用python 分析微信好友信息并生成词云
2017-07-25 17:49
639 查看
在知乎上偶然看到有人推荐itchart这个微信接口,抱着好奇的想法尝试了以下,果然非常好玩。
官方链接:http://itchat.readthedocs.io/zh/latest/#itchat
get_info.py这个类用来爬取好友信息并保存到指定文件
analyse.py这个类根据下载的好友数据分析好友信息
输出结果:
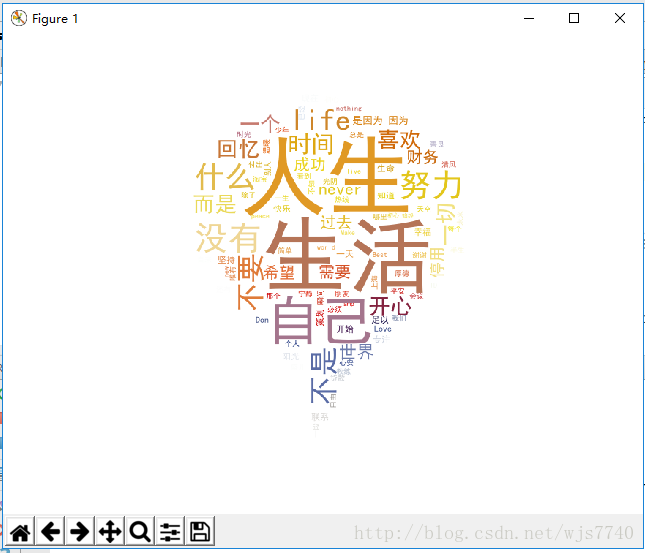
ciyun.py根据签名生成词云
效果:
官方链接:http://itchat.readthedocs.io/zh/latest/#itchat
目录结构
get_info.py这个类用来爬取好友信息并保存到指定文件
import itchat import os import time basepath = os.path.dirname(os.path.realpath(__file__)) download_path = basepath+'\downloads'+ '\\' # 调用itchat接口登录并拉取数据 itchat.login() friends = itchat.get_friends(update=True)[0:] fmt='%Y%m%d%H%M%S' #定义时间显示格式 Date=time.strftime(fmt,time.localtime(time.time())) download_file_name = 'friendslist_'+friends[0]['NickName']+ '_' + Date + '.txt' f = open(download_path+download_file_name,'wb') print(download_path+download_file_name) for i in friends[1:]: friend = (str(i) + "\n").encode(encoding='gb18030') # print(str(i)) f.write(friend) f.close()
analyse.py这个类根据下载的好友数据分析好友信息
# Author:Jason.wang
import re
import os
import time
base_pic = "C:/Users/Think/Pictures/Saved Pictures/beb28c538ac52a91.jpg"
source_file = "friendslist_雨佳Clara_20170724223344.txt"
source_file = "friendslist_say_20170724132202.txt"
basepath = os.path.dirname(os.path.realpath(__file__))
download_file = basepath+'\downloads\\'+ source_file
fs_str = ''
with open(download_file,'rb') as f:
fs_str = f.read().decode('gb18030')
friends = fs_str.split('\n')
# 初始化计数器
male = female = other = 0
# 所有省份
Provinces_list = []
#friends[0]是自己的信息,所以要从friends[1]开始
for i in friends:
if i.__len__()>0:
i = i.replace('<ContactList: [','"<ContactList: [')
i = i.replace(']>',']>"')
friend = eval(i)
# 统计性别
sex = friend["Sex"]
if sex == 1:
male += 1
exit
elif sex ==2:
female += 1
else:
other+=1
# 统计地区
Province = friend["Province"]
Provinces_list.append(Province)
#计算朋友总数
total = len(friends)
#打印出自己的好友性别比例
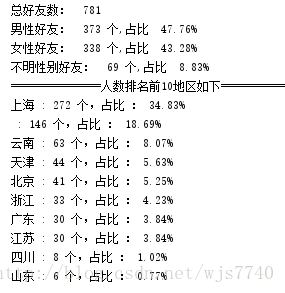
print("总好友数: %d" % total + "\n" +
"男性好友: %d 个,占比 %.2f%%" % (male,(float(male)/total*100)) + "\n" +
"女性好友: %d 个,占比 %.2f%%" % (female,(float(female) / total * 100)) + "\n" +
"不明性别好友: %d 个,占比 %.2f%%" % (other,(float(other) / total * 100)))
Provinces_set = set(Provinces_list)
Provinces_dict = {}
for i in Provinces_set:
Provinces_dict[i] = Provinces_list.count(i)
# 对省份字典按value排序
Provinces_dict = sorted(Provinces_dict.items(),key=lambda asd:asd[1],reverse=True)
print("===============人数排名前10地区如下==================")
top = 0
for k,v in Provinces_dict:
if top<10:
print("%s : %d 个,占比 : %.2f%%" % (k,v,float(v)/total*100))
top+=1输出结果:
ciyun.py根据签名生成词云
# -*- coding:UTF-8 -*-
# Author:Jason.wang
import re
import os
import time
base_pic = "C:/Users/Think/Pictures/Saved Pictures/beb28c538ac52a91.jpg"
source_file = "friendslist_雨佳Clara_20170724223344.txt"
# source_file = "friendslist_say_20170724132202.txt"
basepath = os.path.dirname(os.path.realpath(__file__))
download_file = basepath+'\downloads\\'+ source_file
fs_str = ''
with open(download_file,'rb') as f:
fs_str = f.read().decode('gb18030')
friends = fs_str.split('\n')
siglist = []
for i in friends:
if i.__len__()>0:
i = i.replace('<ContactList: [','"<ContactList: [')
i = i.replace(']>',']>"')
friend = eval(i)
# print(friend)
# print(friend["Signature"])
signature = friend["Signature"].strip().replace("span","").replace("class","").replace("emoji","")
rep = re.compile("1f\d+\w*|[<>/=]")
signature = rep.sub("",signature)
siglist.append(signature)
text = "".join(siglist)
import jieba
wordlist = jieba.cut(text,cut_all=True)
word_space_split = " ".join(wordlist).replace("\n","")
print(word_space_split)
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import numpy as np
import PIL.Image as Image
coloring = np.array(Image.open(base_pic))
my_wordcloud = WordCloud(background_color="white",max_words=2000,
mask=coloring,max_font_size=60,random_state=42,scale=2,
font_path="C:/windows/fonts/SimHei.ttf").generate(word_space_split)
image_colors = ImageColorGenerator(coloring)
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()效果:

相关文章推荐
- Python微信好友信息意义及取值分析(基于itchat)
- python数据分析(1)——获取微信好友的统计信息
- python数据分析(1)——获取微信好友的统计信息
- python项目:获取微信好友信息(一)抓取微信好友数据
- Python--分析微信好友是否被删除
- 利用python进行微信好友分析
- 用Python对微信好友进行分析
- 利用python深度分析微信朋友圈好友
- 基于Python实现的微信好友数据分析
- python项目:获取微信好友信息(二)csv数据读取与处理
- 用python玩微信(聊天机器人,好友信息统计)
- python实战===爬取所有微信好友的信息
- 基于Python实现的微信好友数据分析
- Python之获取微信好友信息
- Python对微信好友进行简单统计分析
- 微信是一个很神器的软件!用Python掌握好友的信息!勿用于非法!
- Python利用itchat对微信中好友数据实现简单分析的方法
- 使用Python对微信好友进行数据分析
- 利用python进行微信好友数据分析
- [python]如何生成微信中好友签名词云