使用Scrapy爬取顶点小说整个网站的小说,入库Mysql!
2017-07-09 20:55
495 查看
代码整体思路
找到分类的链接
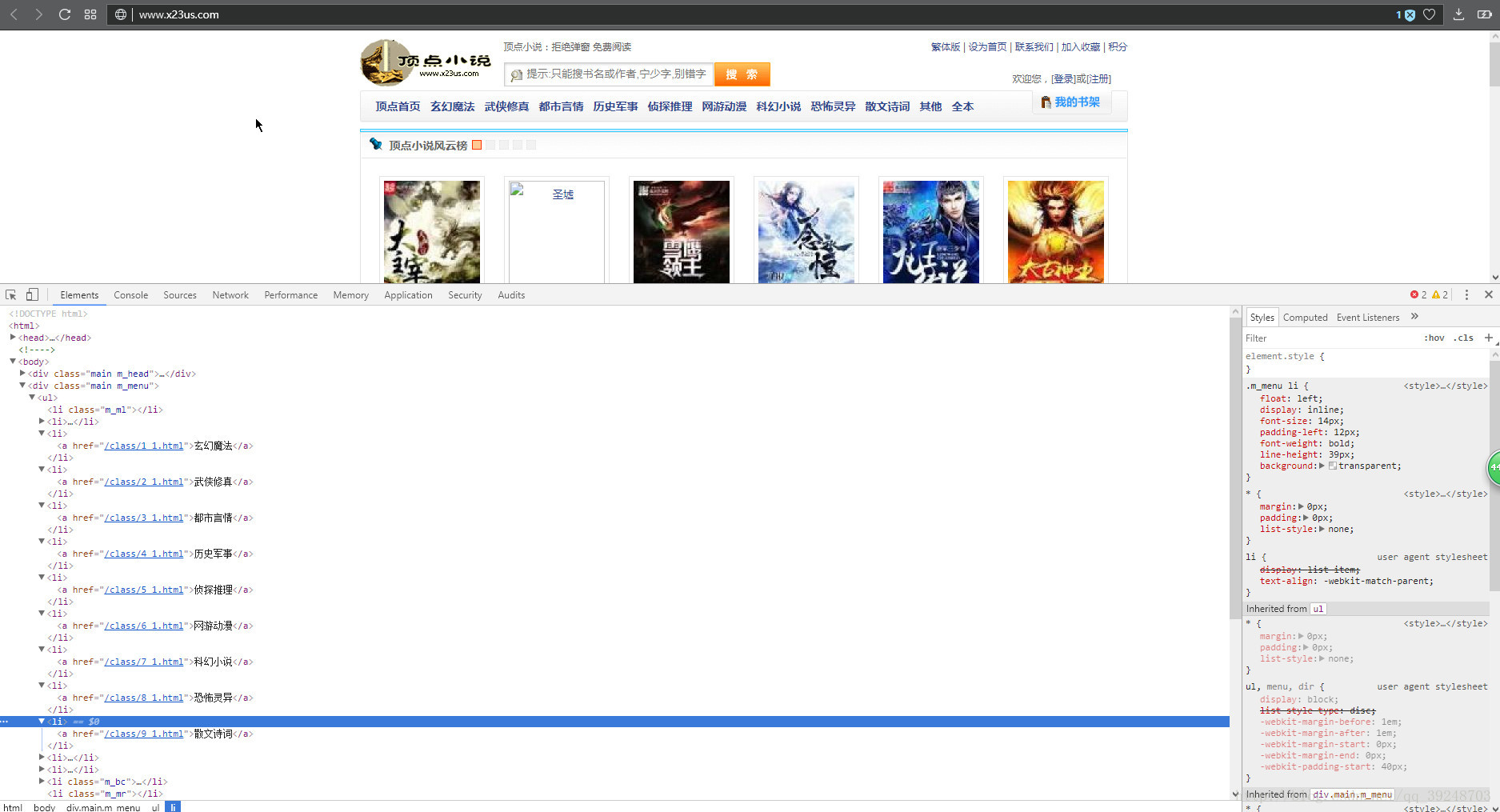
得到里面的链接后得到每个分类里面文章的链接,还有作者名称,入库的时候需要用。
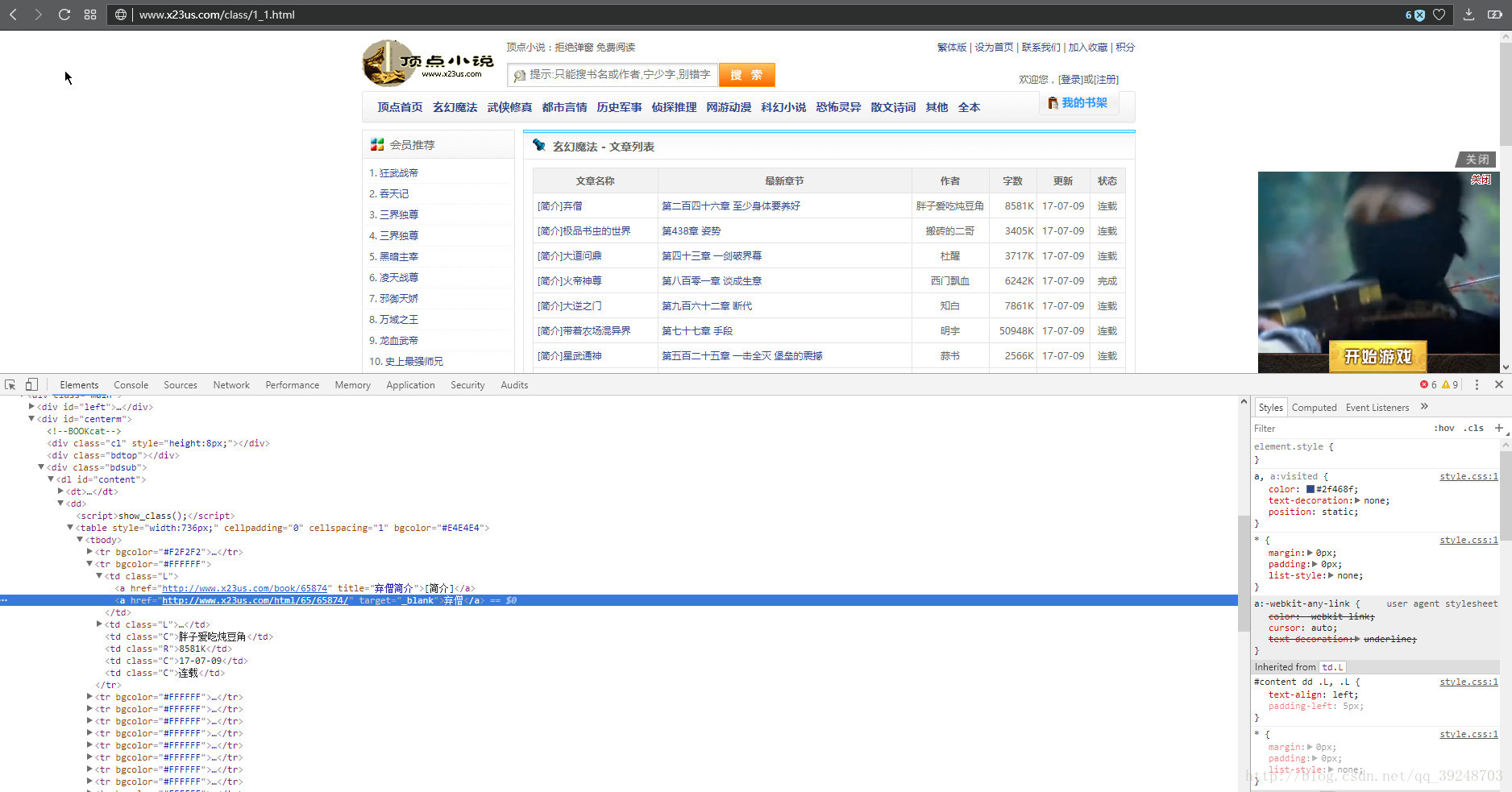
得到最大页数,翻页使用

得到文章的标题,还有章节链接,章节名称, 章节名称用于存库时候使用。
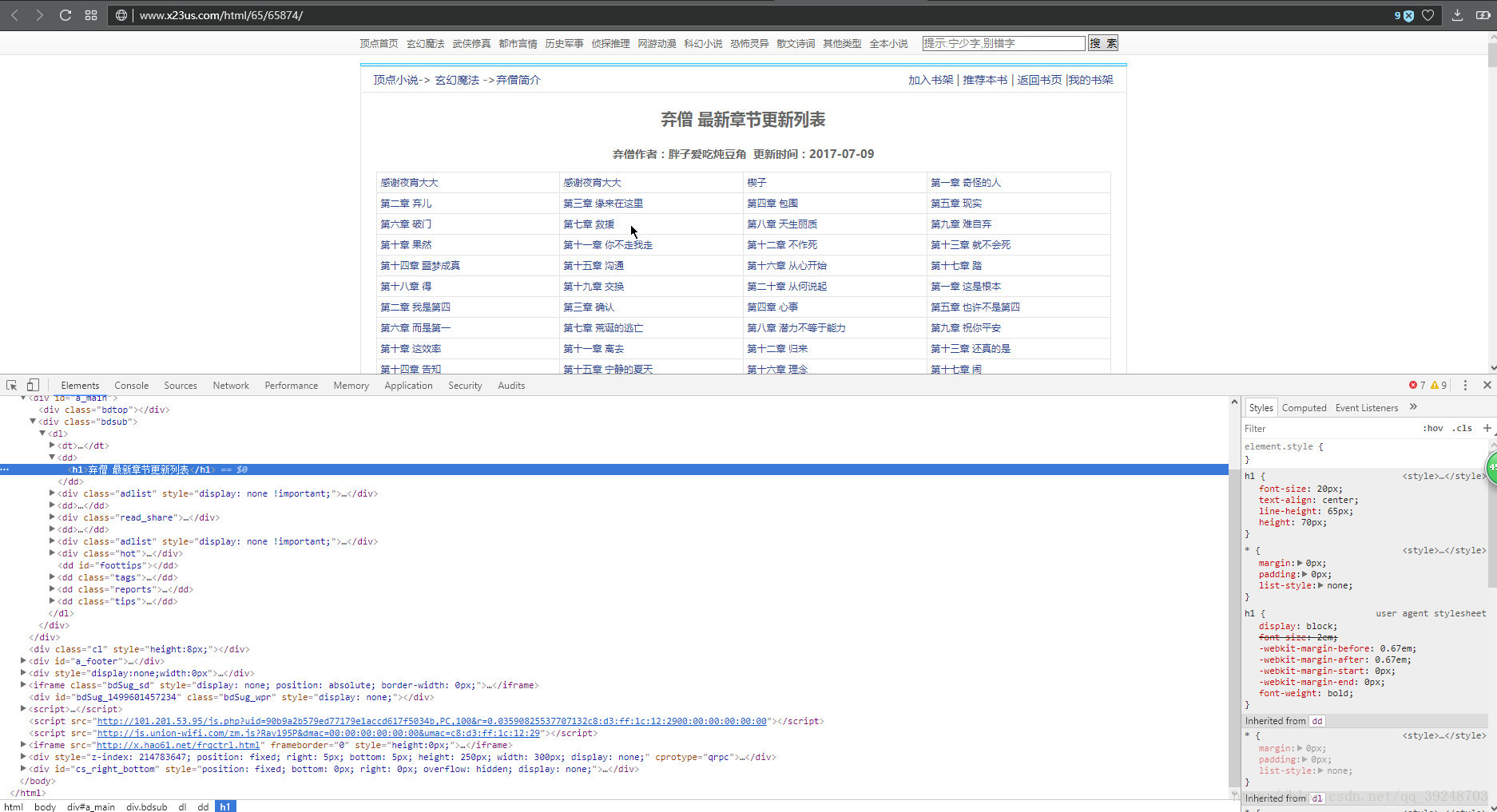
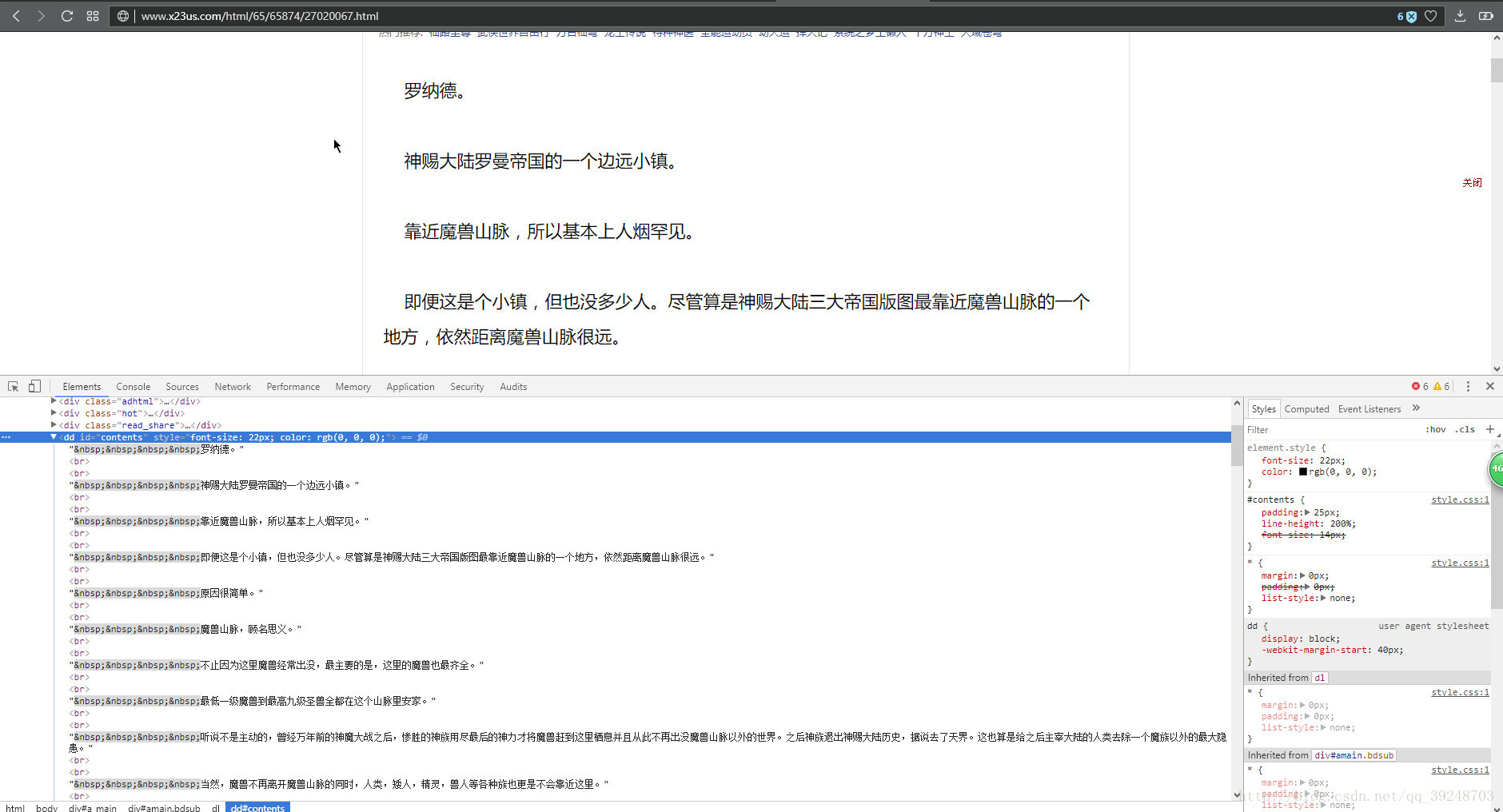
得到内容
1.首先分析整个网页结构 2.找到网页中的所有小说的分类链接 3.得到分类链接找到它们的翻页链接 4.提取其中的数据 5.入库mysql。
找到分类的链接
得到里面的链接后得到每个分类里面文章的链接,还有作者名称,入库的时候需要用。
得到最大页数,翻页使用
得到文章的标题,还有章节链接,章节名称, 章节名称用于存库时候使用。
得到内容
scrapy startproject project_dingdian scrapy genspider DingDian http://www.x23us.com/[/code]
sipder代码编写# -*- coding: utf-8 -*- import scrapy # 使用scrapy中的方法 from urllib import parse # 使用urllib中parse的解析方式 用于字符串拼接 from scrapy import Request # 使用request生成值 传入到下一个函数中 from dingdian.items import DingdianItem # 引入你定义的mysql字段 # 你的顶点类 class DiangdianSpider(scrapy.Spider): name = "diangdian" start_urls = ['http://www.x23us.com/'] # 你爬取的主网页 # 你的解析函数 def parse(self, response): # 得到你主网页中的分类的href链接 这里使用的是它自带的xpath方法 title = response.xpath('/html/body/div[2]/ul/li/a/@href').extract()[1:12] # 遍历你的到的所有链接 for i in title: # 得到url 有的网页上没有域名只有一点数据进行数据拼接 使用urllib中的parse进行拼接 并传入到下一个解析分页的函数中 yield Request(url=parse.urljoin(response.url, i), callback=self.parse_get) # 分页的解析函数 def parse_get(self, response): # 得到最大页数 name = response.xpath('//*[@id="pagelink"]/a[14]/text()').extract()[0] # 遍历最大页 for i in range(1, int(name)): if response.url != 'http://www.x23us.com/quanben/1': left_url = response.url[:-6] right_url = response.url[-5:] # 得到最大页进行拼接 yield Request(left_url + str(i) + right_url, callback=self.get_parse) else: # 传入到章节分析的函数中 yield Request(parse.urljoin(response.url, str(i)), callback=self.get_parse) # 文章节分析的函数 def get_parse(self, response): try: # 得到文章的url article_url = response.xpath('//*[@id="content"]/dd/table/tr/td/a/@href').extract()[1] # 作者名称 author = response.xpath('//*[@id="content"]/dd[1]/table/tr/td/text()').extract()[0] yield Request(article_url, callback=self.page_list, meta={'author': author}) # 传入到分析内容的函数中 except: pass # 章节 def page_list(self, response): # 小说的名称 title = response.xpath('//*[@id="a_main"]/div/dl/dd/h1/text()').extract()[0] # 章节的链接 content_url = response.xpath('//*[@id="at"]/tr/td/a/@href').extract()[0] # 传入到内容分析的函数中 并把小说的标题传入到下一个函数中 yield Request(parse.urljoin(response.url, content_url), callback=self.content_html, meta={'title': title, 'author': response.meta['author']}) # 内容的解析函数 def content_html(self, response): item = DingdianItem() # 引入定义存数据的item文件 # 找到文章的标题 title1 = response.xpath('//*[@id="amain"]/dl/dd[1]/h1/text()').extract()[0] item['book'] = response.meta['title'] # 书名 item['article_title'] = title1 # 文章的标题 item['author'] = response.meta['author'] # 作者 content_all = '' # 定一个空字符串 用来接受你得到的数据 # 文章的内容 返回一个列表 mysql不能直接存列表 content_con = response.xpath('//*[@id="contents"]/text()').extract() for i in content_con: # 遍历你的列表 content_all = content_all + i.strip() # 得到内容后 去除空格 加入到空字符串 item['content'] = content_all # 得到你的内容 yield item
pipelines编写# -*- coding: utf-8 -*- import pymysql # 用来链接mysql的第三方库 # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class DingdianPipeline(object): def process_item(self, item, spider): article_title = item['article_title'] # 定义文章名称的字段 author = item['author'] # 定义作者的字段 content = item['content'] # 定义内容的字段 book = item['book'] # 定义书名的字段 # 链接mysql conn = pymysql.connect(host='localhost', user='root', port=3307, passwd='123456', db='scrapy_pachong', charset='utf8') # 获取游标 cur = conn.cursor() # 插入你得到的数据 cur.execute("INSERT INTO 顶点(`作者`,`章节名称`,`书名`,`内容`) VALUES('%s','%s','%s','%s')" % (author,article_title,book,content)) conn.commit() conn.close() return item
items的编写# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class DingdianItem(scrapy.Item): # define the fields for your item here like: author = scrapy.Field() article_title = scrapy.Field() content = scrapy.Field() book = scrapy.Field()
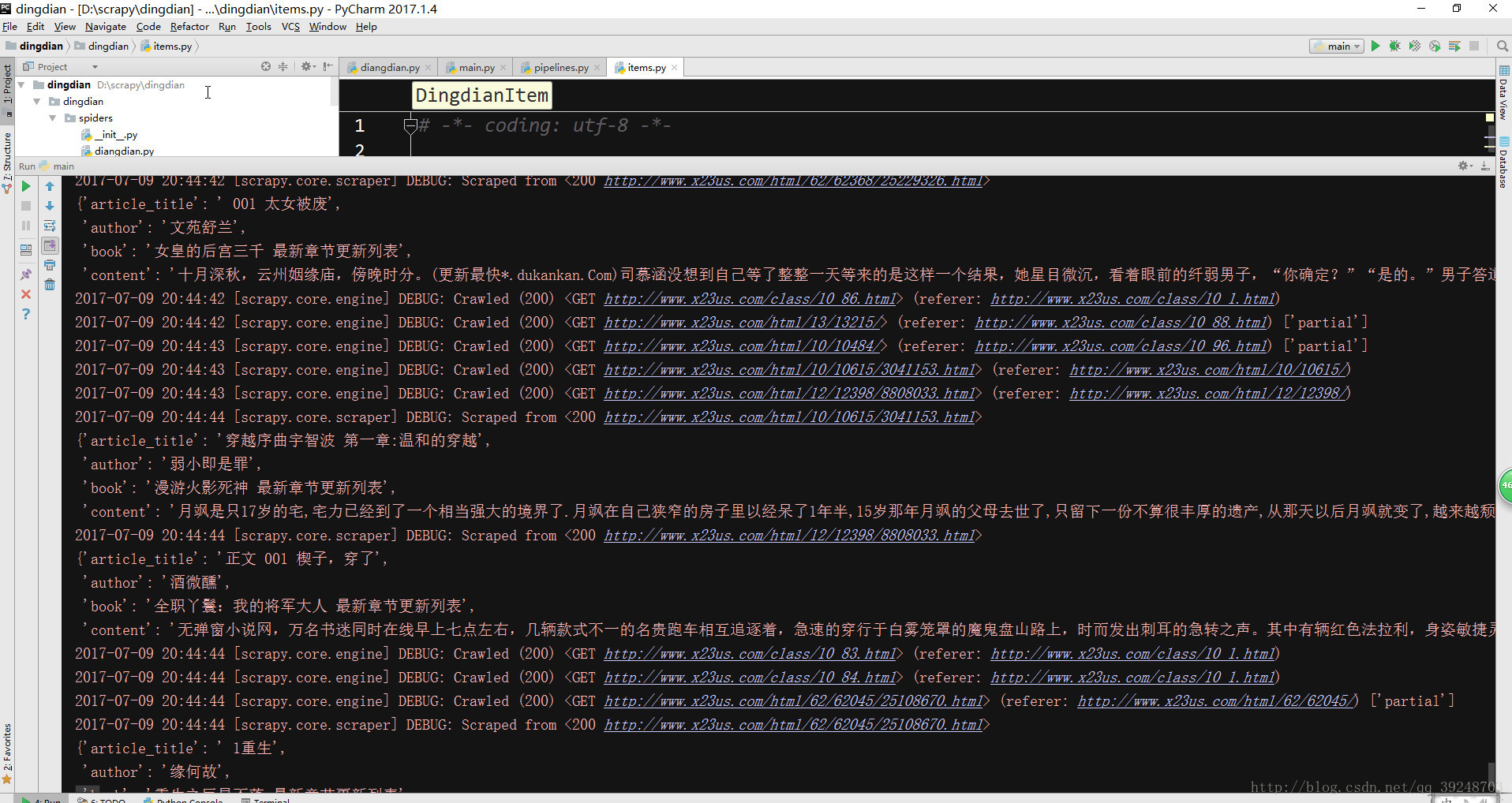
运行的结果
mysql中的数据.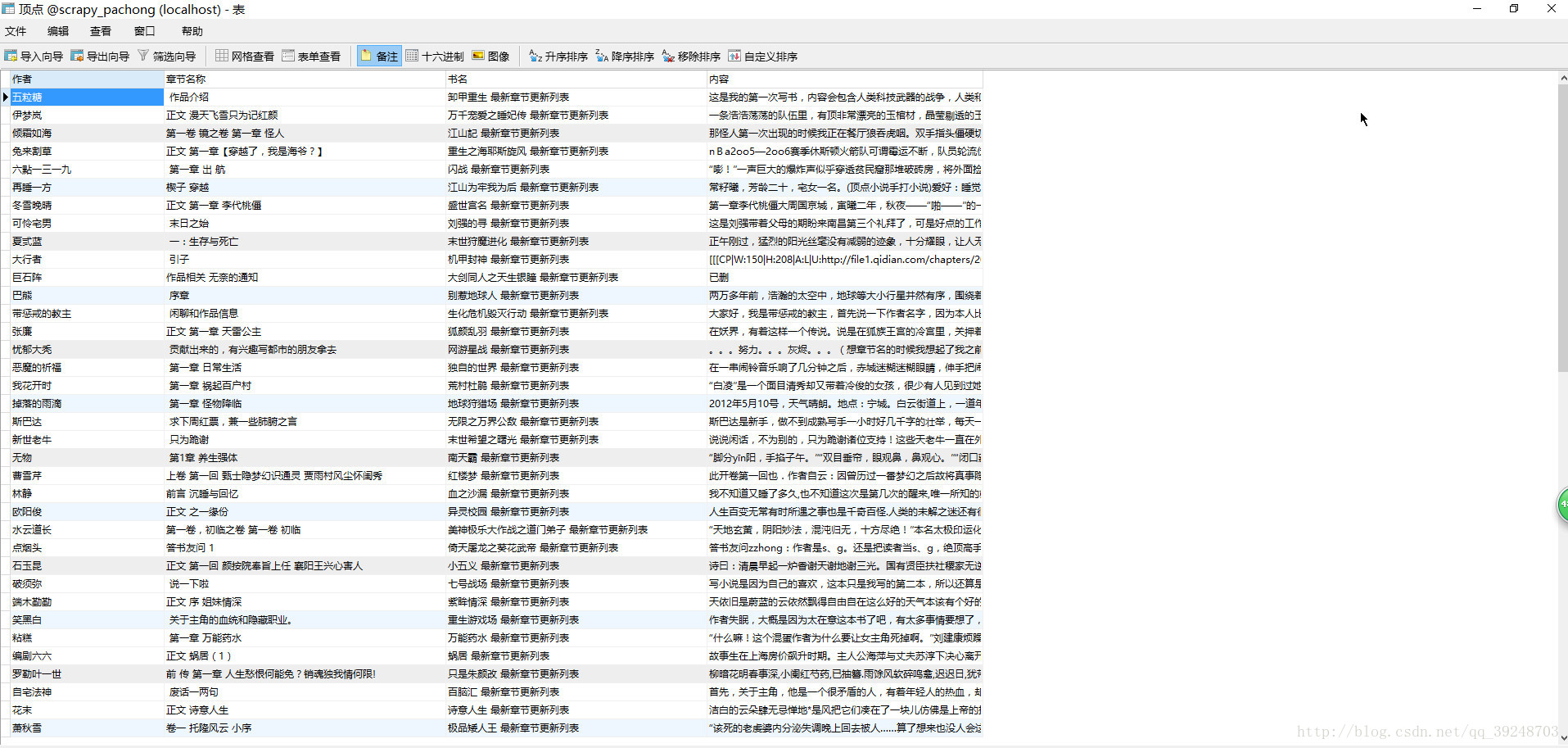

相关文章推荐
- 使用django+mysql+scrapy制作的一个小说网站
- 使用scrapy编写爬虫并入库Mysql全过程
- 使用scrapy 抓取顶点小说
- 使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
- 避免重复入库的插入记录方法-----mysql 使用记号
- ubuntu下使用wget备份整个网站
- 非英文网站如何使用MySQL的字符集
- 在godaddy的空间上发布使用MySql 和 Entity Framework做的网站时遇到的Security Exception
- linux下使用wget下载整个网站
- 使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
- ASP动态网站制作中使用MYSQL的分析
- 使用Scrapy建立一个网站抓取器
- [转] 网站架构文章和MySQL在国际知名网站中的使用量
- 使用scrapy制作的小说爬虫
- Python使用scrapy抓取网站sitemap信息的方法
- 使用scrapy爬取网站的商品数据
- 使用wget下载整个网站或目录【转】
- asp.net开发的网站中使用mysql
- 使用wget下载整个网站
- 使用PHP备份MySQL和网站发送到邮箱实例代码