启动Spark Shell,在Spark Shell中编写WordCount程序,在IDEA中编写WordCount的Maven程序,spark-submit使用spark的jar来做单词统计
2017-07-06 00:18
916 查看
1.启动Spark Shell
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。要注意的是要启动Spark-Shell需要先启动Spark-ha集群,Spark集群安装和部署参考:http://blog.csdn.net/tototuzuoquan/article/details/744815701.2.1、启动spark shell
启动方式一:[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# cd $SPARK_HOME [root@hadoop1 spark-2.1.1-bin-hadoop2.7]# pwd /home/tuzq/software/spark-2.1.1-bin-hadoop2.7 [root@hadoop1 spark-2.1.1-bin-hadoop2.7]# bin/spark-shell --master spark://hadoop1:7077,hadoop2:7077
通过使用–master指定master的地址,连接的是启动着的那个master
同样,还可以指定执行的内存数和总的核心数
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# cd $SPARK_HOME [root@hadoop1 spark-2.1.1-bin-hadoop2.7]# bin/spark-shell --master spark://hadoop1:7077,hadoop2:7077 --executor-memory 2g --total-executor-cores 2
参数说明:
–master spark://hadoop:7077 指定Master的地址
–executor-memory 2g 指定每个worker可用内存为2G
–total-executor-cores 2 指定整个集群使用的cup核数为2个
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
1.2.2、在spark shell中编写WordCount程序
1.首先启动hdfs2.向hdfs上传一个文件到hdfs(hdfs://mycluster/wordcount/input/2.txt)
效果图下:
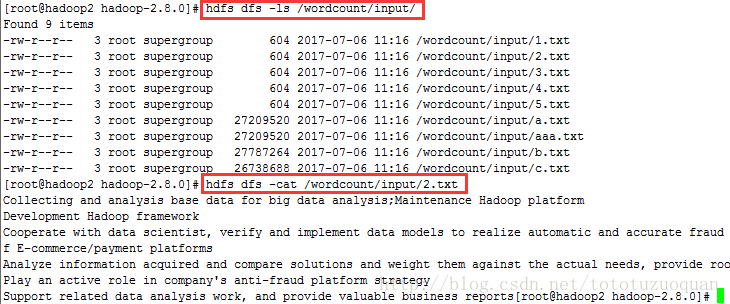
如果通过带有协议的方式访问hadoop集群上的文件可以通过下面的方式:
[root@hadoop2 hadoop-2.8.0]# hdfs dfs -ls hdfs://mycluster/ Found 2 items drwx-wx-wx - root supergroup 0 2017-07-06 11:11 hdfs://mycluster/tmp drwxr-xr-x - root supergroup 0 2017-07-06 11:16 hdfs://mycluster/wordcount [root@hadoop2 hadoop-2.8.0]# hdfs dfs -ls hdfs://mycluster/wordcount/input Found 9 items -rw-r--r-- 3 root supergroup 604 2017-07-06 11:16 hdfs://mycluster/wordcount/input/1.txt -rw-r--r-- 3 root supergroup 604 2017-07-06 11:16 hdfs://mycluster/wordcount/input/2.txt -rw-r--r-- 3 root supergroup 604 2017-07-06 11:16 hdfs://mycluster/wordcount/input/3.txt -rw-r--r-- 3 root supergroup 604 2017-07-06 11:16 hdfs://mycluster/wordcount/input/4.txt -rw-r--r-- 3 root supergroup 604 2017-07-06 11:16 hdfs://mycluster/wordcount/input/5.txt -rw-r--r-- 3 root supergroup 27209520 2017-07-06 11:16 hdfs://mycluster/wordcount/input/a.txt -rw-r--r-- 3 root supergroup 27209520 2017-07-06 11:16 hdfs://mycluster/wordcount/input/aaa.txt -rw-r--r-- 3 root supergroup 27787264 2017-07-06 11:16 hdfs://mycluster/wordcount/input/b.txt -rw-r--r-- 3 root supergroup 26738688 2017-07-06 11:16 hdfs://mycluster/wordcount/input/c.txt [root@hadoop2 hadoop-2.8.0]# hdfs dfs -ls hdfs://mycluster/wordcount/input/2.txt -rw-r--r-- 3 root supergroup 604 2017-07-06 11:16 hdfs://mycluster/wordcount/input/2.txt [root@hadoop2 hadoop-2.8.0]# hdfs dfs -cat hdfs://mycluster/wordcount/input/2.txt Collecting and analysis base data for big data analysis;Maintenance Hadoop platform Development Hadoop framework Cooperate with data scientist, verify and implement data models to realize automatic and accurate fraud detection, in order to improve the risk management level of E-commerce/payment platforms Analyze information acquired and compare solutions and weight them against the actual needs, provide root cause analysis affecting key business problems Play an active role in company's anti-fraud platform strategy Support related data analysis work, and provide valuable business reports[root@hadoop2 hadoop-2.8.0]#
3.在spark shell中用scala语言编写spark程序
scala> sc.textFile("hdfs://mycluster/wordcount/input/2.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://mycluster/wordcount/output")1.使用hdfs命令查看结果
[root@hadoop2 hadoop-2.8.0]# hdfs dfs -ls hdfs://mycluster/wordcount/output Found 3 items -rw-r--r-- 3 root supergroup 0 2017-07-06 11:48 hdfs://mycluster/wordcount/output/_SUCCESS -rw-r--r-- 3 root supergroup 400 2017-07-06 11:48 hdfs://mycluster/wordcount/output/part-00000 -rw-r--r-- 3 root supergroup 346 2017-07-06 11:48 hdfs://mycluster/wordcount/output/part-00001 [root@hadoop2 hadoop-2.8.0]# hdfs dfs -cat hdfs://mycluster/wordcount/output/part-00000 (role,1) (Play,1) (fraud,1) (level,1) (business,2) (improve,1) (platforms,1) (order,1) (big,1) (with,1) (scientist,,1) (active,1) (valuable,1) (data,5) (information,1) (Cooperate,1) (Collecting,1) (framework,1) (E-commerce/payment,1) (acquired,1) (root,1) (accurate,1) (solutions,1) (analysis;Maintenance,1) (problems,1) (them,1) (Analyze,1) (models,1) (analysis,3) (realize,1) (actual,1) (weight,1) [root@hadoop2 hadoop-2.8.0]#
说明:
sc是SparkContext对象,该对象时提交spark程序的入口
sc.textFile(“hdfs://mycluster/wordcount/input/2.txt”)是从hdfs中读取数据
flatMap(_.split(” “))先map在压平
map((_,1))将单词和1构成元组
reduceByKey(+)按照key进行reduce,并将value累加
saveAsTextFile(“hdfs://mycluster/wordcount/output”)将结果写入到hdfs中
将wordCound的结果排序,并显示的代码:
scala> sc.textFile("hdfs://mycluster/wordcount/input/2.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
res2: Array[(String, Int)] = Array((and,6), (data,5), (analysis,3), (business,2), (to,2), (platform,2), (in,2), (provide,2), (the,2), (Hadoop,2), (compare,1), (risk,1), (anti-fraud,1), (key,1), (related,1), (base,1), (Support,1), (against,1), (automatic,1), (company's,1), (needs,,1), (implement,1), (affecting,1), (strategy,1), (of,1), (reports,1), (management,1), (detection,,1), (for,1), (work,,1), (cause,1), (an,1), (verify,1), (Development,1), (role,1), (Play,1), (fraud,1), (level,1), (improve,1), (platforms,1), (order,1), (big,1), (with,1), (scientist,,1), (active,1), (valuable,1), (information,1), (Cooperate,1), (Collecting,1), (framework,1), (E-commerce/payment,1), (acquired,1), (root,1), (accurate,1), (solutions,1), (analysis;Maintenance,1), (problems,1), (them,1), (Analyze,1), (m...
scala>2、idea中创建spark的maven工程
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。创建Maven工程:

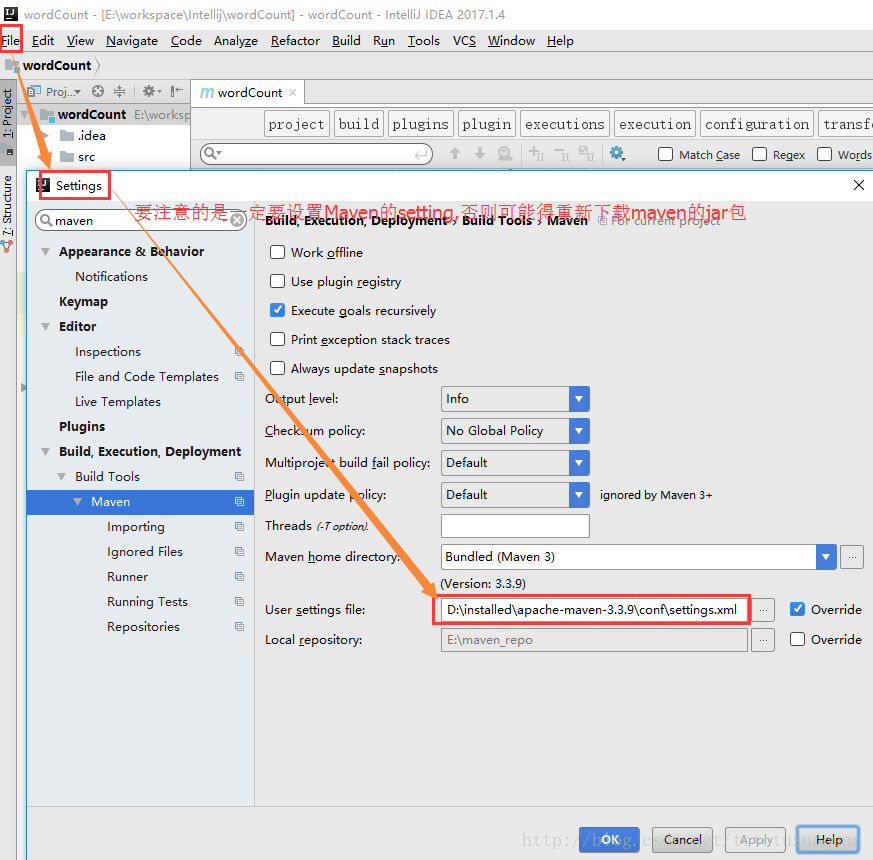
要注意的是,在创建好项目之后,一定要重新制定好Maven仓库所在的位置,不然可能会导致重新下载jar包:
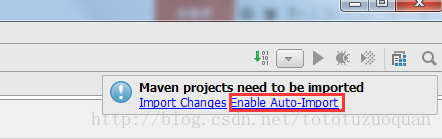
创建好maven项目后,点击Enable Auto-Import
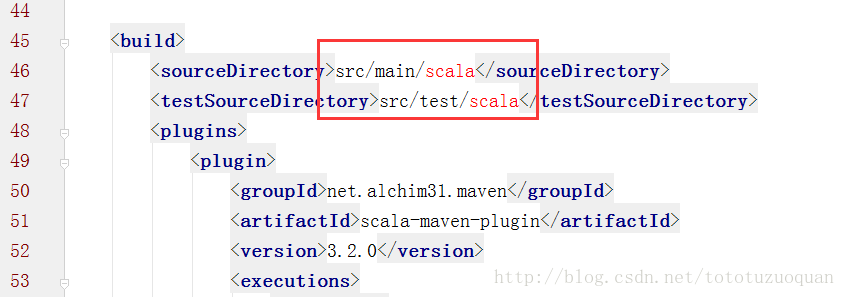
配置Maven的pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.toto.spark</groupId> <artifactId>wordCount</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.10.6</scala.version> <scala.compat.version>2.10</scala.compat.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.5.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.5.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.2</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-make:transitive</arg> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.18.1</version> <configuration> <useFile>false</useFile> <disableXmlReport>true</disableXmlReport> <includes> <include>**/*Test.*</include> <include>**/*Suite.*</include> </includes> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>cn.toto.spark.WordCount</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
将src/main/java和src/test/java分别修改成src/main/scala和src/test/scala(或者创建scala的Directory),与pom.xml中的配置保持一致
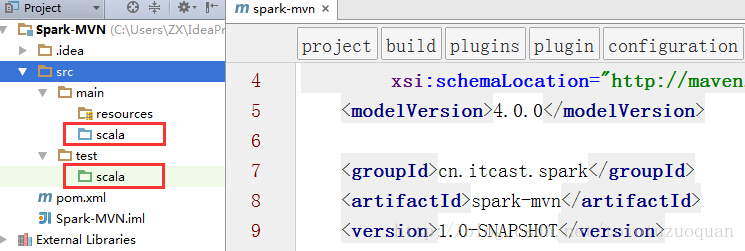
或者通过如下方式:
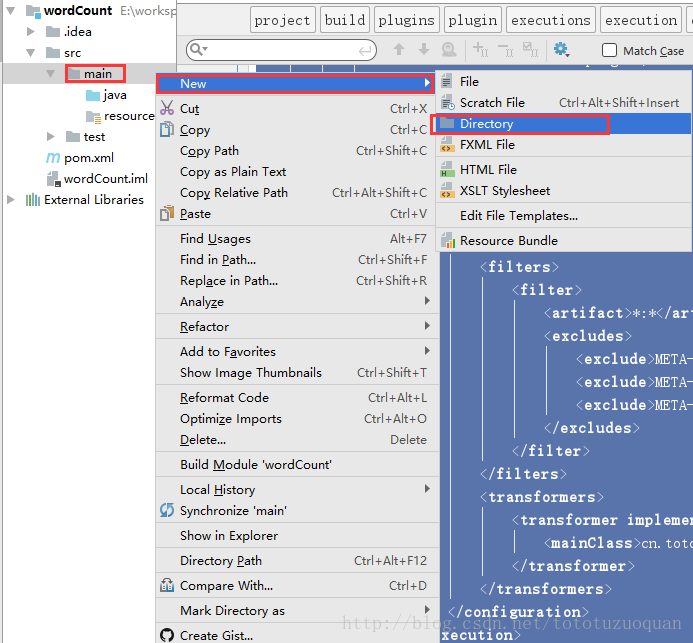
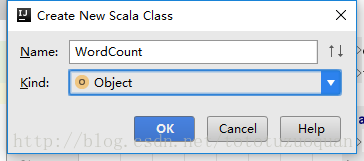
新建一个scala class,类型为Object
编写spark程序代码:
package cn.toto.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by toto on 2017/7/6.
*/
object WordCount {
def main(args: Array[String]): Unit = {
//创建sparkconf
val conf=new SparkConf().setAppName("WordCount")
//创建sparkcontext
val sc=new SparkContext(conf)
//读取hdfs中的数据
val line:RDD[String]=sc.textFile(args(0))
//切分单词
val words:RDD[String]=line.flatMap(_.split(" "))
//将单词计算
val wordAndOne:RDD[(String,Int)]=words.map((_,1))
//分组聚合
val result:RDD[(String,Int)]=wordAndOne.reduceByKey((x,y)=>x+y)
//排序
val finalResult:RDD[(String,Int)]=result.sortBy(_._2,false)
//将数据存到HDFS中
finalResult.saveAsTextFile(args(1))
//释放资源
sc.stop()
}
}打包:

进入工程的target目录下面,获取jar包
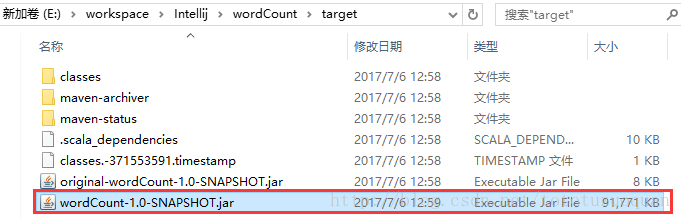
或者直接在IDEA的工程目录下找到:
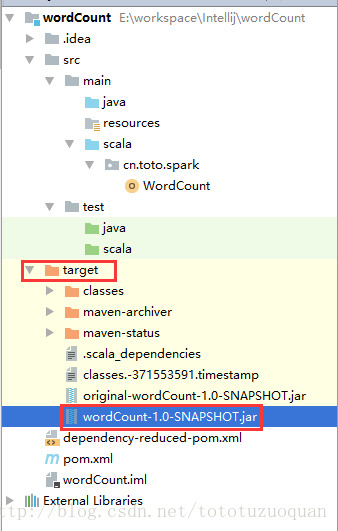
将wordCount-1.0-SNAPSHOT.jar上传到/home/tuzq/software/sparkdata下
使用spark的jar来做单词统计
要注意的是最后的输出路径要不存在,并且运行下面的程序的时候,最好是把spark-shell给关闭了。否则可能会报错。
bin/spark-submit --master spark://hadoop1:7077,hadoop2:7077 --executor-memory 512m --total-executor-cores 6 --class cn.toto.spark.WordCount /home/tuzq/software/sparkdata/wordCount-1.0-SNAPSHOT.jar hdfs://mycluster/wordcount/input hdfs://mycluster/wordcount/out0001
运行时的状态:

查看hdfs上的结果:
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# hdfs dfs -ls hdfs://mycluster/wordcount/out0002 Found 10 items -rw-r--r-- 3 root supergroup 0 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/_SUCCESS -rw-r--r-- 3 root supergroup 191 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00000 -rw-r--r-- 3 root supergroup 671 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00001 -rw-r--r-- 3 root supergroup 245 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00002 -rw-r--r-- 3 root supergroup 31 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00003 -rw-r--r-- 3 root supergroup 1096 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00004 -rw-r--r-- 3 root supergroup 11 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00005 -rw-r--r-- 3 root supergroup 936 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00006 -rw-r--r-- 3 root supergroup 588 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00007 -rw-r--r-- 3 root supergroup 609 2017-07-06 13:13 hdfs://mycluster/wordcount/out0002/part-00008
查看其中的任何一个:
[root@hadoop1 spark-2.1.1-bin-hadoop2.7]# hdfs dfs -cat hdfs://mycluster/wordcount/out0002/part-00000 (and,770752) (is,659375) (I,505440) (a,468642) (to,431857) (in,421230) (the,331176) (of,272080) (FDS,218862) (for,213029) (The,196569) (true,196567) (but,196566) (on,193650) (without,193649) [root@hadoop1 spark-2.1.1-bin-hadoop2.7]#

相关文章推荐
- idea+maven+scala创建wordcount,打包jar并在spark on yarn上运行(可以使用)
- 在IDEA中编写Spark的WordCount程序
- idea+maven+scala创建wordcount,打包jar并在spark on yarn上运行
- idea+maven+scala创建wordcount,打包jar并在spark on yarn上运行
- windows下使用idea maven配置spark运行环境、运行WordCount例子以及碰到的问题
- spark shell中编写WordCount程序
- Idea 使用Maven创建Spark WordCount 案例
- windows下idea编写WordCount程序,并打jar包上传到hadoop集群运行
- hadoop的统计单词程序WordCount
- 使用eclipse开发spark程序 wordcount 事例
- Spark学习(二):使用Spark开发wordcount程序
- Idea创建maven工程 上传提交Spark运行 WordCount 配置依赖插件文件 全步骤
- linux环境下编写shell脚本启动和关闭jar包服务程序
- 使用Pyspark编写wordcount程序
- Hadoop集群初步使用-编写wordcount程序
- 运行Hadoop自带的wordcount单词统计程序
- storm程序-单词统计wordcount
- maven构建Scala程序,实现spark的wordcount
- Spark实战----(1)使用Scala开发本地测试的Spark WordCount程序
- go语言之map练习(二):编写一个程序wordfreq程序,统计输入文本中每个单词出现的频率(次数)