K-means原理及Matlab实现
2017-06-26 12:50
197 查看
前言
作为励志在机器学习界闯出一片天地的小女子,在此整理学习到的机器学习方法,并使用Matlab及Python实现。希望可以和大家互相交流和探讨。联系方式:shitianqi1994@163.com
K-means原理
k-means应该是入门机器学习最早接触的算法之一了,它使用简单富有美感的算法深刻地表达了教机器学习的思想,其中蕴含的EM思想会在后续的博文中详细讲解。从它的名字上解析一下,k代表了你要将数据分为几类(也就是后文提到的seed个数,别急,后面你会深刻理解),而means即为平均值,这也是此算法的核心。
宏观上来看它属于无监督学习,(无监督学习指:数据仅给出了特征值,未给出数据的标签,监督学习则同时给出了特征值和标签)
它具体的思想是什么呢,容我细细道来。
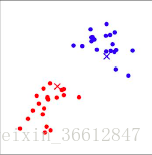
假设我们要将以下情况的点分开:
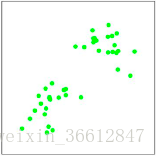
在这个例子中,我们用肉眼可以观察到这个数据大致可以分成两类。而需要注意的是在实际情况的应用上,可以直接观察到类别个数基本是不可能的,主要原因有以下两点:
实际数据特征向量的维数很高,实现可视化是十分困难的。
实际数据通常耦合程度高,没有清晰的分界线。
所以在这里需要提到一个题外话,在现实生活中往往是根据实际需要确定分类类别。举个栗子:你是一家制衣厂的老板,你有一大堆用户身高体重肩宽腰围等等的数据,你希望可以对用户群体分个类,来确定s,m,l码的衣服分别应该适合多大身材维度的用户。这里就可以使用kmeans。在这里,你就按照实际情况直接将k设置成了3。
好了,聊了一些闲话,现在重回主题,我们希望将上图数据进行分类,并且确定了k=2,即分成两类。接下来,我们在所有数据点中随机选取两个种子(seed),播种下这两颗种子,一切交给机器来学习吧!
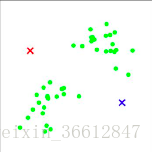
所有点将会和两个seed进行比较,和哪个更加相似就加入哪个seed的阵营。
这里需要引入一个相似的概念,在数学上,表征相似程度的参数有许多:距离,相关系数等等。本文代码采用简单的欧式距离,有心的小伙伴可以尝试不同的方法进行尝试。
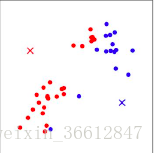
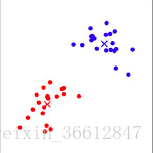
上图中所有的点都已经确定了自己的红蓝阵营。此时重新计算seed值,即所有红色点的特征值求平均作为新的红seed,所有蓝色点的特征值求平均作为新的蓝seed。
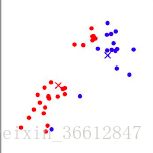
不断重复以上的过程,即可完成最终分类。
Matlab实现
这是一个实现kmeans的函数:function [seed_new all_data] = kmeans_f(data,k) % % 输入data是所有原始数据构成的数组,k是选定的分类个数 % % 输出seed_new是最终seed,all_data是最终data的特征和label 值(第一列为label) [m,n]=size(data); length=m; feature_number=n; r=zeros(k); % % 根据k初始化seed的index r=randperm(length,k); % %保存所有的seed seed_new=zeros(k,feature_number); for j=1:k seed_new(j,:)=data(r(j),:); end all_data=zeros(length,feature_number+1); % % % while 1是相当于do while循环 while 1 seed_old=seed_new; for j=1:length choosen_point=data(j,:); dist_list=zeros(k,1); for i=1:k seed=seed_old(i,:); dist=norm(choosen_point-seed); dist_list(i,:)=dist; end % % 返回最小距离的cluster index cluster_index=find(dist_list==min(dist_list)); % % 有时返回好几个值 cluster_index_point=cluster_index(1); % % 将j点写入第cluster-index的类中,all_data是feature_number+1维数组,其中增加了第一列为其属于cluster的编号。 all_data(j,1)=cluster_index_point; all_data(j,2:end)=choosen_point; end % % 计算得到新的seed矩阵,注意一定要按照cluster-index的顺序排列 seed_new_sum=zeros(k,feature_number); seed_number=zeros(k,1); for i=1:length for j=1:k if all_data(i,1)==j seed_new_sum(j,:)=seed_new_sum(j,:)+all_data(i,2:end); % % 统计每个cluster中点的个数 seed_number(j,:)=seed_number(j,:)+1; end end end % % 计算出新的seed seed_new=zeros(k,feature_number); for i=1:feature_number seed_new(:,i)=seed_new_sum(:,i)./seed_number; end % % 跳出循环的条件是seed的改变量非常小。 judge=norm(seed_new-seed_old) if judge<=0.01 break; end end end
对这个函数进行测试:
clear all; close all; clc; %第一类数据 mu1=[0 0 0]; %均值 S1=[0.3 0 0;0 0.35 0;0 0 0.3]; %协方差 data1=mvnrnd(mu1,S1,100); %产生高斯分布数据 % %第二类数据 mu2=[1.25 1.25 1.25]; S2=[0.3 0 0;0 0.35 0;0 0 0.3]; data2=mvnrnd(mu2,S2,100); % %第三个类数据 mu3=[-1.25 1.25 -1.25]; S3=[0.3 0 0;0 0.35 0;0 0 0.3]; data3=mvnrnd(mu3,S3,100); % %显示数据 plot3(data1(:,1),data1(:,2),data1(:,3),'+'); hold on; plot3(data2(:,1),data2(:,2),data2(:,3),'+'); plot3(data3(:,1),data3(:,2),data3(:,3),'+'); grid on;
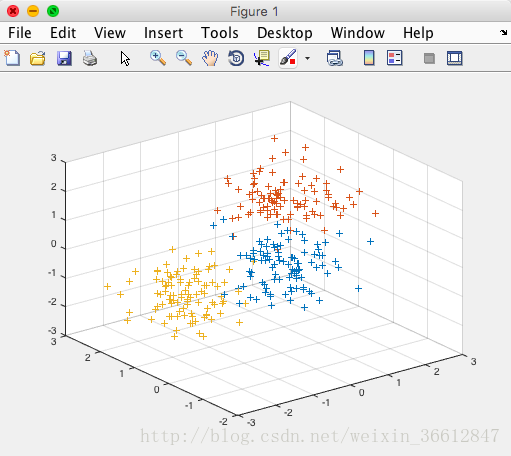
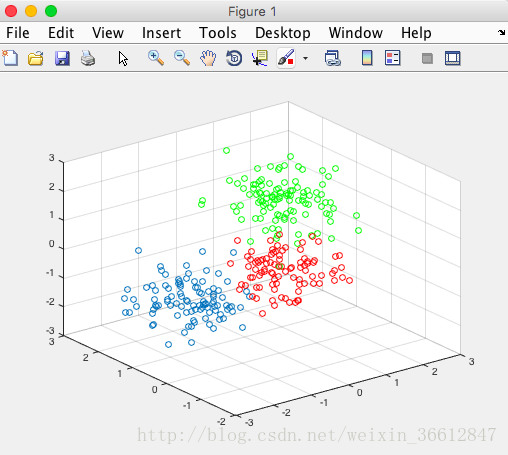
测试得到的结果如下:
原始数据:
分类后的数据:
结语
感谢大家看到这里,欢迎随时沟通交流~
相关文章推荐
- 相机标定的原理与意义及OpenCV、Matlab实现差异小结
- Hough变换 直线检测原理及其Matlab实现
- 区域生长算法原理及MATLAB实现
- m序列生成器的原理与MATLAB及FPGA实现
- C++实现K-means,聚类原理解析(并用在图片像素点聚类)
- 用MATLAB的GUI实现文本的简单加密原理
- 吉布斯采样——原理及matlab实现
- PCA的原理及MATLAB实现
- matlab中二维插值中cubic方法的实现原理(个人见解)
- Non Local Means-块匹配MATLAB和GPU实现
- 傅立叶变换的原理、意义以及如何用Matlab实现快速傅立叶变换
- softmax原理及Matlab实现
- 图像Ostu二值化原理及matlab实现代码
- 霍夫变换检测直线--原理和Matlab实现
- K-means原理与代码实现
- K-Means 和K-Medoids算法及其MATLAB实现
- K-Means 聚类算法原理分析与代码实现
- BP神经网络原理及其matlab实现
- 视频教程:卡尔曼滤波器的原理以及在MATLAB中的实现
- 主成分分析法原理与MATLAB实现