机器学习 聚类(Clustering)____K-均值聚类算法(K-means Clustering) 层次聚类(Hierarchical Clustering)
2017-07-05 23:10
399 查看
____tz_zs学习笔记
聚类(Clustering) 顾名思义,就是将相似样本聚合在一起,属于机器学习中的非监督学习 (unsupervised learning) 问题。聚类的目标是找到相近的数据点,并将相近的数据点聚合在一起。
实现聚类的算法主要有:
1.K-均值聚类算法
2.层次聚类
优点:
原理简单
速度快
对大数据集有比较好的伸缩性
缺点:
需要指定聚类 数量K
对异常值敏感
对初始值敏感
算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类,以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
算法思想:
以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果
算法描述:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
算法流程:
输入:k, data
;
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data
, 分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
·# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
import numpy as np
# Function: K Means
# -------------
# K-Means is an algorithm that takes in a dataset and a constant
# k and returns k centroids (which define clusters of data in the
# dataset which are similar to one another).
# 定义kmeans方法 (数据集,划分为k类,停止的条件)
def kmeans(X, k, maxIt):
numPoints, numDim = X.shape # 获取多少行(实例数) 多少列(维度)
dataSet = np.zeros((numPoints, numDim + 1))
dataSet[:, :-1] = X
# Initialize centroids randomly 随机的初始化中心点
centroids = dataSet[np.random.randint(numPoints, size = k), :]
# centroids = dataSet[0:2, :]
#Randomly assign labels to initial centorid 分配标签
centroids[:, -1] = range(1, k +1)
# Initialize book keeping vars.
iterations = 0
oldCentroids = None
# Run the main k-means algorithm
while not shouldStop(oldCentroids, centroids, iterations, maxIt):
print "iteration: \n", iterations # 迭代次数
print "dataSet: \n", dataSet
print "centroids: \n", centroids
# Save old centroids for convergence test. Book keeping.
oldCentroids = np.copy(centroids)
iterations += 1
# Assign labels to each datapoint based on centroids 更新归类
updateLabels(dataSet, centroids)
# Assign centroids based on datapoint labels 更新中心点
centroids = getCentroids(dataSet, k)
# We can get the labels too by calling getLabels(dataSet, centroids)
return dataSet
# Function: Should Stop
# -------------
# Returns True or False if k-means is done. K-means terminates either
# because it has run a maximum number of iterations OR the centroids
# stop changing.
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids, centroids)
# Function: Get Labels
# -------------
# Update a label for each piece of data in the dataset.
def updateLabels(dataSet, centroids):
# For each element in the dataset, chose the closest centroid.
# Make that centroid the element's label.
numPoints, numDim = dataSet.shape
for i in range(0, numPoints):
dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i, :-1], centroids)
# (数据集中的一行,中心点)
def getLabelFromClosestCentroid(dataSetRow, centroids):
label = centroids[0, -1];
minDist = np.linalg.norm(dataSetRow - centroids[0, :-1])
for i in range(1 , centroids.shape[0]):
dist = np.linalg.norm(dataSetRow - centroids[i, :-1])
if dist < minDist:
minDist = dist
label = centroids[i, -1]
print "minDist:", minDist
return label
# Function: Get Centroids
# -------------
# Returns k random centroids, each of dimension n.
def getCentroids(dataSet, k):
# Each centroid is the geometric mean of the points that
# have that centroid's label. Important: If a centroid is empty (no points have
# that centroid's label) you should randomly re-initialize it.
result = np.zeros((k, dataSet.shape[1]))
for i in range(1, k + 1):
oneCluster = dataSet[dataSet[:, -1] == i, :-1]
result[i - 1, :-1] = np.mean(oneCluster, axis = 0)
result[i - 1, -1] = i
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1, x2, x3, x4)) # 组成矩阵
result = kmeans(testX, 2, 10)
print "final result:"
print result
·
"""
@author: tz_zs
k-means
"""
sklearn.cluster.KMeans(
n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm='auto'
)
'''
n_clusters: 簇的个数,即你想聚成几类
init: 初始簇中心的获取方法
n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。
max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
tol: 容忍度,即kmeans运行准则收敛的条件
precompute_distances: 是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内
存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实
现的方法是利用Cpython 来实现的
verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
random_state: 随机生成簇中心的状态条件。
copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都
会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内
存机制才会比较清楚。
n_jobs: 并行设置
algorithm: kmeans的实现算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
'''·
sklearn.cluster.KMeans的使用1
# -*- coding: utf-8 -*-
"""
@author: tz_zs
sklearn.cluster.KMeans的使用1
"""
from sklearn.cluster import KMeans
import numpy as np
# 生成10*3的矩阵
data = np.random.rand(10, 3)
print(data)
# 聚类为4
estimator = KMeans(n_clusters=4) # 返回KMeans对象
# fit_predict表示拟合+预测,也可以分开写
res = estimator.fit_predict(data) # 返回预测类别标签结果
'''
fit = estimator.fit(data) # 返回此KMeans对象,fit==estimator
res2 = estimator.predict(data) # 返回预测类别标签结果
print("product:", res2)
# res3 = estimator.fit(data).predict(data) # 返回预测类别标签结果
'''
# 预测类别标签结果
lable_pred = estimator
df26
.labels_
# 各个类别的聚类中心值
centroids = estimator.cluster_centers_
# 聚类中心均值向量的总和
inertia = estimator.inertia_
print("lable_pred:", lable_pred)
print("centroids:", centroids)
print("inertia:", inertia)
'''
结果:
[[ 0.84806828 0.12835109 0.49866577]
[ 0.05612908 0.60932968 0.18321125]
[ 0.06626165 0.88874957 0.99578568]
[ 0.44475794 0.0689524 0.5608716 ]
[ 0.70856172 0.35226933 0.12178557]
[ 0.04791486 0.66868388 0.01066914]
[ 0.72677149 0.46552559 0.61079303]
[ 0.82953259 0.88425252 0.52384649]
[ 0.87558294 0.3417068 0.20297633]
[ 0.86283938 0.51308292 0.85950813]]
lable_pred: [1 0 2 1 1 0 3 3 1 3]
centroids: [[ 0.05202197 0.63900678 0.0969402 ]
[ 0.71924272 0.22281991 0.34607482]
[ 0.06626165 0.88874957 0.99578568]
[ 0.80638115 0.62095368 0.66471589]]
inertia: 0.512747537743
'''
·
sklearn.cluster.KMeans的使用2# -*- coding: utf-8 -*-
"""
@author: tz_zs
sklearn.cluster.KMeans的使用2
"""
from sklearn.cluster import KMeans
from sklearn.externals import joblib
import numpy as np
import matplotlib.pyplot as plt
data = np.random.rand(100, 2)
estimator = KMeans(n_clusters=3)
res = estimator.fit_predict(data)
lable_pred = estimator.labels_
centroids = estimator.cluster_centers_
inertia = estimator.inertia_
print("lable_pred:", lable_pred)
print("centroids:", centroids)
print("inertia:", inertia)
'''
lable_pred: [2 0 2 0 1 0 2 2 1 2 0 1 2 2 0 0 0 2 2 1 2 0 2 0 1 0 2 2 0 0 0 0 0 1 0 1 1
2 2 0 2 1 0 1 2 0 0 1 0 0 1 1 0 1 1 0 2 0 1 2 1 2 1 1 0 2 1 1 1 0 2 2 1 2
0 1 0 2 0 0 1 0 1 0 1 1 0 1 2 0 0 0 0 2 1 0 0 0 0 2]
centroids: [[ 0.27187029 0.77241536]
[ 0.39703852 0.23291867]
[ 0.83250094 0.59010582]]
inertia: 6.54249440001
'''
for i in range(len(data)):
if int(lable_pred[i]) == 0:
plt.scatter(data[i][0], data[i][1], color='red')
if int(lable_pred[i]) == 1:
plt.scatter(data[i][0], data[i][1], color='black')
if int(lable_pred[i]) == 2:
plt.scatter(data[i][0], data[i][1], color='blue')
plt.show()
# 保存机器学习算法模型
joblib.dump(value=estimator, filename="./km_model.m")
load = joblib.load("./km_model.m")
print(load)
'''
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
'''
·
1、(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2、寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3、重新计算新生成的这个类与各个旧类之间的相似度;
4、重复2和3直到所有样本点都归为一类,结束
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。这里介绍一下三种:
SingleLinkage:又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
CompleteLinkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
Average-linkage:这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。
# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
from numpy import *
"""
Code for hierarchical clustering, modified from
Programming Collective Intelligence by Toby Segaran
(O'Reilly Media 2007, page 33).
"""
class cluster_node:
def __init__(self,vec,left=None,right=None,distance=0.0,id=None,count=1):
self.left=left
self.right=right
self.vec=vec # vector向量 代表一个实例
self.id=id
self.distance=distance
self.count=count #only used for weighted average
def L2dist(v1,v2):
return sqrt(sum((v1-v2)**2))
def L1dist(v1,v2):
return sum(abs(v1-v2))
# def Chi2dist(v1,v2):
# return sqrt(sum((v1-v2)**2))
def hcluster(features,distance=L2dist):
#cluster the rows of the "features" matrix
distances={}
currentclustid=-1
# clusters are initially just the individual rows 每个实例作为一个聚类
clust=[cluster_node(array(features[i]),id=i) for i in range(len(features))]
while len(clust)>1:
lowestpair=(0,1) # 最近的一对
closest=distance(clust[0].vec,clust[1].vec) # 最近的距离
# loop through every pair looking for the smallest distance
# 循环每一对 找出最小距离的
for i in range(len(clust)):
for j in range(i+1,len(clust)):
# distances is the cache of distance calculations
# distances是距离计算结果的存储集合
if (clust[i].id,clust[j].id) not in distances:
distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
d=distances[(clust[i].id,clust[j].id)]
if d<closest:
closest=d
lowestpair=(i,j)
# calculate the average of the two clusters
# 合并vec 计算最近的这一对的每个vec值平均值
mergevec=[(clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0 \
for i in range(len(clust[0].vec))]
# create the new cluster 以这个合并的向量 创建新的节点
newcluster=cluster_node(array(mergevec),left=clust[lowestpair[0]],
right=clust[lowestpair[1]],
distance=closest,id=currentclustid)
# cluster ids that weren't in the original set are negative
currentclustid-=1
del clust[lowestpair[1]]
del clust[lowestpair[0]]
clust.append(newcluster)
return clust[0]
# 递归的取出树形结构结果
def extract_clusters(clust,dist):
# extract list of sub-tree clusters from hcluster tree with distance<dist
clusters = {}
if clust.distance<dist:
# we have found a cluster subtree
return [clust]
else:
# check the right and left branches
cl = []
cr = []
if clust.left!=None:
cl = extract_clusters(clust.left,dist=dist)
if clust.right!=None:
cr = extract_clusters(clust.right,dist=dist)
return cl+cr
# 迭代 取出聚类中的元素id
def get_cluster_elements(clust):
# return ids for elements in a cluster sub-tree
if clust.id>=0:
# positive id means that this is a leaf
return [clust.id]
else:
# check the right and left branches
cl = []
cr = []
if clust.left!=None:
cl = get_cluster_elements(clust.left)
if clust.right!=None:
cr = get_cluster_elements(clust.right)
return cl+cr
# 打印出
def printclust(clust,labels=None,n=0):
# indent to make a hierarchy layout 用n控制缩进层级
for i in range(n): print ' ',
if clust.id<0:
# negative id means that this is branch
print '-'
else:
# positive id means that this is an endpoint
if labels==None: print clust.id
else: print labels[clust.id]
# now print the right and left branches
if clust.left!=None: printclust(clust.left,labels=labels,n=n+1)
if clust.right!=None: printclust(clust.right,labels=labels,n=n+1)
# 得到树的高度 多少个末端
def getheight(clust):
# Is this an endpoint? Then the height is just 1
if clust.left==None and clust.right==None: return 1
# Otherwise the height is the same of the heights of
# each branch
return getheight(clust.left)+getheight(clust.right)
# 得到树的深度
def getdepth(clust):
# The distance of an endpoint is 0.0
if clust.left==None and clust.right==None: return 0
# The distance of a branch is the greater of its two sides
# plus its own distance
return max(getdepth(clust.left),getdepth(clust.right))+clust.distance
聚类(Clustering) 顾名思义,就是将相似样本聚合在一起,属于机器学习中的非监督学习 (unsupervised learning) 问题。聚类的目标是找到相近的数据点,并将相近的数据点聚合在一起。
实现聚类的算法主要有:
1.K-均值聚类算法
2.层次聚类
K-均值聚类算法(K-means Clustering)
K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低。优点:
原理简单
速度快
对大数据集有比较好的伸缩性
缺点:
需要指定聚类 数量K
对异常值敏感
对初始值敏感
算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类,以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
算法思想:
以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果
算法描述:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
算法流程:
输入:k, data
;
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data
, 分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
·# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
import numpy as np
# Function: K Means
# -------------
# K-Means is an algorithm that takes in a dataset and a constant
# k and returns k centroids (which define clusters of data in the
# dataset which are similar to one another).
# 定义kmeans方法 (数据集,划分为k类,停止的条件)
def kmeans(X, k, maxIt):
numPoints, numDim = X.shape # 获取多少行(实例数) 多少列(维度)
dataSet = np.zeros((numPoints, numDim + 1))
dataSet[:, :-1] = X
# Initialize centroids randomly 随机的初始化中心点
centroids = dataSet[np.random.randint(numPoints, size = k), :]
# centroids = dataSet[0:2, :]
#Randomly assign labels to initial centorid 分配标签
centroids[:, -1] = range(1, k +1)
# Initialize book keeping vars.
iterations = 0
oldCentroids = None
# Run the main k-means algorithm
while not shouldStop(oldCentroids, centroids, iterations, maxIt):
print "iteration: \n", iterations # 迭代次数
print "dataSet: \n", dataSet
print "centroids: \n", centroids
# Save old centroids for convergence test. Book keeping.
oldCentroids = np.copy(centroids)
iterations += 1
# Assign labels to each datapoint based on centroids 更新归类
updateLabels(dataSet, centroids)
# Assign centroids based on datapoint labels 更新中心点
centroids = getCentroids(dataSet, k)
# We can get the labels too by calling getLabels(dataSet, centroids)
return dataSet
# Function: Should Stop
# -------------
# Returns True or False if k-means is done. K-means terminates either
# because it has run a maximum number of iterations OR the centroids
# stop changing.
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids, centroids)
# Function: Get Labels
# -------------
# Update a label for each piece of data in the dataset.
def updateLabels(dataSet, centroids):
# For each element in the dataset, chose the closest centroid.
# Make that centroid the element's label.
numPoints, numDim = dataSet.shape
for i in range(0, numPoints):
dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i, :-1], centroids)
# (数据集中的一行,中心点)
def getLabelFromClosestCentroid(dataSetRow, centroids):
label = centroids[0, -1];
minDist = np.linalg.norm(dataSetRow - centroids[0, :-1])
for i in range(1 , centroids.shape[0]):
dist = np.linalg.norm(dataSetRow - centroids[i, :-1])
if dist < minDist:
minDist = dist
label = centroids[i, -1]
print "minDist:", minDist
return label
# Function: Get Centroids
# -------------
# Returns k random centroids, each of dimension n.
def getCentroids(dataSet, k):
# Each centroid is the geometric mean of the points that
# have that centroid's label. Important: If a centroid is empty (no points have
# that centroid's label) you should randomly re-initialize it.
result = np.zeros((k, dataSet.shape[1]))
for i in range(1, k + 1):
oneCluster = dataSet[dataSet[:, -1] == i, :-1]
result[i - 1, :-1] = np.mean(oneCluster, axis = 0)
result[i - 1, -1] = i
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1, x2, x3, x4)) # 组成矩阵
result = kmeans(testX, 2, 10)
print "final result:"
print result
·
Python中sklearn.cluster.KMeans
·# -*- coding: utf-8 -*-"""
@author: tz_zs
k-means
"""
sklearn.cluster.KMeans(
n_clusters=8,
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances='auto',
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm='auto'
)
'''
n_clusters: 簇的个数,即你想聚成几类
init: 初始簇中心的获取方法
n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。
max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
tol: 容忍度,即kmeans运行准则收敛的条件
precompute_distances: 是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内
存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实
现的方法是利用Cpython 来实现的
verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
random_state: 随机生成簇中心的状态条件。
copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都
会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内
存机制才会比较清楚。
n_jobs: 并行设置
algorithm: kmeans的实现算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
'''·
sklearn.cluster.KMeans的使用1
# -*- coding: utf-8 -*-
"""
@author: tz_zs
sklearn.cluster.KMeans的使用1
"""
from sklearn.cluster import KMeans
import numpy as np
# 生成10*3的矩阵
data = np.random.rand(10, 3)
print(data)
# 聚类为4
estimator = KMeans(n_clusters=4) # 返回KMeans对象
# fit_predict表示拟合+预测,也可以分开写
res = estimator.fit_predict(data) # 返回预测类别标签结果
'''
fit = estimator.fit(data) # 返回此KMeans对象,fit==estimator
res2 = estimator.predict(data) # 返回预测类别标签结果
print("product:", res2)
# res3 = estimator.fit(data).predict(data) # 返回预测类别标签结果
'''
# 预测类别标签结果
lable_pred = estimator
df26
.labels_
# 各个类别的聚类中心值
centroids = estimator.cluster_centers_
# 聚类中心均值向量的总和
inertia = estimator.inertia_
print("lable_pred:", lable_pred)
print("centroids:", centroids)
print("inertia:", inertia)
'''
结果:
[[ 0.84806828 0.12835109 0.49866577]
[ 0.05612908 0.60932968 0.18321125]
[ 0.06626165 0.88874957 0.99578568]
[ 0.44475794 0.0689524 0.5608716 ]
[ 0.70856172 0.35226933 0.12178557]
[ 0.04791486 0.66868388 0.01066914]
[ 0.72677149 0.46552559 0.61079303]
[ 0.82953259 0.88425252 0.52384649]
[ 0.87558294 0.3417068 0.20297633]
[ 0.86283938 0.51308292 0.85950813]]
lable_pred: [1 0 2 1 1 0 3 3 1 3]
centroids: [[ 0.05202197 0.63900678 0.0969402 ]
[ 0.71924272 0.22281991 0.34607482]
[ 0.06626165 0.88874957 0.99578568]
[ 0.80638115 0.62095368 0.66471589]]
inertia: 0.512747537743
'''
·
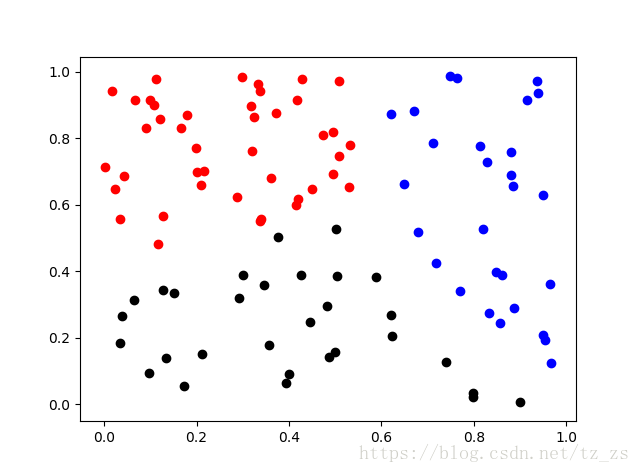
sklearn.cluster.KMeans的使用2# -*- coding: utf-8 -*-
"""
@author: tz_zs
sklearn.cluster.KMeans的使用2
"""
from sklearn.cluster import KMeans
from sklearn.externals import joblib
import numpy as np
import matplotlib.pyplot as plt
data = np.random.rand(100, 2)
estimator = KMeans(n_clusters=3)
res = estimator.fit_predict(data)
lable_pred = estimator.labels_
centroids = estimator.cluster_centers_
inertia = estimator.inertia_
print("lable_pred:", lable_pred)
print("centroids:", centroids)
print("inertia:", inertia)
'''
lable_pred: [2 0 2 0 1 0 2 2 1 2 0 1 2 2 0 0 0 2 2 1 2 0 2 0 1 0 2 2 0 0 0 0 0 1 0 1 1
2 2 0 2 1 0 1 2 0 0 1 0 0 1 1 0 1 1 0 2 0 1 2 1 2 1 1 0 2 1 1 1 0 2 2 1 2
0 1 0 2 0 0 1 0 1 0 1 1 0 1 2 0 0 0 0 2 1 0 0 0 0 2]
centroids: [[ 0.27187029 0.77241536]
[ 0.39703852 0.23291867]
[ 0.83250094 0.59010582]]
inertia: 6.54249440001
'''
for i in range(len(data)):
if int(lable_pred[i]) == 0:
plt.scatter(data[i][0], data[i][1], color='red')
if int(lable_pred[i]) == 1:
plt.scatter(data[i][0], data[i][1], color='black')
if int(lable_pred[i]) == 2:
plt.scatter(data[i][0], data[i][1], color='blue')
plt.show()
# 保存机器学习算法模型
joblib.dump(value=estimator, filename="./km_model.m")
load = joblib.load("./km_model.m")
print(load)
'''
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
'''
·
层次聚类(Hierarchical Clustering)
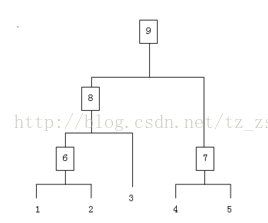
假设有N个待聚类的样本,对于层次聚类来说,步骤:1、(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2、寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3、重新计算新生成的这个类与各个旧类之间的相似度;
4、重复2和3直到所有样本点都归为一类,结束
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。这里介绍一下三种:
SingleLinkage:又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
CompleteLinkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
Average-linkage:这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。
# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
from numpy import *
"""
Code for hierarchical clustering, modified from
Programming Collective Intelligence by Toby Segaran
(O'Reilly Media 2007, page 33).
"""
class cluster_node:
def __init__(self,vec,left=None,right=None,distance=0.0,id=None,count=1):
self.left=left
self.right=right
self.vec=vec # vector向量 代表一个实例
self.id=id
self.distance=distance
self.count=count #only used for weighted average
def L2dist(v1,v2):
return sqrt(sum((v1-v2)**2))
def L1dist(v1,v2):
return sum(abs(v1-v2))
# def Chi2dist(v1,v2):
# return sqrt(sum((v1-v2)**2))
def hcluster(features,distance=L2dist):
#cluster the rows of the "features" matrix
distances={}
currentclustid=-1
# clusters are initially just the individual rows 每个实例作为一个聚类
clust=[cluster_node(array(features[i]),id=i) for i in range(len(features))]
while len(clust)>1:
lowestpair=(0,1) # 最近的一对
closest=distance(clust[0].vec,clust[1].vec) # 最近的距离
# loop through every pair looking for the smallest distance
# 循环每一对 找出最小距离的
for i in range(len(clust)):
for j in range(i+1,len(clust)):
# distances is the cache of distance calculations
# distances是距离计算结果的存储集合
if (clust[i].id,clust[j].id) not in distances:
distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
d=distances[(clust[i].id,clust[j].id)]
if d<closest:
closest=d
lowestpair=(i,j)
# calculate the average of the two clusters
# 合并vec 计算最近的这一对的每个vec值平均值
mergevec=[(clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0 \
for i in range(len(clust[0].vec))]
# create the new cluster 以这个合并的向量 创建新的节点
newcluster=cluster_node(array(mergevec),left=clust[lowestpair[0]],
right=clust[lowestpair[1]],
distance=closest,id=currentclustid)
# cluster ids that weren't in the original set are negative
currentclustid-=1
del clust[lowestpair[1]]
del clust[lowestpair[0]]
clust.append(newcluster)
return clust[0]
# 递归的取出树形结构结果
def extract_clusters(clust,dist):
# extract list of sub-tree clusters from hcluster tree with distance<dist
clusters = {}
if clust.distance<dist:
# we have found a cluster subtree
return [clust]
else:
# check the right and left branches
cl = []
cr = []
if clust.left!=None:
cl = extract_clusters(clust.left,dist=dist)
if clust.right!=None:
cr = extract_clusters(clust.right,dist=dist)
return cl+cr
# 迭代 取出聚类中的元素id
def get_cluster_elements(clust):
# return ids for elements in a cluster sub-tree
if clust.id>=0:
# positive id means that this is a leaf
return [clust.id]
else:
# check the right and left branches
cl = []
cr = []
if clust.left!=None:
cl = get_cluster_elements(clust.left)
if clust.right!=None:
cr = get_cluster_elements(clust.right)
return cl+cr
# 打印出
def printclust(clust,labels=None,n=0):
# indent to make a hierarchy layout 用n控制缩进层级
for i in range(n): print ' ',
if clust.id<0:
# negative id means that this is branch
print '-'
else:
# positive id means that this is an endpoint
if labels==None: print clust.id
else: print labels[clust.id]
# now print the right and left branches
if clust.left!=None: printclust(clust.left,labels=labels,n=n+1)
if clust.right!=None: printclust(clust.right,labels=labels,n=n+1)
# 得到树的高度 多少个末端
def getheight(clust):
# Is this an endpoint? Then the height is just 1
if clust.left==None and clust.right==None: return 1
# Otherwise the height is the same of the heights of
# each branch
return getheight(clust.left)+getheight(clust.right)
# 得到树的深度
def getdepth(clust):
# The distance of an endpoint is 0.0
if clust.left==None and clust.right==None: return 0
# The distance of a branch is the greater of its two sides
# plus its own distance
return max(getdepth(clust.left),getdepth(clust.right))+clust.distance

相关文章推荐
- 机器学习教程之10-聚类(Clustering)-K均值聚类(K-means)的sklearn实现
- 斯坦福大学机器学习笔记——聚类(k-均值聚类算法、损失函数、初始化、聚类数目的选择)
- 机器学习总结(十):常用聚类算法(Kmeans、密度聚类、层次聚类)及常见问题
- 机器学习经典算法详解及Python实现--聚类及K均值、二分K-均值聚类算法
- 机器学习经典算法详解及Python实现--聚类及K均值、二分K-均值聚类算法
- 机器学习之利用K-均值聚类算法对未标注数据分组模型探讨
- 机器学习-K均值聚类(python3代码实现)
- 【数据挖掘算法】聚类方法——K-均值聚类算法
- 机器学习:k均值聚类
- python机器学习案例系列教程——层次聚类(文档聚类)
- 机器学习——非监督学习——层次聚类(Hierarchical clustering)
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
- 机器学习之&&Andrew Ng课程复习--- 聚类——Clustering
- 机器学习作业9 - 自动确定k值的k均值聚类
- 神经网络与机器学习笔记——K-均值聚类
- 机器学习笔记(九)聚类算法及实践(K-Means,DBSCAN,DPEAK,Spectral_Clustering)
- 机器学习笔记(七)聚类算法(k均值,降维)
- 聚类算法实践(一)——层次聚类、K-means聚类
- 机器学习--第十二讲--K均值聚类
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类