python3 [爬虫入门实战]爬虫之scrapy爬取中华人民共和国民政部
2017-08-04 22:20
603 查看
爬取缘由,主要是领导昨晚说要把整个网页上的数据都搞下来,我也没有去多想为什么,就尝试着把数据给爬下来了。昨天晚上回来没写多少, 跟今天早上写了写,也算熟悉了一下scrapy的post请求,跟fiddler的抓包过程吧。体验还是蛮好的。
1 先上一张要爬取的图片内容,虽然字段有点多: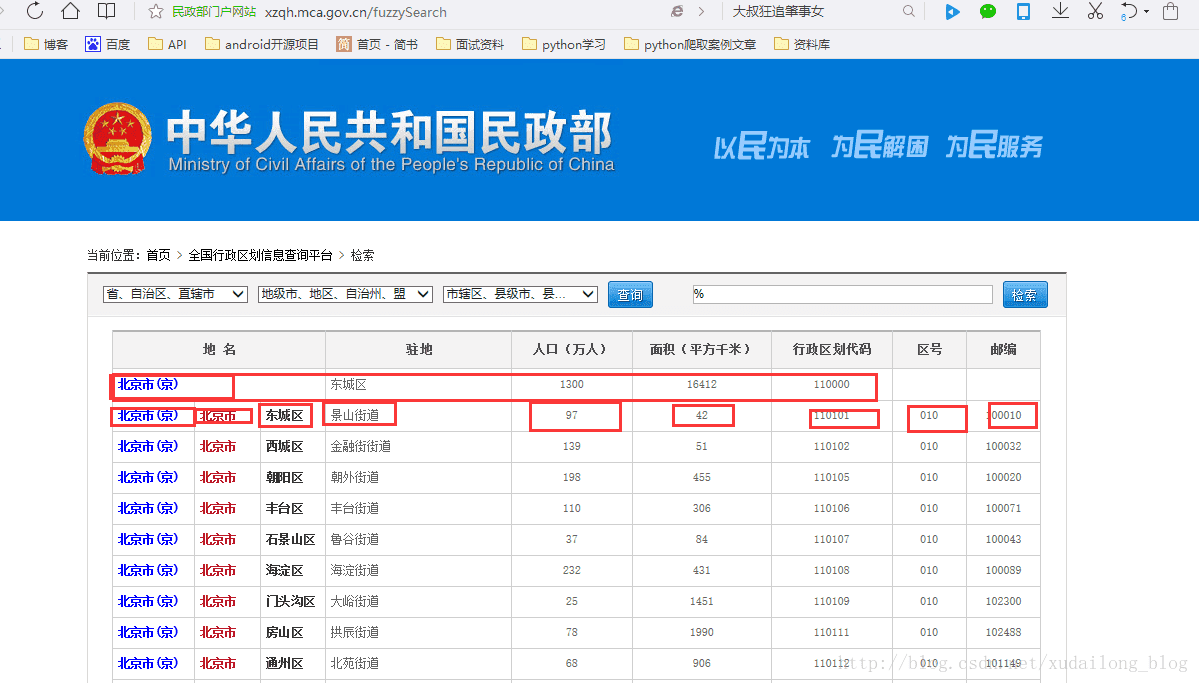
所要标出来的字段都是要进行爬取的。
scrapy的项目创建可以按照之前的文章进行创建。
这里用了fiddler进行抓包,因为单纯的请求是被拒绝访问的,大家可以试着一下进行访问。
http://xzqh.mca.gov.cn/fuzzySearch
这次的数据因为时间匆忙什么的,也没有及时进行数据的存储方式,只是单纯的打印在控制台上。

主要疑难点:
1 scrapy 进行post方面数据的请求, 2 首次使用fiddler抓包进行项目的实践 3 对于字段的爬取,主要是一边调试,一边进行跟进的,对table 这些标签把握度还不是很大。 4 未对数据进行合理的整理,清洗,数据的存储,突然发现,爬虫又快被我落下了,可伶的安卓。想着自己能什么时候能鼓起勇气去找一份属于自己的爬虫工作
最后再贴上源代码,虽然整理的不是很好,但是里面的注释还是很详细的,主要贴spider里面的代码,我有空学习上传代码到github吧,虽然还是在学习的过程中。
#encoding=utf8
import scrapy
from govinfos.items import GovinfosItem
class GovInfos(scrapy.Spider):
# 启动爬虫的名称
name = 'govinfo'
# 爬虫的范围
allowed_domains=['xzqh.mca.gov.cn']
# 爬虫的第一个url
# start_urls = ['http://xzqh.mca.gov.cn/fuzzySearch']
# 这里是用post请求数据的
def start_requests(self):
url = 'http://xzqh.mca.gov.cn/fuzzySearch'
# FormRequest 是Scrapy发送POST请求的方法
yield scrapy.FormRequest(
url = url,
formdata = {"fs" : "%"},
callback = self.parse
)
# 爬取结果分析
def parse(self, response):
print('%'*30)
# print(response.body)
node_list = response.xpath("//*[@class='info_table']/tr")
for node in node_list:
# 根据jiansuo_table 进行判断是否包含,若不包含,则为城市的第一个名称
# 第一个城市的第一个名称
td1 = node.xpath("./td[@class='name_left']/a/text()").extract()
shen_address = node.xpath("./td/table[@class='jiansuo_table']/tr[@class='name_left']/td/a[@class='sheng_td']/text()").extract()
shi_address = node.xpath("./td/table[@class='jiansuo_table']/tr[@class='name_left']/td/a[@class='shi_td']/text()").extract()
qu_address = node.xpath("./td/table[@class='jiansuo_table']/tr[@class='name_left']/td[3]/a/text()").extract()
print('%' * 30)
print(td1)
print(shen_address)
print(shi_address)
print(qu_address)
# 驻地
zhudi_address =node.xpath("./td[@class='name_left']/text()").extract()
print(zhudi_address)
# renkou
person = node.xpath("./td[3]/text()").extract()
print(person)
#面积
area = node.xpath("./td[4]/text()").extract()
print(area)
# 行政区划
xingzhen = node.xpath("./td[5]/text()").extract()
print(xingzhen)
# 区号
quhao = node.xpath("./td[6]/text()").extract()
print(quhao)
# 邮编
# print(node)
youbian = node.xpath("./td[7]/text()").extract()
print(youbian)完结,继续学习django的学习。

相关文章推荐
- python3 [爬虫入门实战]爬虫之scrapy爬取游天下南京短租房存mongodb
- python3 [爬虫入门实战]爬虫之scrapy爬取中国医学人才网
- Python3网络爬虫:Scrapy入门实战之爬取动态网页图片
- python3 [爬虫入门实战]爬虫之scrapy爬取传智播客讲师初体验
- python3 [爬虫入门实战]爬虫之scrapy爬取织梦者网站并存mongoDB
- python3 [爬虫入门实战]爬虫之scrapy爬取织梦者网站并存mongoDB
- python3 [爬虫入门实战]爬虫之scrapy安装与配置教程
- python3 [爬虫入门实战]scrapy爬取盘多多五百万数据并存mongoDB
- python3 [爬虫入门实战]scrapy爬取盘多多五百万数据并存mongoDB
- Python爬虫实战入门二:从一个简单的HTTP请求开始
- Python爬虫入门-利用scrapy爬取淘女郎照片
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
- Python爬虫实战入门五:获取JS动态内容—爬取今日头条
- Python爬虫框架Scrapy实战之批量抓取招聘信息
- Python爬虫框架Scrapy实战之批量抓取招聘信息
- python3 [入门基础实战] 爬虫入门之xpath的学习
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- python3 [入门基础实战] 爬虫入门之智联招聘的学习(一)
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解