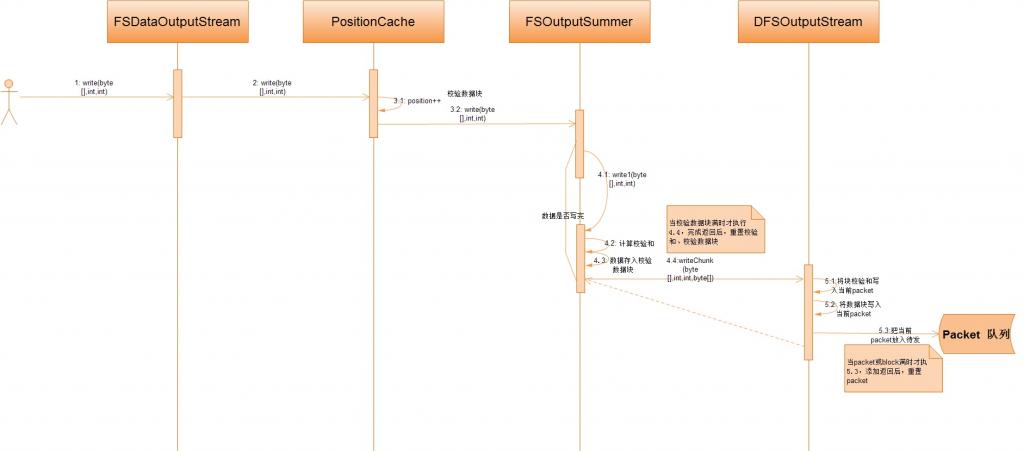
从上图中,我们可以很容易的看出,文件的写入操作,关键是是要看DFSOutputSream,所以,下面我将详细的讨论DFSOutputSream类。
当创建一个DFSOutputSream实例的时候,它会首先根据设置的一个packet的大小和一个校验块的大小来计算一个packet应该包含多少个校验块(数据块+加校验和)以及这个packet的实际大小。源代码如下:

其中,原始的packet的大小来自配置文件中参数dfs.write.packet.size的设置,校验数据块的大小来自配置文件中参数io.bytes.per.checksum的设置。然后调用ClientProtocol的create远程方法,最后启动线程DataStreamer。整个创建过程的源代码如下:

现在,一切问题就都纠结在DataStream到底是个啥东东,究竟干了些神马勾当才能和DataNode节点联系起来呢?
实际上,在DataStream中,它总是不停的从packet队列中取出待发送的packet给DataNode节点,当然在这个过程中,它要不断地向NameNode节点申请Blocks,即:当没有Block或申请的一个Block已满时,它会调用ClientProtocol的addBlock远程方法得到一个LocatedBlock,也就是要知道它应该要把这个Block的packet发送到那些DataNode节点上。当然,HDFS对于Block的副本copy采用的是流水线作业的方式:client把数据Block只传给一个DataNode,这个DataNode收到Block之后,传给下一个DataNode,依次类推,...,最后一个DataNode就不需要下传数据Block了。噢,当DataStream把一个Block的所有Packet传送完毕之后,必须要等待所有的Packet被ack之后才能重新申请新的Block来传送后面的packet。
熟悉HDFS的人可能知道,当我们调用DistributedFileSystem的create方法时,将会返回一个FSDataOutputStream对象,通过这个对象来对文件进行数据的写入。还是贴一张该对象的类图吧!
现在,我们以调用FSDataOutputStream的write(byte[],int,int)为例来看看HDFS是如何完成文件的数据写入操作的。先see一下这个过程的序列图:
从上图中,我们可以很容易的看出,文件的写入操作,关键是是要看DFSOutputSream,所以,下面我将详细的讨论DFSOutputSream类。
当创建一个DFSOutputSream实例的时候,它会首先根据设置的一个packet的大小和一个校验块的大小来计算一个packet应该包含多少个校验块(数据块+加校验和)以及这个packet的实际大小。源代码如下:
其中,原始的packet的大小来自配置文件中参数dfs.write.packet.size的设置,校验数据块的大小来自配置文件中参数io.bytes.per.checksum的设置。然后调用ClientProtocol的create远程方法,最后启动线程DataStreamer。整个创建过程的源代码如下:
现在,一切问题就都纠结在DataStream到底是个啥东东,究竟干了些神马勾当才能和DataNode节点联系起来呢?
实际上,在DataStream中,它总是不停的从packet队列中取出待发送的packet给DataNode节点,当然在这个过程中,它要不断地向NameNode节点申请Blocks,即:当没有Block或申请的一个Block已满时,它会调用ClientProtocol的addBlock远程方法得到一个LocatedBlock,也就是要知道它应该要把这个Block的packet发送到那些DataNode节点上。当然,HDFS对于Block的副本copy采用的是流水线作业的方式:client把数据Block只传给一个DataNode,这个DataNode收到Block之后,传给下一个DataNode,依次类推,...,最后一个DataNode就不需要下传数据Block了。噢,当DataStream把一个Block的所有Packet传送完毕之后,必须要等待所有的Packet被ack之后才能重新申请新的Block来传送后面的packet。

相关文章推荐
- hadoop源码 - HDFS的文件操作流 写操作(客户端)
- HDFS的文件操作流(4)——写操作(数据节点)
- HDFS的文件操作流(2)——读操作
- HDFS的文件操作流(3)——写操作(客户端)
- HDFS的API调用,创建Maven工程,创建一个非Maven工程,HDFS客户端操作数据代码示例,文件方式操作和流式操作
- HDFS的文件操作流(5)——写操作(NameNode节点)
- hadoop HDFS常用文件操作命令
- HDFS写操作的整体流程概述
- HDFS文件操作
- 操作hdfs里的文件
- 使用java api操作HDFS文件
- HDFS文件操作FileSystem使用API报错:copyToLocalFile NullPointerException
- java操作hdfs文件系统上的文件
- Hadoop之HDFS文件操作
- HDFS读写文件操作
- ios客户端学习-文档存储/路径处理/文件操作
- Hadoop之HDFS文件操作
- hadoop HDFS常用文件操作命令
- HDFS 常用文件操作命令
- B/s模式客户端无法操作EXCEL的文件解决