《Robust Face Recognition via Sparse Representation》
2017-06-07 18:32
267 查看
摘要:《基于稀疏表示的鲁棒人脸识别》,这是用稀疏表示用于人脸识别中比较经典的文章了。传统的人脸识别系统总是受光照、遮挡和伪装等影响较大,这篇文章提出了一种基于图像的分类算法,它是通过对图像进行稀疏表示并使得1-范数最小化来对测试人脸进行正确分类。我们都知道人脸识别系统的两个关键点是特征提取和对遮挡的鲁棒性,本文阐述的算法对这两点提供了新的视角。
论文的章节目录如下:
4.1 特征提取和分类方法
4.2 局部面部特征
4.3 像素被随机破坏情况下的识别
4.4 区块被随机遮挡情况下的识别
4.5 伪装情况下的识别
4.6 通过块分区来提高识别率
4.7 拒绝无效的测试样例
下面这样图是对论文中算法的概述:

最左边列上面的图像是被遮挡(太阳镜)的图像,下面是被破坏的图像。这两幅图像可以表示成训练样例(中间)的稀疏
线性组合再加上噪声项(右边)。红色框中的人脸图像是训练集中与测试样例同一类的人脸。
这里说几个常用的人脸测试库,这些数据库的下载链接为点击打开链接:
ORL : 40个人,每人10张照片。不同时间、不同光照、不同表情、不同细节。所有的图像都在一个黑暗均匀的背景下采集的正 面竖直人脸(有些有轻微转动)。
Yale A :
对于初始实验更好的数据库,因为识别问题更复杂,15个人(14个男人,1个女人),每个人有11个灰度图像
大小是 320*243pixels,有光照变化(中心,左侧,右侧),表情变化(开心、正常、悲伤、瞌睡、惊讶、眨眼)
眼镜(戴或不带)。
extended Yale B : 38个人的2414张图片,并且是裁剪好的。这个database重点是测试特征提取是否对光照变化强健,
因为图像的表情、遮挡等都没有变化。此database较大。
前面摘要中说到特征提取和对遮挡的鲁棒性的新视角是这篇论文的主要贡献点。下面具体谈一谈:
特征提取的作用:物体图像的低维特征是最相关、也是对分类提供最大信息量的特征,这一点是人脸识别和物体识别的中心问题。大量的文献致力于数据相关的特征转换,目的是将高维的特征转换为低维的特征:这方面的例子有很多,比如Eigenfaces、 Fisherfaces、Laplacianfaces等等。虽然特征转换(降维)的方法这么多,究竟哪一种算法效果更好或不好,使用者并没有达成共识。然而,在本论文提出的算法框架表明:特征空间的精确选择已经不再重要。哪怕是随机特征,只要包含足够的信息用于稀疏表示,就能将测试样例正确分类。这种算法框架看重的是特征空间的维数足够大而且稀疏表示能被正确的计算。
对遮挡的鲁棒性:遮挡对人脸识别系统在真实世界中的鲁棒性提出了很大的挑战。这种困难主要是因为由遮挡引起的错误的不可预 测的性质。它可能影响图像的任何部分、任意大小。但是,这种错误仅仅破坏图像的一部分像素,因此在由各个像素给出的标准基础中是稀疏的。因为错误项也有稀疏表示,所以也可以在我们的算法框架下统一处理:将错误项当做训练样例中特殊的一类。后面会说到扩展词典(训练样例和错误偏置),Fig.1上面一行就是测试图像被遮挡后如何表示的实例。稀疏表示和压缩感知理论可以完成源
- 错误分离,因此识别算法可以容忍遮挡。
论文第二章节介绍了基础的基于稀疏表示的分类框架,接下来讨论为什么可以通过1-范数最小化求解稀疏解,还有它如何被用于分类并且在给定的一些测试样例中进行验证。第三章讨论了如何用这个分类框架学习两个基于图像的人脸识别中的两个重要问题,也就是上文提到的特征提取的作用和对遮挡的鲁棒性。第四章,验证了算法在各种情况下的适应性。
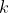
个类的训练样例确定出新的测试样例的所属类别。将来自于第

类的
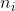
个训练样例分别reshape()成一个列向量,然后将这个训练样例依次作为矩阵

的列向量。

是训练样例灰度图像的大小。先假设来自同一类的训练样例确实在一个子空间上,这也是在我们的方法中关于训练样例的唯一的先验知识。属于同一类的测试样例大约位于由同一类的训练样例张成的线性空间中,也就是:

, (1)
其中

标量。
因为我们事先并不知道测试样例属于第
类,所以我们用所有的属于
个类的总个数为
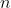
的训练样本的列的级联来定义一个新的矩阵
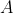
:

, (2)
这时候测试样例可以被重新表示为:

,
(3)
其中

是系数向量,除了属于第
类的项外,其它的所有项都应该为零。
向量的项可以理解为是测试样例所属类别的编码,通过求解方程(3)可以得出结果。注意到,与NN(nearest
neighbor)和NS(nearest subspace)仅仅使用一个或者一类样本不同,SRC使用到了整个训练集中的样本。我们随后会说到它相对于NN或者NS的优势,这种优势体现在两个方面:一是确定测试样例所属的类别,另一个是拒绝并不属于训练集中包含类别的无效的测试样例。此外,我们会看到算法的复杂度是和训练集的大小成线性关系的。
显然,如果

,那么方程(3)就是超定的,对应的就只有唯一解了(特解),而这个解往往不是稀疏的;相反,如果这个字典是过完备的(

),那么上式就是欠定的,对应着无穷多个解,此时就转化成一个求最优解问题,找出这无穷多解里最稀疏的作为上式的解,而这个解对应的就是同类系数非零其他类系数全为零的情况了。初步想法是:通过2-范数最小化求解:

(4)
尽管这个最优化问题可以通过矩阵的伪逆矩阵很容易的求出,但是这个解并没有包含足够的信息量来确定测试样例,下面的例子会讲到

是稠密的,它含有很多和测试样例类别不同类的非零项,这显然是不能令我们满意的。那么如何解决这个问题呢?我们都知道下面的这些结论:一个有效的测试样例能被同一类的训练样例充分的表示,如果训练集中的类别足够大,那么这个表示就自然而然的更稀疏,比如,如果

,那么

中仅仅5%的项不为零。解越稀疏,那么准确的确定测试样例所属的类别就越容易。这使我们更加有动力去找到方程(3)的最稀疏的解,去解决这个最优化问题:

, (5)
表示0-范数,它计算向量中非零项的个数。这种方法虽然可以让人满意,但是计算代价太大。
1-范数最小化求出的最优解和0-范数最小化求出的是一样的:

,
(6)
并且这个可以在多项式时间内被解出。


表示1-范数的球体或者多面体,它的内径为

:

, (7)
在图二中1-范数球体被映射到多面体

,这个多面体包含所有的由1-范数小于1的
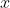
经过

得到的
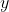
。这两个多面体在几何关系上具有尺度不变性,因为做的是乘法。从几何的角度看求方程(6)的1-范数的最小的解和以下过程是等价的:扩展
(

也会随之扩展),直到多面体
第一次触碰到
,这时的
值就是要求得的

。

, (8)

是噪声项,它有有限的能量

。此时的稀疏解
仍然可以用1-范数最小化问题求解:

, (9)
这个凸优化问题可以通过二阶圆锥体规划求出。

从图中(a)可以看出:除了前面几条比较高的线外,后面跟着很多毛刺。图中有很详细的解释,这里就不过多解释了。从图中可以 看出两个最小残差比是1:8.6,这个区分度是很明显的。基于全局性的稀疏表示,人们能设计出多种可能的分类器,比如说可以将
指定为某一类通过看

中的最大项属于哪一类。但是这种启发式的想法并没有利用到图像子空间的结构特征,为了能利用到这种结构,我们想到了下面这种思路:对于每一个类别,定义一种转换函数,它每次只挑选中第
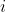
类的系数。这个很好理解,比如说共有3类,每类4个样本,求得的稀疏解为

(实际求得的系数要比这小很多,这里只是为了举例方便),那么分别是

、

、

。然后我们用下面的式子判定类别:

,
(10)
至此,算法的步骤也就很清晰了:

上面说到了用2-范数最小求出的最优解并不是稀疏的,下面这个例子可以说明这一点:

简单的解释一下上面的例子:在Extended Yale B数据库中的2414张图片中随机的选择一半作为训练样例,其余的作为测试样例。在这个例子中我们将原始的192×168大小的图片下采样成12×10。那么每张图片就是一个120维的特征,通过列堆叠作为

的列,因此矩阵
就是120×1207大小,多元方程组

就是欠定的。Fig.3a说明了属于第一类的测试样例经过Algorithm1解出的稀疏解的情况,最优解的系数中两个最大的系数也是指向第一类的。Fig.3b显示了每个类别得到的残差。用12×10的下采样图片作为特征,Algorithm1获得了0.921的识别率。Fig.4a显示了相同的测试样例用2-范数最小求出的最优解的系数,Fig.4b显示了对应的38个类别的残差,我们看到第一类的残差并不是最小的,并且残差比是区分性很低的1:1.3,不能根据最优解的系数判断出测试样例所属的类别。
在传统的分类系统中比如NN和NS,残差

不仅用来分类,还用来验证测试样例是否有效。也就是说,算法接受或拒绝一个测试样例基于最小的残差是多少。那么在我们今天讲的算法中为什么不用这种方法了呢?这是因为每一个残差
都仅仅是通过每一类的系数得到的,并不涉及其他类的系数,也就是说它仅仅测量测试样例和每一个类别的相似性。在稀疏表示范例中,系数

是由所有的类别全局性的计算得到的。某种意义上来说,它可以利用全局性的知识进行验证,所以我们认为在验证方面系数

比残差更具统计性。下面我们通过一个例子看一下:

我们从谷歌上随机选择了一张不相关的图片并将它下采样成12×10。训练样例还是用的Extended Yale B数据。Fig.5a画出了求出的系数,Fig.5b画出了相应的残差。与Fig.3显示的有效图片的系数相比较,这里的系数
并没有集中在某一类,而是扩散到整个训练集。因此,对稀疏系数
分布的估计包含重要的的信息去验证测试样例的有效性:一个有效的测试样例应该有稀疏的表示,它的非零项应该尽可能的集中在某一类,然而无效的测试样例的稀疏表示扩散到很多类别中。
为了量化这个结论,我们定义如下的测量公式来判断系数在某一类的集中性:

接着上面的图片(粘图比打公式方便多了

)

。
(15)
在Algorithm1的step5我们修改如下:只有当测试样例通过公式(15)的验证后,才去判断它属于哪一个类别。
至此算法的主体部分就已经说完了,剩下的以后再更。
论文的章节目录如下:
1 介绍
2 基于稀疏表示的分类
2.1 测试样本作为训练样本的稀疏线性组合
2.2 1-范数最小化求得稀疏解
2.2.1 几何解释
2.2.2 处理小的密集的噪声
2.3 基于稀疏表示的分类
2.4 基于稀疏表示的实验验证
3 人脸识别中的两个基本问题
3.1 特征提取的作用
3.2 对遮挡和破坏的鲁棒性
4 实验验证
4.1 特征提取和分类方法
4.2 局部面部特征
4.3 像素被随机破坏情况下的识别
4.4 区块被随机遮挡情况下的识别
4.5 伪装情况下的识别
4.6 通过块分区来提高识别率
4.7 拒绝无效的测试样例
4.8 设计鲁棒性训练集
5 总结与讨论
1 介绍
SRC(Sparse Representationfor classification)是一种分类的方法。是利用字典得到一系列的稀疏稀疏,然后利用系数的性质得到测试样例的所属类别。对于测试人脸图像,我们用数据库中所有图像的线性组合表示,除同一个人的人脸图像稀疏外,数据库中其它人的人脸图像线性组合的系数理论上为零,所以其系数是稀疏的。下面这样图是对论文中算法的概述:
最左边列上面的图像是被遮挡(太阳镜)的图像,下面是被破坏的图像。这两幅图像可以表示成训练样例(中间)的稀疏
线性组合再加上噪声项(右边)。红色框中的人脸图像是训练集中与测试样例同一类的人脸。
这里说几个常用的人脸测试库,这些数据库的下载链接为点击打开链接:
ORL : 40个人,每人10张照片。不同时间、不同光照、不同表情、不同细节。所有的图像都在一个黑暗均匀的背景下采集的正 面竖直人脸(有些有轻微转动)。
Yale A :
对于初始实验更好的数据库,因为识别问题更复杂,15个人(14个男人,1个女人),每个人有11个灰度图像
大小是 320*243pixels,有光照变化(中心,左侧,右侧),表情变化(开心、正常、悲伤、瞌睡、惊讶、眨眼)
眼镜(戴或不带)。
extended Yale B : 38个人的2414张图片,并且是裁剪好的。这个database重点是测试特征提取是否对光照变化强健,
因为图像的表情、遮挡等都没有变化。此database较大。
前面摘要中说到特征提取和对遮挡的鲁棒性的新视角是这篇论文的主要贡献点。下面具体谈一谈:
特征提取的作用:物体图像的低维特征是最相关、也是对分类提供最大信息量的特征,这一点是人脸识别和物体识别的中心问题。大量的文献致力于数据相关的特征转换,目的是将高维的特征转换为低维的特征:这方面的例子有很多,比如Eigenfaces、 Fisherfaces、Laplacianfaces等等。虽然特征转换(降维)的方法这么多,究竟哪一种算法效果更好或不好,使用者并没有达成共识。然而,在本论文提出的算法框架表明:特征空间的精确选择已经不再重要。哪怕是随机特征,只要包含足够的信息用于稀疏表示,就能将测试样例正确分类。这种算法框架看重的是特征空间的维数足够大而且稀疏表示能被正确的计算。
对遮挡的鲁棒性:遮挡对人脸识别系统在真实世界中的鲁棒性提出了很大的挑战。这种困难主要是因为由遮挡引起的错误的不可预 测的性质。它可能影响图像的任何部分、任意大小。但是,这种错误仅仅破坏图像的一部分像素,因此在由各个像素给出的标准基础中是稀疏的。因为错误项也有稀疏表示,所以也可以在我们的算法框架下统一处理:将错误项当做训练样例中特殊的一类。后面会说到扩展词典(训练样例和错误偏置),Fig.1上面一行就是测试图像被遮挡后如何表示的实例。稀疏表示和压缩感知理论可以完成源
- 错误分离,因此识别算法可以容忍遮挡。
论文第二章节介绍了基础的基于稀疏表示的分类框架,接下来讨论为什么可以通过1-范数最小化求解稀疏解,还有它如何被用于分类并且在给定的一些测试样例中进行验证。第三章讨论了如何用这个分类框架学习两个基于图像的人脸识别中的两个重要问题,也就是上文提到的特征提取的作用和对遮挡的鲁棒性。第四章,验证了算法在各种情况下的适应性。
2 基于稀疏表示的分类
2.1 测试样本作为训练样本的稀疏线性组合
目标识别的中心问题就是:用带标签的个类的训练样例确定出新的测试样例的所属类别。将来自于第
类的
个训练样例分别reshape()成一个列向量,然后将这个训练样例依次作为矩阵
的列向量。
是训练样例灰度图像的大小。先假设来自同一类的训练样例确实在一个子空间上,这也是在我们的方法中关于训练样例的唯一的先验知识。属于同一类的测试样例大约位于由同一类的训练样例张成的线性空间中,也就是:
, (1)
其中
标量。
因为我们事先并不知道测试样例属于第
类,所以我们用所有的属于
个类的总个数为
的训练样本的列的级联来定义一个新的矩阵
:
, (2)
这时候测试样例可以被重新表示为:
,
(3)
其中
是系数向量,除了属于第
类的项外,其它的所有项都应该为零。
向量的项可以理解为是测试样例所属类别的编码,通过求解方程(3)可以得出结果。注意到,与NN(nearest
neighbor)和NS(nearest subspace)仅仅使用一个或者一类样本不同,SRC使用到了整个训练集中的样本。我们随后会说到它相对于NN或者NS的优势,这种优势体现在两个方面:一是确定测试样例所属的类别,另一个是拒绝并不属于训练集中包含类别的无效的测试样例。此外,我们会看到算法的复杂度是和训练集的大小成线性关系的。
显然,如果
,那么方程(3)就是超定的,对应的就只有唯一解了(特解),而这个解往往不是稀疏的;相反,如果这个字典是过完备的(
),那么上式就是欠定的,对应着无穷多个解,此时就转化成一个求最优解问题,找出这无穷多解里最稀疏的作为上式的解,而这个解对应的就是同类系数非零其他类系数全为零的情况了。初步想法是:通过2-范数最小化求解:
(4)
尽管这个最优化问题可以通过矩阵的伪逆矩阵很容易的求出,但是这个解并没有包含足够的信息量来确定测试样例,下面的例子会讲到
是稠密的,它含有很多和测试样例类别不同类的非零项,这显然是不能令我们满意的。那么如何解决这个问题呢?我们都知道下面的这些结论:一个有效的测试样例能被同一类的训练样例充分的表示,如果训练集中的类别足够大,那么这个表示就自然而然的更稀疏,比如,如果
,那么
中仅仅5%的项不为零。解越稀疏,那么准确的确定测试样例所属的类别就越容易。这使我们更加有动力去找到方程(3)的最稀疏的解,去解决这个最优化问题:
, (5)
表示0-范数,它计算向量中非零项的个数。这种方法虽然可以让人满意,但是计算代价太大。
2.2 1-范数最小化求得稀疏解
这两种方法都取得比较满意的结果,那怎么办呢?最近发展起来的稀疏表示和压缩感知的理论显示:如果解释稀疏的,那么1-范数最小化求出的最优解和0-范数最小化求出的是一样的:
,
(6)
并且这个可以在多项式时间内被解出。
2.2.1 几何解释
Fig.2给出了一个几何的解释关于为什么可以通过1-范数最小化求出稀疏解。表示1-范数的球体或者多面体,它的内径为
:
, (7)
在图二中1-范数球体被映射到多面体
,这个多面体包含所有的由1-范数小于1的
经过
得到的
。这两个多面体在几何关系上具有尺度不变性,因为做的是乘法。从几何的角度看求方程(6)的1-范数的最小的解和以下过程是等价的:扩展
(
也会随之扩展),直到多面体
第一次触碰到
,这时的
值就是要求得的
。
2.2.2 处理小的密集的噪声
真实的数据都是含有噪声的,因此测试样例不太可能准确的用训练样例的稀疏叠加来表示。所以为了使模型更加具有通用性,可将(3)重新写成如下形式:, (8)
是噪声项,它有有限的能量
。此时的稀疏解
仍然可以用1-范数最小化问题求解:
, (9)
这个凸优化问题可以通过二阶圆锥体规划求出。
2.3 基于稀疏表示的分类
上文中提到过由于噪声和模型错误(误差)使得可能会导致稀疏解在其他类出现非零项,如下图所示:从图中(a)可以看出:除了前面几条比较高的线外,后面跟着很多毛刺。图中有很详细的解释,这里就不过多解释了。从图中可以 看出两个最小残差比是1:8.6,这个区分度是很明显的。基于全局性的稀疏表示,人们能设计出多种可能的分类器,比如说可以将
指定为某一类通过看
中的最大项属于哪一类。但是这种启发式的想法并没有利用到图像子空间的结构特征,为了能利用到这种结构,我们想到了下面这种思路:对于每一个类别,定义一种转换函数,它每次只挑选中第
类的系数。这个很好理解,比如说共有3类,每类4个样本,求得的稀疏解为
(实际求得的系数要比这小很多,这里只是为了举例方便),那么分别是
、
、
。然后我们用下面的式子判定类别:
,
(10)
至此,算法的步骤也就很清晰了:
上面说到了用2-范数最小求出的最优解并不是稀疏的,下面这个例子可以说明这一点:
简单的解释一下上面的例子:在Extended Yale B数据库中的2414张图片中随机的选择一半作为训练样例,其余的作为测试样例。在这个例子中我们将原始的192×168大小的图片下采样成12×10。那么每张图片就是一个120维的特征,通过列堆叠作为
的列,因此矩阵
就是120×1207大小,多元方程组
就是欠定的。Fig.3a说明了属于第一类的测试样例经过Algorithm1解出的稀疏解的情况,最优解的系数中两个最大的系数也是指向第一类的。Fig.3b显示了每个类别得到的残差。用12×10的下采样图片作为特征,Algorithm1获得了0.921的识别率。Fig.4a显示了相同的测试样例用2-范数最小求出的最优解的系数,Fig.4b显示了对应的38个类别的残差,我们看到第一类的残差并不是最小的,并且残差比是区分性很低的1:1.3,不能根据最优解的系数判断出测试样例所属的类别。
2.4 基于稀疏表示的实验验证
在对给定的测试样例进行分类之前,首先要做的就是判断这张测试样例是否是训练集中某一类。识别出无效的测试样例并拒绝它是人脸识别系统在真实场景中很重要的一个方面。无效的测试样例包含两个方面,一个是不属于训练集中的类别,另一个是本来就不是人脸图像。在传统的分类系统中比如NN和NS,残差
不仅用来分类,还用来验证测试样例是否有效。也就是说,算法接受或拒绝一个测试样例基于最小的残差是多少。那么在我们今天讲的算法中为什么不用这种方法了呢?这是因为每一个残差
都仅仅是通过每一类的系数得到的,并不涉及其他类的系数,也就是说它仅仅测量测试样例和每一个类别的相似性。在稀疏表示范例中,系数
是由所有的类别全局性的计算得到的。某种意义上来说,它可以利用全局性的知识进行验证,所以我们认为在验证方面系数
比残差更具统计性。下面我们通过一个例子看一下:
我们从谷歌上随机选择了一张不相关的图片并将它下采样成12×10。训练样例还是用的Extended Yale B数据。Fig.5a画出了求出的系数,Fig.5b画出了相应的残差。与Fig.3显示的有效图片的系数相比较,这里的系数
并没有集中在某一类,而是扩散到整个训练集。因此,对稀疏系数
分布的估计包含重要的的信息去验证测试样例的有效性:一个有效的测试样例应该有稀疏的表示,它的非零项应该尽可能的集中在某一类,然而无效的测试样例的稀疏表示扩散到很多类别中。
为了量化这个结论,我们定义如下的测量公式来判断系数在某一类的集中性:
接着上面的图片(粘图比打公式方便多了
)
。
(15)
在Algorithm1的step5我们修改如下:只有当测试样例通过公式(15)的验证后,才去判断它属于哪一个类别。
至此算法的主体部分就已经说完了,剩下的以后再更。

相关文章推荐
- 稀疏表示人脸识别入门文章-《Robust Face Recognition via Sparse Representation》马毅
- 稀疏表示《Robust Face Recognition via Sparse Representation》
- Robust Face Recognition via Sparse Representation
- 《Robust Face Recognition via Sparse Representation》
- 《Gabor feature based sparse representation for face recognition with gabor occlusion dictionary》
- Robust Visual Tracking and Vehicle Classification via Sparse Representation 阅读小结
- 《Robust Sparse Coding for Face Recognition》
- High Dimensional Pattern Recognition via Sparse Representation
- EfficientMisalignment-Robust Representation for Real-Time Face Recognition
- 基于稀疏表示的图像超分辨率《Image Super-Resolution Via Sparse Representation》
- A Review of Fast L1-Minimization Algorithms for Robust Face Recognition
- Hyperspectral Image Super-Resolution via Non-Negative Structured Sparse Representation论文阅读笔记(PART)
- 计算机视觉和模式识别中的稀疏表示(Sparse Representation for Computer Vision and Pattern Recognition)
- Group Sparse Coding For Face Recognition
- 人脸识别(五)2018 Face Recognition via Centralized Coordinate Learning
- 《Structured Sparse Error Coding for Face Recognition With Occlusion》
- Vehicle Identification Via Sparse Representation
- 计算机视觉和模式识别中的稀疏表示(Sparse Representation for Computer Vision and Pattern Recognition)
- 《Close the Loop: Joint Blind Image Restoration and Recognition with Sparse Representation Prior》阅读笔记
- 基于稀疏表示的图像超分辨率《Image Super-Resolution Via Sparse Representation》