微服务架构的两大解耦利器与最佳实践 推荐
2017-07-17 11:34
561 查看
这几年,微服务架构这个术语渐成热门词汇,但它不是一个全新架构,更不是一个包治百病的架构。那么,微服务架构究竟能够解决什么问题,又带来哪些痛点?
本文将与大家谈谈这个问题,以及微服务架构的两大解耦利器配置中心和消息总线的最佳实践。微服务架构解决的问题与带来的痛点
一互联网高可用架构为什么要服务化?
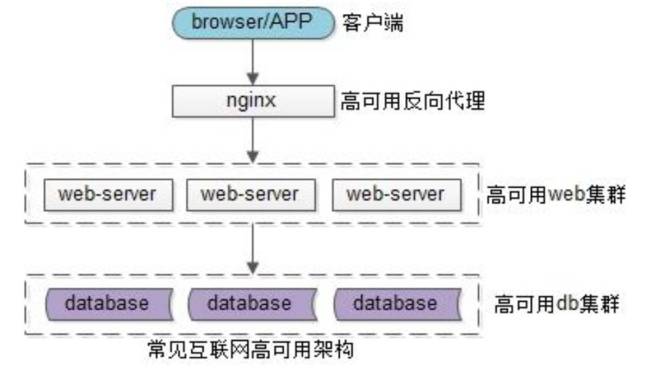
上图是互联网典型的高可用架构,大部分公司如果没有使用微服务,正在使用这样的架构:用户端是浏览器 browser,APP 客户端
后端入口是高可用的 nginx 集群,用于做反向代理
中间核心是高可用的 web-server 集群,研发工程师主要在这一层进行编码工作
后端存储是高可用的 db 集群,数据存储在这一层。更典型的公司,web-server 层是通过 DAO/ORM 等技术来访问数据库。
最初的架构都没有服务层,这样的架构会遇到怎样的痛点?对于没有使用微服务架构的公司来说,要不要升级到微服务架构呢?
58 同城和 58 到家的架构痛点
回答这个问题之前,先来看看您是否遇到和 58 同城及 58 到家类似的架构痛点:
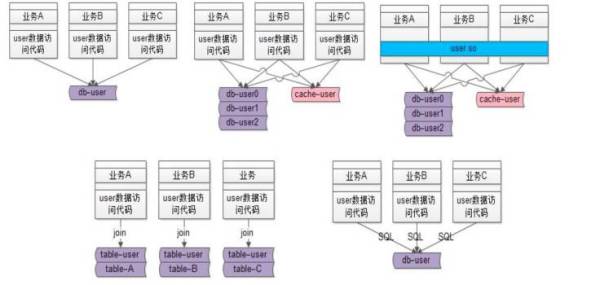
图一,代码拷贝。A、B、C
业务线,如果没有微服务架构,可能要直接访问数据库里的数据来实现自己的业务需求。拿访问用户数据举例,用户中心包括所有公司必备的业务,比如登陆、注册、查找用户信息等。如某业务线需要访问用户信息,需要通过封装用户访问代码模块实现。如业务繁多,每个业务线都需要访问用户信息,潜在的会存在代码拷贝问题。
图二,底层复杂性扩散。随着流量的增长,需要加入缓存,对数据的访问模式和流程都会带来影响。从直接访问数据库,变到先访问缓存再访问数据库。这样的复杂性,所有的业务都需关注,代码都要重新做一遍。包括数据量增大后,要进行的水平线切分、分库、分表,存储引擎的变化等复杂性,要扩展到业务线。
图三,代码库耦合。58 同城遇到图一和图二问题,最初想到的方案并不是微服务,而是将相互拷贝的复杂性代码封装到一个代码库(DLL 或 jar 包),实现统一的相关功能,屏蔽复杂性。
拷贝代码的好处是代码独立演化,做改动互不影响。弊端是一旦用上库,业务就会耦合在一起,因共用jar包,一旦其中某个业务升级,其他的业务就可能受影响。
图四,数据库耦合。业务线不只访问 user 数据,还会结合自己的业务访问自己的数据:典型的情况是通过 join 数据表来实现各自业务线的一些业务逻辑。这样的话:业务线 A 的 table-user 与 table-A 耦合在了一起;
业务线 B 的 table-user 与 table-B 耦合在了一起;
业务线 C 的 table-user 与 table-C 耦合在了一起;
结果就是:table-user,table-A,table-B,table-C都耦合在了一起。随着数据量的越来越大,业务线 ABC 数据库无法进行垂直拆分,必须使用一个大库(疯了,一个大库 300 多个业务表 =_=)。
图五,SQL 质量得不到保证,业务之间互相影响。由业务方拼装的 SQL 语句调用方式,通过 ORM(对象关系映射)的方法生成 SQL 语句数据库,这个库是共用的,会影响所有的业务线。一旦某业务有慢 SQL 出现,其他业务就会受影响。
回到要不要做微服务升级的问题,如果大家所负责的系统、模块或公司也存在以上的这些问题,建议考虑做服务化,在中间加一个服务层,所有调用不允许直接连接底层库。服务化还有一个很重要的特点就是数据库私有化,任何人不能跨越服务程序,干预数据库。想调用要通过接口来实现,当数据库性能变差,直接加一台机器,把数据库迁移,对调用方不会产生影响。
二服务化解决了哪些问题
在 58 同城,用户中心由专门的部门负责,是全公司、全业务依赖比较重的服务,它对代码要求和稳定性要求比较高。整个 SQL 语句是服务层控制,向上提供有限的服务接口和无限的性能。
工程师要保障虽然提供用户基础数据的接口数是有限的,但调用方不需要关心底层细节,可以认为性能是无限的。至于如何扩容,就是服务层的事情了。下图是互联网典型的服务化架构。以用户中心为例,用户中心服务向上屏蔽底层技术的复杂性,上层通过 RPC 接口来调用服务,如同调用本地函数一样,不需要关注分库、分表、缓存。
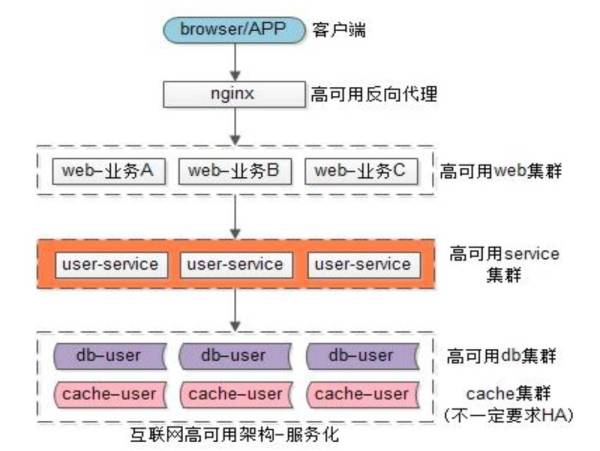
业务方需要数据,把数据拼装出来返回 APP/PC 端即可,可以不关心数据存在哪里,底层的复杂性也由用户层来承担。这样一来,用户库只有用户服务依赖,任何人不得跨越用户服务来直接调用数据库,就不会存在代码拷贝、代码库、数据库耦合的情况。微服务架构的两大解耦利器微服务虽然看上去很好,但也给系统带来很多问题,如部署方面,越来越复杂,分层越来越多,处理时间也随之增加。如网络交互方面,运维负载性、追查问题等等。那么:面对架构的耦合及复杂性如何来优化
结构如何配置
接下来,我们介绍配置中心最佳实践与消息总线最佳实践这两大解耦利器。
一微服务架构解耦利器-配置中心最佳实践
放弃 IP 连接服务,选择内网域名。58
到家是创业公司,痛点和很多公司都很相似。其中一个场景是 IP 的变化。最初,IP 写在配置文件中,通过某个 IP
或端口访问数据与服务。当某台机器出现问题,DB 同事会在新机器做部署,更换 IP。当某个服务或 IP 发生变化,就在配置文件中修改,重启。
这里的经验分享是千万不要用 IP 连接服务或数据库,要选择内网域名。这两者的区别在于:使用 IP 连接服务或数据库的方式,所有的库都和一个表有关联,一旦机器挂掉或升高配,几乎所有的业务都需要修改 IP。即便只是升级一个业务,都会严重影响其他业务。
选择内网域名的方式后,如果换 IP,在运维层面可以进行统一切断,自动向上链接,上游的业务就不用动,也不受下层变动的影响。
配置私藏。如下图是 58 到家早期改成内网域名之后的配置文件。底层用户服务或数据库,是个高可用集群,从 IP1 到 IP3。上游有三个依赖,两个服务器,一个 Web 调用这个高可用集群。Web 包含 WBE2.conf,调用 IP1,IP2,IP3。
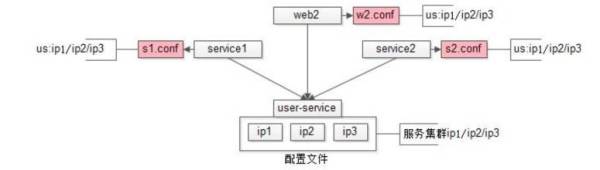
在实践过程中,这种配置私藏的方式遇到两个痛点:
升级时不知道被那个服务调用。当遇到流量越来越大,需要添加服务器时,如上图,把
IP1 去掉,增加 IP4 和 IP5
的时候,需要通知上游。但问题在于流量不大时,因为对业务非常熟悉,工程师能够准确的找到服务器对应的负责人。随着业务越来越复杂,工程师遇到出现了问题,不知道模块被谁依赖的情况。
升级时需要上游配合重启。当增加 IP 时,需要找到对应的上游服务器负责人,通知他进行服务器重启。公司成百上千的服务每天都有人在升级,当时的做法是采用建群,随时做通知,但这样很影响研发同事写代码的效率。
全局配置。最开始底层的通用基础服务,配置是写在每个站点;而且每个应用私藏在配置文件里,在升级过程中,不知道谁私藏了这个配置。面对这两个痛点,58到家采用了下图的解决方案:全局配置
全局配置也就是升级,只需要做流程与规范上的优化,对原有系统架构不产生任何影响,成本低且可平滑的慢慢迁移。下图的实现原理是把最初放在每个服务器中的配置文件,抽取一个全局配置文件,做好目录结构
global.conf。所有基础服务配置如果由多个 global.conf 上游来读取,必须通过 global.conf
来读取。这样所有的业务都在 global.conf,就可以保障下一次升级可连接到最新。
那么,在做扩容的时候,能不能实现调用方不需要升级呢?当然可以,两个小组件就可以实现:监控全局文件的变化情况,发生变化就进行回调,这样用户中心要配置修改的是全局配置。
动态链接池组件。这是一个自身及调整流程成本都很低的组件,负载均衡也会在其中实现。
配置中心。全局配置对于服务提供方而言,问题依然没有全部解决,扩容不需要重启,却仍不知道被谁依赖,不知道被谁访问,就没办法做服务治理、限流等操作。这时,工程师就要引入配置中心,来解决这个问题。
配置中心思路是部署用户中心承载所有配置,取代所有全局配置文件。这样一来,所有都依赖配置中心上游,服务1,服务2,服务3,都不再访问global.conf,而是通过配置中心来拉取相关配置,配置变更,配置中心反向回调,调用方也不要重启。
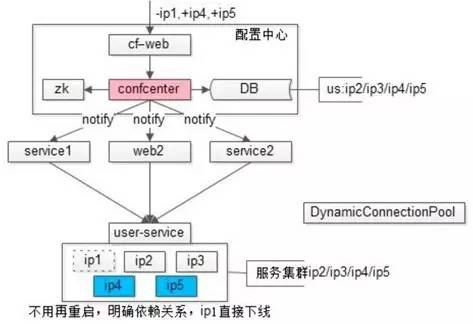
配置中心最佳实践总结。配置中心是微服务架构中一个逻辑解耦但物理不解耦的利器。它原来在逻辑上依赖于自己的配置文件,依赖于下游,现在不再向配置文件索要配置,而是所有调用方逻辑上只依赖于配置中心。物理上不解耦,是从配置文件拿到配置以后该连谁还是连谁。
二微服务架构解耦利器-消息总线最佳实践
消息总线(Message Queue),后文称 MQ,是一种跨进程的通信机制,用于上下游传递消息。它也是微服务架构中很常见的解耦利器之一,在数据驱动的任务依赖、调用方不关注处理结果、关注结果的长时间调回等场景下使用。
数据驱动的任务依赖。大部分公司都有 BI、数据部门,每天都会跑一些日志、数据库,多个任务之间往往存在依赖关系,任务1先执行,依次是任务 2、任务 3 输入,最终得到结果。在没有消息总线之前,大多公司和58到家的做法雷同,就是人工排班表。
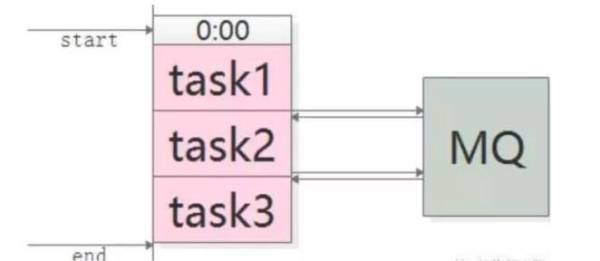
人工排班表的弊端如下:原本执行时间是40分钟,但为保险,每个人都会多加时间,导致任务总执行时间延长。
万一某一任务的执行时间超过预留时间,接下来的任务不知情,会导致整个业务失败。
多个业务之间可能有多重依赖,特别是在数据统计、数据分析过程中,一些核心脚本执行完,后面一系列脚本才能执行。
如下图,这种数据驱动的任务依赖非常适合使用MQ解耦。
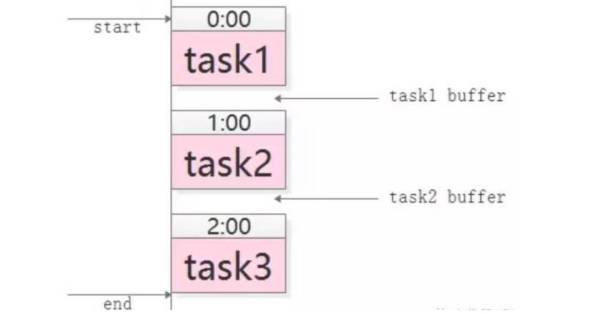
task1准时开始,结束后发一个“task1 done”的消息
task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息
task3同理
采用 MQ 的优点是:不需要预留 buffer,上游任务执行完,下游任务总会在第一时间被执行
依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可
有任务执行时间变化,下游任务都不需要调整执行时间
需要特别说明的是,MQ 只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。调用方不关注处理结果,这样的情况也适合消息总线来做解耦。举例,58
同城的很多下游需要关注“用户发布帖子”这个事件,比如招聘用户发布帖子后,招聘业务要奖励 58 豆;房产用户发布帖子后,房产业务要送 2
个置顶;二手用户发布帖子后,二手业务要修改用户统计数据。
对于这类需求,常见的实现方式是使用调用关系:帖子发布服务执行完成之后,调用下游招聘业务、房产业务、二手业务,来完成消息的通知,但事实上,这个通知是否正常、正确的执行,帖子发布服务根本不关注。这种方法的痛点是:帖子发布流程的执行时间增加了
下游服务宕机,可能导致帖子发布服务受影响,上下游逻辑+物理依赖严重
每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务,这一点是最恶心的,属于架构设计中典型的依赖倒转,谁用过谁痛谁知道(采用此法的请评论留言)
采用下图的优化方案:MQ解耦帖子发布成功后,向MQ发一个消息
哪个下游关注“帖子发布成功”的消息,主动去MQ订阅
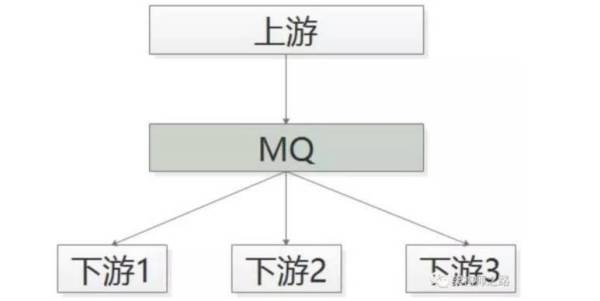
采用 MQ 的优点是:上游执行时间短
上下游逻辑+物理解耦,除了与 MQ 有物理连接,模块之间都不相互依赖
新增一个下游消息关注方,上游不需要修改任何代码
上游关注执行结果,但执行时间很长。有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用回调网关+MQ来解耦。举例:微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?
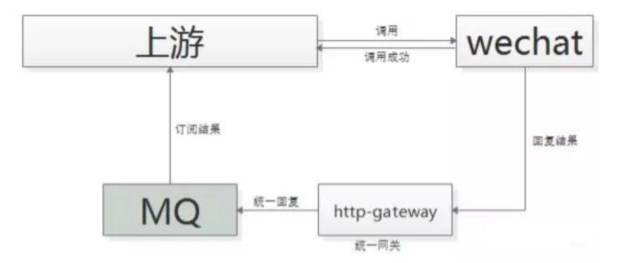
一般采用“回调网关+MQ”方案来解耦,新增任何对微信支付的调用,都不需要修改代码。调用方直接跨公网调用微信接口
微信返回调用成功,此时并不代表返回成功
微信执行完成后,回调统一网关
网关将返回结果通知 MQ
请求方收到结果通知
这里需要注意的是,不应该由回调网关来调用上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+ MQ 的方案。
综上所述,两个解耦利器的最佳实践场景如下:
配置中心是逻辑解耦,物理不解耦的微服务的利器。它可以解决配置导致的系统耦合,架构反向依赖的问题,配置中心的演进过程,配置私藏到全局配置文件,到配置中心。
消息总线是逻辑上解耦,物理上也解耦的微服务架构利器。它非常适合数据驱动的任务依赖,调用方不关注处理结果,或者调用方关注处理结果,但是回调的时间很长的场景。不适合调用方强烈关注执行结果的场景。
以上内容根据沈剑老师在 WOTA2017 “微服务架构实践”专场的演讲内容整理。

沈剑,现任58到家技术委员会主席,高级技术总监,负责企业、支付、营销和客户关系等多个后端业务部门。本质,技术人一枚。互联网架构技术专家,“架构师之路”公众号作者。曾任百度高级工程师,58同城高级架构师,58同城技术委员会主席,58同城C2C技术部负责人。

本文将与大家谈谈这个问题,以及微服务架构的两大解耦利器配置中心和消息总线的最佳实践。微服务架构解决的问题与带来的痛点
一互联网高可用架构为什么要服务化?
上图是互联网典型的高可用架构,大部分公司如果没有使用微服务,正在使用这样的架构:用户端是浏览器 browser,APP 客户端
后端入口是高可用的 nginx 集群,用于做反向代理
中间核心是高可用的 web-server 集群,研发工程师主要在这一层进行编码工作
后端存储是高可用的 db 集群,数据存储在这一层。更典型的公司,web-server 层是通过 DAO/ORM 等技术来访问数据库。
最初的架构都没有服务层,这样的架构会遇到怎样的痛点?对于没有使用微服务架构的公司来说,要不要升级到微服务架构呢?
58 同城和 58 到家的架构痛点
回答这个问题之前,先来看看您是否遇到和 58 同城及 58 到家类似的架构痛点:
图一,代码拷贝。A、B、C
业务线,如果没有微服务架构,可能要直接访问数据库里的数据来实现自己的业务需求。拿访问用户数据举例,用户中心包括所有公司必备的业务,比如登陆、注册、查找用户信息等。如某业务线需要访问用户信息,需要通过封装用户访问代码模块实现。如业务繁多,每个业务线都需要访问用户信息,潜在的会存在代码拷贝问题。
图二,底层复杂性扩散。随着流量的增长,需要加入缓存,对数据的访问模式和流程都会带来影响。从直接访问数据库,变到先访问缓存再访问数据库。这样的复杂性,所有的业务都需关注,代码都要重新做一遍。包括数据量增大后,要进行的水平线切分、分库、分表,存储引擎的变化等复杂性,要扩展到业务线。
图三,代码库耦合。58 同城遇到图一和图二问题,最初想到的方案并不是微服务,而是将相互拷贝的复杂性代码封装到一个代码库(DLL 或 jar 包),实现统一的相关功能,屏蔽复杂性。
拷贝代码的好处是代码独立演化,做改动互不影响。弊端是一旦用上库,业务就会耦合在一起,因共用jar包,一旦其中某个业务升级,其他的业务就可能受影响。
图四,数据库耦合。业务线不只访问 user 数据,还会结合自己的业务访问自己的数据:典型的情况是通过 join 数据表来实现各自业务线的一些业务逻辑。这样的话:业务线 A 的 table-user 与 table-A 耦合在了一起;
业务线 B 的 table-user 与 table-B 耦合在了一起;
业务线 C 的 table-user 与 table-C 耦合在了一起;
结果就是:table-user,table-A,table-B,table-C都耦合在了一起。随着数据量的越来越大,业务线 ABC 数据库无法进行垂直拆分,必须使用一个大库(疯了,一个大库 300 多个业务表 =_=)。
图五,SQL 质量得不到保证,业务之间互相影响。由业务方拼装的 SQL 语句调用方式,通过 ORM(对象关系映射)的方法生成 SQL 语句数据库,这个库是共用的,会影响所有的业务线。一旦某业务有慢 SQL 出现,其他业务就会受影响。
回到要不要做微服务升级的问题,如果大家所负责的系统、模块或公司也存在以上的这些问题,建议考虑做服务化,在中间加一个服务层,所有调用不允许直接连接底层库。服务化还有一个很重要的特点就是数据库私有化,任何人不能跨越服务程序,干预数据库。想调用要通过接口来实现,当数据库性能变差,直接加一台机器,把数据库迁移,对调用方不会产生影响。
二服务化解决了哪些问题
在 58 同城,用户中心由专门的部门负责,是全公司、全业务依赖比较重的服务,它对代码要求和稳定性要求比较高。整个 SQL 语句是服务层控制,向上提供有限的服务接口和无限的性能。
工程师要保障虽然提供用户基础数据的接口数是有限的,但调用方不需要关心底层细节,可以认为性能是无限的。至于如何扩容,就是服务层的事情了。下图是互联网典型的服务化架构。以用户中心为例,用户中心服务向上屏蔽底层技术的复杂性,上层通过 RPC 接口来调用服务,如同调用本地函数一样,不需要关注分库、分表、缓存。
业务方需要数据,把数据拼装出来返回 APP/PC 端即可,可以不关心数据存在哪里,底层的复杂性也由用户层来承担。这样一来,用户库只有用户服务依赖,任何人不得跨越用户服务来直接调用数据库,就不会存在代码拷贝、代码库、数据库耦合的情况。微服务架构的两大解耦利器微服务虽然看上去很好,但也给系统带来很多问题,如部署方面,越来越复杂,分层越来越多,处理时间也随之增加。如网络交互方面,运维负载性、追查问题等等。那么:面对架构的耦合及复杂性如何来优化
结构如何配置
接下来,我们介绍配置中心最佳实践与消息总线最佳实践这两大解耦利器。
一微服务架构解耦利器-配置中心最佳实践
放弃 IP 连接服务,选择内网域名。58
到家是创业公司,痛点和很多公司都很相似。其中一个场景是 IP 的变化。最初,IP 写在配置文件中,通过某个 IP
或端口访问数据与服务。当某台机器出现问题,DB 同事会在新机器做部署,更换 IP。当某个服务或 IP 发生变化,就在配置文件中修改,重启。
这里的经验分享是千万不要用 IP 连接服务或数据库,要选择内网域名。这两者的区别在于:使用 IP 连接服务或数据库的方式,所有的库都和一个表有关联,一旦机器挂掉或升高配,几乎所有的业务都需要修改 IP。即便只是升级一个业务,都会严重影响其他业务。
选择内网域名的方式后,如果换 IP,在运维层面可以进行统一切断,自动向上链接,上游的业务就不用动,也不受下层变动的影响。
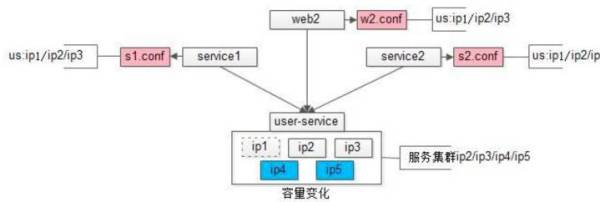
配置私藏。如下图是 58 到家早期改成内网域名之后的配置文件。底层用户服务或数据库,是个高可用集群,从 IP1 到 IP3。上游有三个依赖,两个服务器,一个 Web 调用这个高可用集群。Web 包含 WBE2.conf,调用 IP1,IP2,IP3。
在实践过程中,这种配置私藏的方式遇到两个痛点:
升级时不知道被那个服务调用。当遇到流量越来越大,需要添加服务器时,如上图,把
IP1 去掉,增加 IP4 和 IP5
的时候,需要通知上游。但问题在于流量不大时,因为对业务非常熟悉,工程师能够准确的找到服务器对应的负责人。随着业务越来越复杂,工程师遇到出现了问题,不知道模块被谁依赖的情况。
升级时需要上游配合重启。当增加 IP 时,需要找到对应的上游服务器负责人,通知他进行服务器重启。公司成百上千的服务每天都有人在升级,当时的做法是采用建群,随时做通知,但这样很影响研发同事写代码的效率。
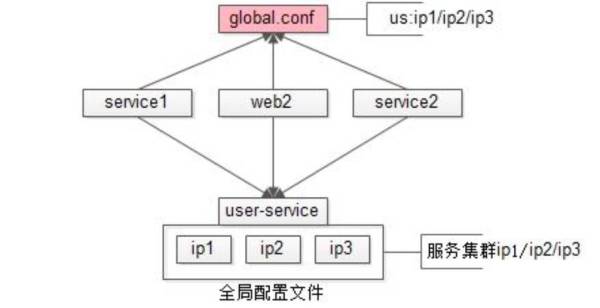
全局配置。最开始底层的通用基础服务,配置是写在每个站点;而且每个应用私藏在配置文件里,在升级过程中,不知道谁私藏了这个配置。面对这两个痛点,58到家采用了下图的解决方案:全局配置
全局配置也就是升级,只需要做流程与规范上的优化,对原有系统架构不产生任何影响,成本低且可平滑的慢慢迁移。下图的实现原理是把最初放在每个服务器中的配置文件,抽取一个全局配置文件,做好目录结构
global.conf。所有基础服务配置如果由多个 global.conf 上游来读取,必须通过 global.conf
来读取。这样所有的业务都在 global.conf,就可以保障下一次升级可连接到最新。
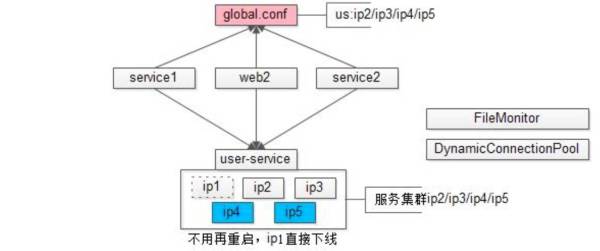
那么,在做扩容的时候,能不能实现调用方不需要升级呢?当然可以,两个小组件就可以实现:监控全局文件的变化情况,发生变化就进行回调,这样用户中心要配置修改的是全局配置。
动态链接池组件。这是一个自身及调整流程成本都很低的组件,负载均衡也会在其中实现。
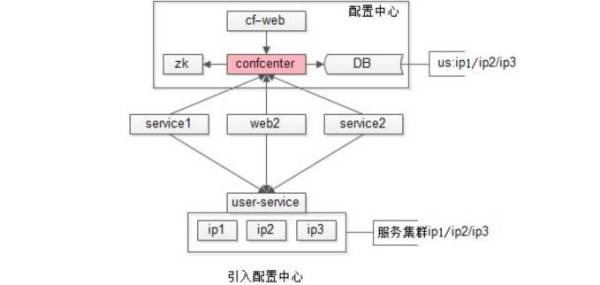
配置中心。全局配置对于服务提供方而言,问题依然没有全部解决,扩容不需要重启,却仍不知道被谁依赖,不知道被谁访问,就没办法做服务治理、限流等操作。这时,工程师就要引入配置中心,来解决这个问题。
配置中心思路是部署用户中心承载所有配置,取代所有全局配置文件。这样一来,所有都依赖配置中心上游,服务1,服务2,服务3,都不再访问global.conf,而是通过配置中心来拉取相关配置,配置变更,配置中心反向回调,调用方也不要重启。
配置中心最佳实践总结。配置中心是微服务架构中一个逻辑解耦但物理不解耦的利器。它原来在逻辑上依赖于自己的配置文件,依赖于下游,现在不再向配置文件索要配置,而是所有调用方逻辑上只依赖于配置中心。物理上不解耦,是从配置文件拿到配置以后该连谁还是连谁。
二微服务架构解耦利器-消息总线最佳实践
消息总线(Message Queue),后文称 MQ,是一种跨进程的通信机制,用于上下游传递消息。它也是微服务架构中很常见的解耦利器之一,在数据驱动的任务依赖、调用方不关注处理结果、关注结果的长时间调回等场景下使用。
数据驱动的任务依赖。大部分公司都有 BI、数据部门,每天都会跑一些日志、数据库,多个任务之间往往存在依赖关系,任务1先执行,依次是任务 2、任务 3 输入,最终得到结果。在没有消息总线之前,大多公司和58到家的做法雷同,就是人工排班表。
人工排班表的弊端如下:原本执行时间是40分钟,但为保险,每个人都会多加时间,导致任务总执行时间延长。
万一某一任务的执行时间超过预留时间,接下来的任务不知情,会导致整个业务失败。
多个业务之间可能有多重依赖,特别是在数据统计、数据分析过程中,一些核心脚本执行完,后面一系列脚本才能执行。
如下图,这种数据驱动的任务依赖非常适合使用MQ解耦。
task1准时开始,结束后发一个“task1 done”的消息
task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息
task3同理
采用 MQ 的优点是:不需要预留 buffer,上游任务执行完,下游任务总会在第一时间被执行
依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可
有任务执行时间变化,下游任务都不需要调整执行时间
需要特别说明的是,MQ 只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。调用方不关注处理结果,这样的情况也适合消息总线来做解耦。举例,58
同城的很多下游需要关注“用户发布帖子”这个事件,比如招聘用户发布帖子后,招聘业务要奖励 58 豆;房产用户发布帖子后,房产业务要送 2
个置顶;二手用户发布帖子后,二手业务要修改用户统计数据。
对于这类需求,常见的实现方式是使用调用关系:帖子发布服务执行完成之后,调用下游招聘业务、房产业务、二手业务,来完成消息的通知,但事实上,这个通知是否正常、正确的执行,帖子发布服务根本不关注。这种方法的痛点是:帖子发布流程的执行时间增加了
下游服务宕机,可能导致帖子发布服务受影响,上下游逻辑+物理依赖严重
每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务,这一点是最恶心的,属于架构设计中典型的依赖倒转,谁用过谁痛谁知道(采用此法的请评论留言)
采用下图的优化方案:MQ解耦帖子发布成功后,向MQ发一个消息
哪个下游关注“帖子发布成功”的消息,主动去MQ订阅
采用 MQ 的优点是:上游执行时间短
上下游逻辑+物理解耦,除了与 MQ 有物理连接,模块之间都不相互依赖
新增一个下游消息关注方,上游不需要修改任何代码
上游关注执行结果,但执行时间很长。有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用回调网关+MQ来解耦。举例:微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?
一般采用“回调网关+MQ”方案来解耦,新增任何对微信支付的调用,都不需要修改代码。调用方直接跨公网调用微信接口
微信返回调用成功,此时并不代表返回成功
微信执行完成后,回调统一网关
网关将返回结果通知 MQ
请求方收到结果通知
这里需要注意的是,不应该由回调网关来调用上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+ MQ 的方案。
综上所述,两个解耦利器的最佳实践场景如下:
配置中心是逻辑解耦,物理不解耦的微服务的利器。它可以解决配置导致的系统耦合,架构反向依赖的问题,配置中心的演进过程,配置私藏到全局配置文件,到配置中心。
消息总线是逻辑上解耦,物理上也解耦的微服务架构利器。它非常适合数据驱动的任务依赖,调用方不关注处理结果,或者调用方关注处理结果,但是回调的时间很长的场景。不适合调用方强烈关注执行结果的场景。
以上内容根据沈剑老师在 WOTA2017 “微服务架构实践”专场的演讲内容整理。
沈剑,现任58到家技术委员会主席,高级技术总监,负责企业、支付、营销和客户关系等多个后端业务部门。本质,技术人一枚。互联网架构技术专家,“架构师之路”公众号作者。曾任百度高级工程师,58同城高级架构师,58同城技术委员会主席,58同城C2C技术部负责人。

相关文章推荐
- 微服务架构的两大解耦利器与最佳实践
- 微服务架构的两大解耦利器与最佳实践
- 微服务架构的两大解耦利器与最佳实践
- 面向服务体系架构的业务规划和建模方法系列之四--实践案例介绍“汽车贷款 推荐
- 有容云:微服务架构最佳实践课堂PPT- 微服务容器化的挑战和解决之道
- 轻量级微服务架构及最佳实践
- Netflix的设计微服务体系架构的最佳实践
- python自动化测试开发利器ulipad最佳实践(可写python测试代码也可编写selenium、Appium等) 推荐
- 轻量级微服务架构及最佳实践
- APP后台开发运维与架构实践 5 : Nginx --- App后台HTTP服务的利器
- 微服务架构上云最佳实践
- 轻量级微服务架构及最佳实践
- JBoss 7/WildFly 配置管理,开发示例,架构分析,最佳实践
- 高性能网关设备及服务实践(dpdk)--服务器架构研究
- 【RESTful】Yii2实现RESTful架构配置最佳实践
- 本周ASP.NET英文技术文章推荐[02/17 - 02/23]:AJAX、History、jQuery、最佳实践、LINQ、Visual Studio、JavaScript、IIS
- Windows Azure 安全最佳实践 - 第 6 部分:Azure 服务如何扩展应用程序安全性
- 敏捷开发方法Scrum最佳实践 推荐