机器学习与深度学习(一) 决策树算法 (Decision Tree)
2017-06-27 14:39
459 查看
____tz_zs学习笔记
熵(entropy)概念:
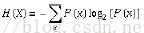
决策树归纳算法(ID3):
1970-1980,J.Ross.Quinlan,ID3算法
选择属性判断结点
信息获取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)
通过一个来作为节点分类获取了多少信息

类似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,选择age作为第一个根节点
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'/home/zhoumiao/MachineLearning/01decisiontree/AllElectronics.csv', 'rb')
reader = csv.reader(allElectronicsData)
headers = reader.next()
print(headers)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1])
rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
# Vetorize features
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
# Using decision tree for classification
# clf = tree.DecisionTreeClassifier()
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
with open("allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
python3要修改一些方法的使用规则。
代码逻辑:
①前一部分为读取文件
②将数据矢量化(变为0,1)
③之后训练决策树
④将决策树可视化:先写如点格式文件,然后使用Graphviz的软件转化为PDF格式
⑤使用决策树预测标签
# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
import numpy as np
np.set_printoptions(threshold = 1e6)#设置打印数量的阈值
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'AllElectronics.csv', 'r')
reader = csv.reader(allElectronicsData)
#headers = reader.next()
headers = next(reader)
print(headers)
print("~"*10+"headers end"+"~"*10)
featureList = []
labelList = []
for row in reader: # 遍历每一列
labelList.append(row[len(row)-1]) # 标签列表
rowDict = {} # 每一行的所有特征放入一个字典
for i in range(1, len(row)-1): # 左闭右开 遍历从age到credit_rating
rowDict[headers[i]] = row[i] # 字典的赋值
featureList.append(rowDict) #将每一行的特征字典装入特征列表内
print(featureList)
print("~"*10+"featureList end"+"~"*10)
# Vetorize features
vec = DictVectorizer() # Vectorizer 矢量化
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("~"*10+"dummyX end"+"~"*10)
print("labelList: " + str(labelList))
print("~"*10+"labelList end"+"~"*10)
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
print("~"*10+"dummyY end"+"~"*10)
# Using decision tree for classification
# clf = tree.DecisionTreeClassifier()
clf = tree.DecisionTreeClassifier(criterion='entropy') # 标准 熵
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
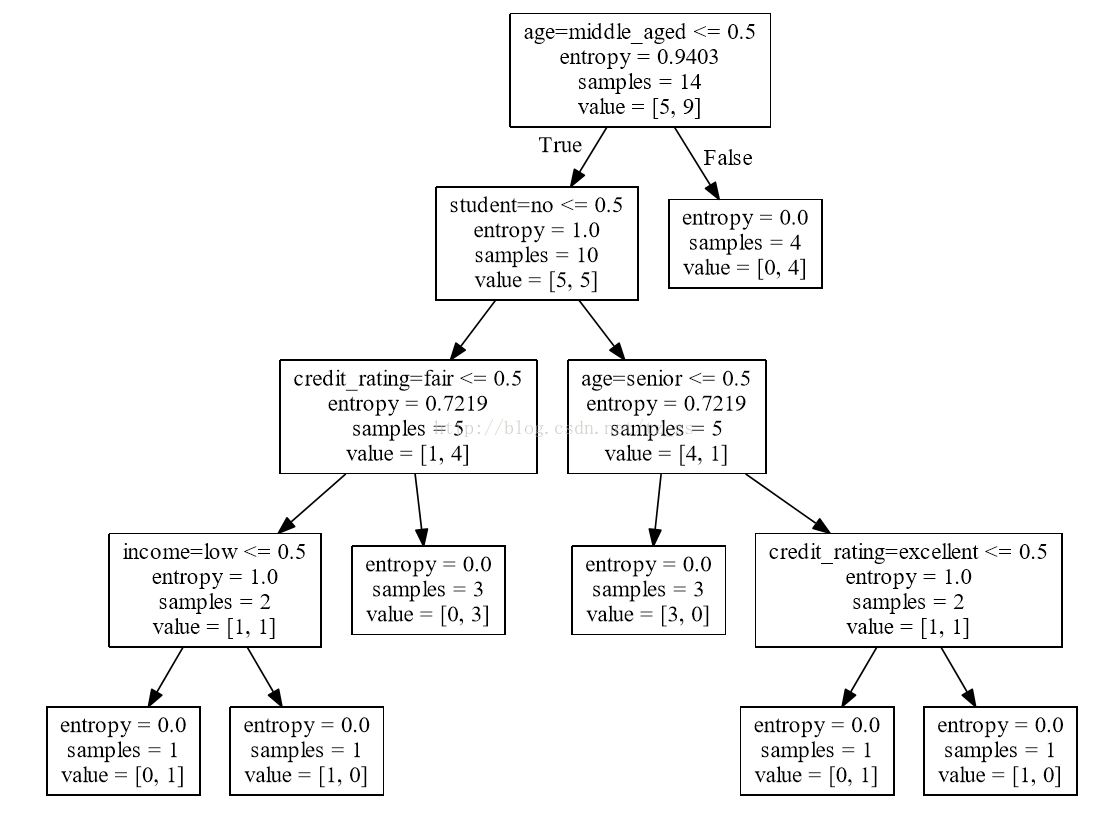
with open("allElectronicInformationGainOri.dot", 'w') as f:
# 输出到dot文件里,安装 Graphviz软件后,可使用 dot -Tpdf allElectronicInformationGainOri.dot -o outpu.pdf 命令 转化dot文件至pdf可视化决策树
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
点文件内容:
有向图树{
node [shape = box];
0 [label =“age = middle_aged <= 0.5 \ nentropy = 0.9403 \ nsamples = 14 \ nvalue = [5,9]”];
1 [label =“student = yes <= 0.5 \ nentropy = 1.0 \ nsamples = 10 \ nvalue = [5,5]”];
0 - > 1 [labeldistance = 2.5,labelangle = 45,headlabel =“True”];
2 [label =“age = senior <= 0.5 \ nentropy = 0.7219 \ nsamples = 5 \ nvalue = [4,1]”];
1 - > 2;
3 [label =“entropy = 0.0 \ nsamples = 3 \ nvalue = [3,0]”];
2 - > 3
c7f6
;
4 [label =“credit_rating = excellent <= 0.5 \ nentropy = 1.0 \ nsamples = 2 \ nvalue = [1,1]”];
2 - > 4;
5 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [0,1]”];
4 - > 5;
6 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [1,0]”];
4 - > 6;
7 [label =“credit_rating = excellent <= 0.5 \ nentropy = 0.7219 \ nsamples = 5 \ nvalue = [1,4]”];
1 - > 7;
8 [label =“entropy = 0.0 \ nsamples = 3 \ nvalue = [0,3]”];
7 - > 8;
9 [label =“income = medium <= 0.5 \ nentropy = 1.0 \ nsamples = 2 \ nvalue = [1,1]”];
7 - > 9;
10 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [1,0]”];
9 - > 10;
11 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [0,1]”];
9 - > 11;
12 [label =“entropy = 0.0 \ nsamples = 4 \ nvalue = [0,4]”];
0 - > 12 [labeldistance = 2.5,labelangle = -45,headlabel =“False”];
}
PDF内容:
代码运行输出:
['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
~~~~~~~~~~headers end~~~~~~~~~~
[{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
~~~~~~~~~~featureList end~~~~~~~~~~
dummyX: [[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[ 0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
~~~~~~~~~~dummyX end~~~~~~~~~~
labelList: ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
~~~~~~~~~~labelList end~~~~~~~~~~
dummyY: [[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
~~~~~~~~~~dummyY end~~~~~~~~~~
clf: DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
oneRowX: [ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
newRowX: [ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY: [1]
决策树算法:
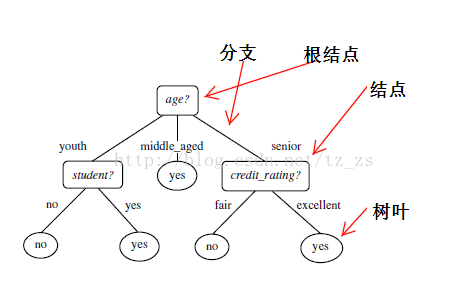
决策树(decision tree)是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。熵(entropy)概念:
决策树归纳算法(ID3):
1970-1980,J.Ross.Quinlan,ID3算法
选择属性判断结点
信息获取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)
通过一个来作为节点分类获取了多少信息
类似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,选择age作为第一个根节点
应用案例:
课程中python2中的代码from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'/home/zhoumiao/MachineLearning/01decisiontree/AllElectronics.csv', 'rb')
reader = csv.reader(allElectronicsData)
headers = reader.next()
print(headers)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1])
rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
# Vetorize features
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
# Using decision tree for classification
# clf = tree.DecisionTreeClassifier()
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
with open("allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
python3要修改一些方法的使用规则。
代码逻辑:
①前一部分为读取文件
②将数据矢量化(变为0,1)
③之后训练决策树
④将决策树可视化:先写如点格式文件,然后使用Graphviz的软件转化为PDF格式
⑤使用决策树预测标签
# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
import numpy as np
np.set_printoptions(threshold = 1e6)#设置打印数量的阈值
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'AllElectronics.csv', 'r')
reader = csv.reader(allElectronicsData)
#headers = reader.next()
headers = next(reader)
print(headers)
print("~"*10+"headers end"+"~"*10)
featureList = []
labelList = []
for row in reader: # 遍历每一列
labelList.append(row[len(row)-1]) # 标签列表
rowDict = {} # 每一行的所有特征放入一个字典
for i in range(1, len(row)-1): # 左闭右开 遍历从age到credit_rating
rowDict[headers[i]] = row[i] # 字典的赋值
featureList.append(rowDict) #将每一行的特征字典装入特征列表内
print(featureList)
print("~"*10+"featureList end"+"~"*10)
# Vetorize features
vec = DictVectorizer() # Vectorizer 矢量化
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("~"*10+"dummyX end"+"~"*10)
print("labelList: " + str(labelList))
print("~"*10+"labelList end"+"~"*10)
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
print("~"*10+"dummyY end"+"~"*10)
# Using decision tree for classification
# clf = tree.DecisionTreeClassifier()
clf = tree.DecisionTreeClassifier(criterion='entropy') # 标准 熵
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
with open("allElectronicInformationGainOri.dot", 'w') as f:
# 输出到dot文件里,安装 Graphviz软件后,可使用 dot -Tpdf allElectronicInformationGainOri.dot -o outpu.pdf 命令 转化dot文件至pdf可视化决策树
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
点文件内容:
有向图树{
node [shape = box];
0 [label =“age = middle_aged <= 0.5 \ nentropy = 0.9403 \ nsamples = 14 \ nvalue = [5,9]”];
1 [label =“student = yes <= 0.5 \ nentropy = 1.0 \ nsamples = 10 \ nvalue = [5,5]”];
0 - > 1 [labeldistance = 2.5,labelangle = 45,headlabel =“True”];
2 [label =“age = senior <= 0.5 \ nentropy = 0.7219 \ nsamples = 5 \ nvalue = [4,1]”];
1 - > 2;
3 [label =“entropy = 0.0 \ nsamples = 3 \ nvalue = [3,0]”];
2 - > 3
c7f6
;
4 [label =“credit_rating = excellent <= 0.5 \ nentropy = 1.0 \ nsamples = 2 \ nvalue = [1,1]”];
2 - > 4;
5 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [0,1]”];
4 - > 5;
6 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [1,0]”];
4 - > 6;
7 [label =“credit_rating = excellent <= 0.5 \ nentropy = 0.7219 \ nsamples = 5 \ nvalue = [1,4]”];
1 - > 7;
8 [label =“entropy = 0.0 \ nsamples = 3 \ nvalue = [0,3]”];
7 - > 8;
9 [label =“income = medium <= 0.5 \ nentropy = 1.0 \ nsamples = 2 \ nvalue = [1,1]”];
7 - > 9;
10 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [1,0]”];
9 - > 10;
11 [label =“entropy = 0.0 \ nsamples = 1 \ nvalue = [0,1]”];
9 - > 11;
12 [label =“entropy = 0.0 \ nsamples = 4 \ nvalue = [0,4]”];
0 - > 12 [labeldistance = 2.5,labelangle = -45,headlabel =“False”];
}
PDF内容:
代码运行输出:
['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
~~~~~~~~~~headers end~~~~~~~~~~
[{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
~~~~~~~~~~featureList end~~~~~~~~~~
dummyX: [[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[ 0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
~~~~~~~~~~dummyX end~~~~~~~~~~
labelList: ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
~~~~~~~~~~labelList end~~~~~~~~~~
dummyY: [[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
~~~~~~~~~~dummyY end~~~~~~~~~~
clf: DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
oneRowX: [ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
newRowX: [ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY: [1]

相关文章推荐
- 机器学习(三)决策树算法Decision Tree
- 如何提高深度学习(和机器学习)的性能
- 机器学习——深度学习(Deep Learning)
- 【转】机器学习和神经科学:你的大脑也在进行深度学习吗?
- [置顶] 机器学习决策树算法解决图像识别
- 机器学习和深度学习资源汇总(陆续更新)
- 机器学习(九):神经网络(2)——深度学习
- 浅析对人工智能,机器学习和深度学习的理解
- 机器学习——深度学习(Deep Learning)
- 机器学习之决策树 Decision Tree(一)
- 使用腾讯云 GPU 学习深度学习系列之一:传统机器学习的回顾
- 机器学习——深度学习(Deep Learning)
- Udacity深度学习第一讲:从机器学习到深度学习
- 简单读懂人工智能:机器学习与深度学习是什么关系
- 人工智能、机器学习和深度学习的区别
- Decision Tree 决策树算法Python实现
- 机器学习中的决策树算法
- 机器学习/深度学习/自然语言处理学习路线
- 机器学习和深度学习的最佳框架
- 信息增益以及决策树算法-机器学习实战(python)