python爬虫爬取豆瓣书籍信息并生成表格
2017-07-26 10:08
465 查看
学了没多长时间python就开始接触爬虫(被一名学长带进了爬虫的坑,感谢学长的指导),看了网上的一些视频,简单的了解了python的requsts库,bs4,就可以实现一个网页的最简单的爬虫(其实就是用几行代码把某个网页的html抓取下来,生肉(滑稽)),然后当然还需要对网页的元素进行处理,提取出有效的信息,所以,发现了bs4的强大,我个人到目前一直用的是select,还没使用find_all,将来还要学习,然后加上skimage可以爬到网页上的图片,最后加上pandas,就可以将爬取到的信息生成表格形式,还可以生成Excel文件,方便后期对数据进行处理。
这里发表我的第一个实战爬虫,爬取豆瓣网书籍目录信息,并将书籍信息存放到一个Excel文件中
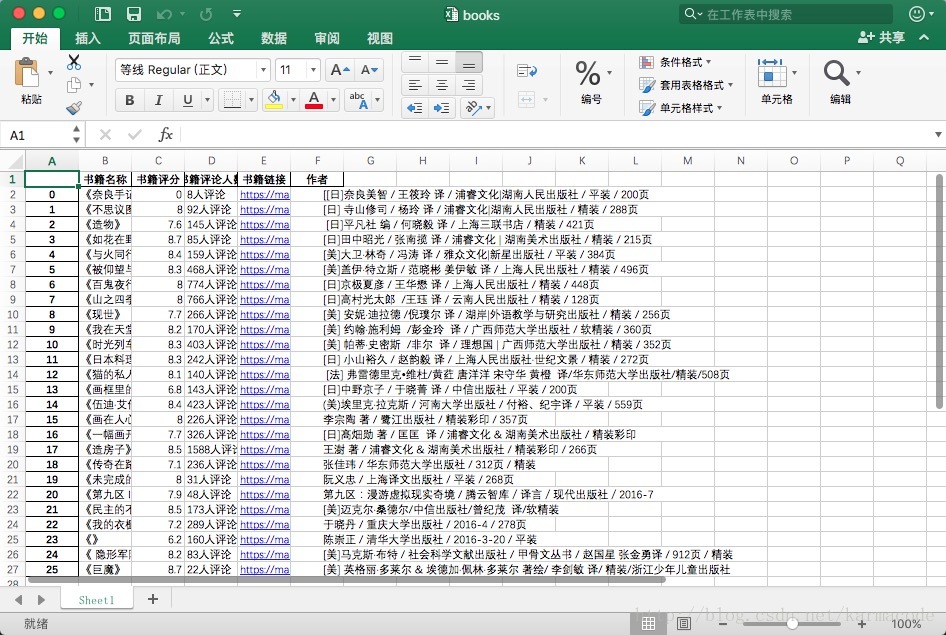
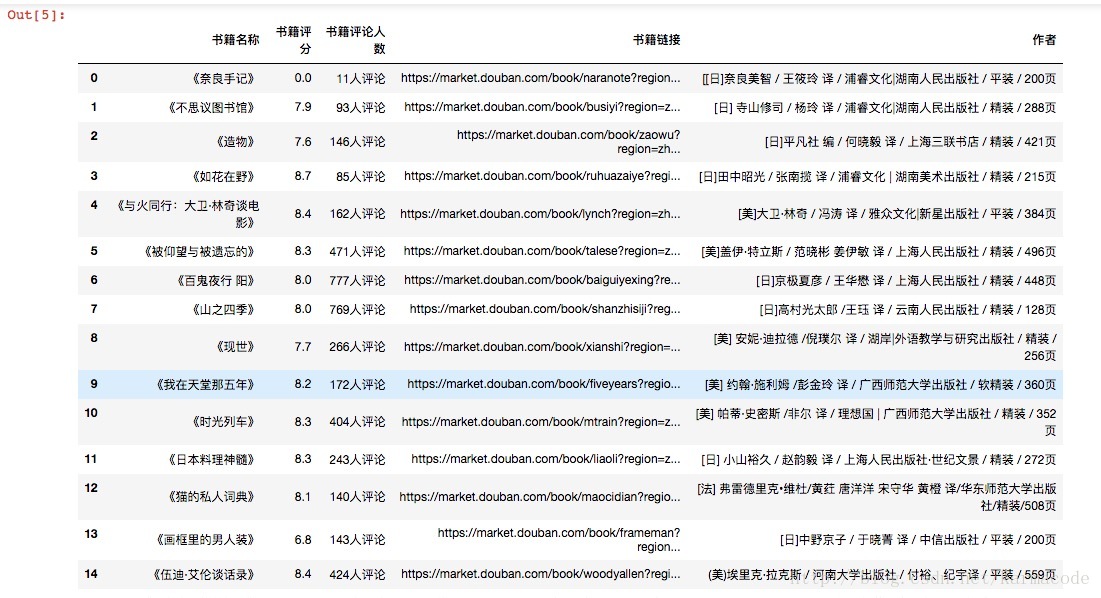
由于采用的是jupter notebook开发的,所以在pycharm上的输出格式可能有些许不同(其实现在对jupyter notebook还是不太熟悉,但是感觉很强大)
第一次发blog,有不足之处希望见谅,后续会继续更新
这里发表我的第一个实战爬虫,爬取豆瓣网书籍目录信息,并将书籍信息存放到一个Excel文件中
#爬虫爬取豆瓣书目录
import requests
from bs4 import BeautifulSoup
import json
import pandas #该库用于对爬取的信息进行表格性操作
from skimage import io#该库用于打印爬取到的照片
url = 'https://market.douban.com/book/?utm_campaign=book_nav_freyr&utm_source=douban&\
utm_medium=pc_web&page={}&page_num=20&'#该函数式用来返回一个列表存放含有书籍信息的字典
def bookList(url):
newurl = requests.get(url)
soup = BeautifulSoup(newurl.text,'html.parser')
result_total = []
for book in soup.select('.book-item'):
if len(book.select('.book-brief'))>0:
bookimag2 = io.imread(book.select('img')[1]['src'])#书的图片
io.imshow(bookimag2)
#io.show()#为了使爬取到的图片显示出来
bookurl = book.select('a')[0]['href']#抓取书的链接url
#print('链接: ',bookurl)
result_total.append(booktextscore(bookurl))#将所抓取书的信息字典添加到列表里面
bookimag1 = io.imread(book.select('img')[0]['src'])#背景图片
io.imshow(bookimag1)
#io.show()
return result_total#返回一个列#该函数式用来爬取书籍的名字,评分,评价人数以及书的简单介绍
def booktextscore(url):
booktexturl = requests.get(url)
soup = BeautifulSoup(booktexturl.text,'html.parser')
result = {}#创建一个字典将相关书籍信息存入到字典中
bookname = soup.select('.book-breintro h3')[0].text
bookname2 = '《' + bookname + '》'
print(bookname2)
result['书籍名称'] = bookname2
bookauthor = soup.select('.book-public')[0].text.lstrip('\n ').rstrip('\n ')
result['作者'] = bookauthor
print(bookauthor)
print(url)
result['书籍链接'] = url
score = soup.select('.total-score')[0].text#爬取该书评分,其中可能含有有些书籍由于评论人数不足导致没有评分,加一个判断默认该种情况成评分为0
if score == '评价人数不足':
score = 0
score = float(score)
result['书籍评分'] = float(score)#将评分强制转换成float类型的
print('评分:',score)
commentnum = soup.select('.comment-number')[0].text#爬取本书评论人数
print(commentnum)
print('该书简介:\n')
result['书籍评论人数'] = commentnum
article = []#添加一个列表
for ench in soup.select('.layout-content'):#爬取的是图书详情
for p in ench.select('.paragraph-content p')[:-1]:
article.append(p.text.strip())#将p标签中的文字添加到列表中
articlebook = '\n '.join(article)
#print(articlebook)
#result['书籍简介'] = articlebook
return resultbook_total = []
#由于书籍信息有两页,所以加一个循环将两页书籍信息都添加进列表中方便生成表格
for ench in range(1,3):
newurl = url.format(ench)#通过format将URL地址实现可变性,可以将两页书籍信息都打印出来
book_result = bookList(newurl)
book_total.extend(book_result)
print(book_total)
df = pandas.DataFrame(book_total)
print(df.head(26))
df.to_excel('books.xlsx')#将爬取后的书籍信息通过pandas转换成表格形式由于采用的是jupter notebook开发的,所以在pycharm上的输出格式可能有些许不同(其实现在对jupyter notebook还是不太熟悉,但是感觉很强大)
第一次发blog,有不足之处希望见谅,后续会继续更新

相关文章推荐
- 【Python爬虫第二弹】基于爬虫爬取豆瓣书籍的书籍信息查询
- Python 爬虫第三步 -- 多线程爬虫爬取当当网书籍信息
- python实现爬取豆瓣编程书籍的信息
- python爬虫实现获取豆瓣图书的top250的信息-beautifulsoup实现
- Java爬虫系列之一HttpClient【爬取京东Python书籍信息】
- Python爬虫入门2 | 爬取豆瓣电影信息
- [python]书籍信息爬虫示例
- python爬虫实战 | 爬取豆瓣TOP250排名信息
- [python爬虫] BeautifulSoup和Selenium对比爬取豆瓣Top250电影信息
- python爬虫抓取豆瓣所有恐怖片信息(利用多线程和构建免费ip代理池)
- Python3.6爬虫爬取豆瓣电影Top250信息
- 一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
- 爬虫入门:python+pycharm,豆瓣电影信息,短评,分页爬取,mysql数据库连接
- Python爬虫抓取豆瓣商业书籍,并保存为txt便于查阅
- python 爬虫学习三(Scrapy 实战,豆瓣爬取电影信息)
- Python爬虫学习---------根据分类爬取豆瓣电影的电影信息
- python书籍信息爬虫实例
- python爬虫之豆瓣图书信息几行字
- python爬虫,爬取豆瓣电影《芳华》电影短评,分词生成云图。
- 爬虫实战【11】Python获取豆瓣热门电影信息