朴素贝叶斯分类原理及Python实现简单文本分类
2017-05-28 15:21
711 查看
贝叶斯定理:
这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
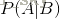
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
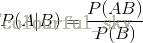
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
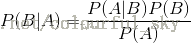
其实分类在我们的日常生活当中每时每刻都在用,当我们看见一个苹果,我们会判断它为一个苹果而不是一个梨异或是一头大象的依据是它的外观,颜色,重量等等这些特征。首先我们知道了它是一个待分类的物体A,然后判断它属于哪一类,苹果B1?梨B2?大象B3?狮子B4?姑且就判断它属于这四类中的哪一类。其中这四类都有的特征是[‘颜色’, ‘体重’],事先我们已经有了很多的已经训练好的样本,也就是P(B)已知。然后通过求P(A|B)P(B)的最大化来求待分类物体属于哪一类。可能表达得不太清楚,但实际就是这么个意思。具体流程参看下面分类流程以及文末的参考博客。

以下以Python语言实现简单文本的朴素贝叶斯分类:
Nbayes.py
Nbayes_lib.py:
最后输出结果为0。
代码来自郑洁著的机器学习算法原理与编程实践这本书。此书用的Python2.7,我用的是Python3.6 。修改了原著中的少部分代码。
朴素贝叶斯分类原理基础参考这篇博客
这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
其实分类在我们的日常生活当中每时每刻都在用,当我们看见一个苹果,我们会判断它为一个苹果而不是一个梨异或是一头大象的依据是它的外观,颜色,重量等等这些特征。首先我们知道了它是一个待分类的物体A,然后判断它属于哪一类,苹果B1?梨B2?大象B3?狮子B4?姑且就判断它属于这四类中的哪一类。其中这四类都有的特征是[‘颜色’, ‘体重’],事先我们已经有了很多的已经训练好的样本,也就是P(B)已知。然后通过求P(A|B)P(B)的最大化来求待分类物体属于哪一类。可能表达得不太清楚,但实际就是这么个意思。具体流程参看下面分类流程以及文末的参考博客。
以下以Python语言实现简单文本的朴素贝叶斯分类:
Nbayes.py
# -*- coding: utf-8 -*- from numpy import * import numpy as np from Nbayes_lib import * dataSet,listClasses = loadDataSet() #导入外部数据集 nb = NBayes() #类的实例化 nb.train_set(dataSet,listClasses) #训练数据集 nb.map2vocab(dataSet[2]) #随机选择一个测试句,这里2表示文本中的第三句话,不是脏话,应输出0。 print (nb.predict(nb.testset)) #输出分类结果
Nbayes_lib.py:
# -*- coding: utf-8 -*-
import numpy as np
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him','my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 表示脏话, 0 则不是
return postingList,classVec
class NBayes(object):
def __init__(self):
self.vocabulary = [] # 词典
self.idf=0 # 词典的idf权值向量
self.tf=0 # 训练集的权值矩阵
self.tdm=0 # P(x|yi)
self.Pcates = {} # P(yi)--是个类别字典
self.labels=[] # 对应每个文本的分类,是个外部导入的列表
self.doclength = 0 # 训练集文本数
self.vocablen = 0 # 词典词长
self.testset = 0 # 测试集
# 加载训练集并生成词典,以及tf, idf值
def train_set(self,trainset,classVec):
self.cate_prob(classVec) # 计算每个分类在数据集中的概率:P(yi)
self.doclength = len(trainset)
tempset = set()
[tempset.add(word) for doc in trainset for word in doc ] # 生成词典
self.vocabulary = list(tempset)
self.vocablen = len(self.vocabulary)
self.calc_wordfreq(trainset)
#self.calc_tfidf(trainset) # 生成tf-idf权值
self.build_tdm() # 按分类累计向量空间的每维值:P(x|yi)
'''
# 生成 tf-idf
def calc_tfidf(self,trainset):
self.idf = np.zeros([1,self.vocablen])
self.tf = np.zeros([self.doclength,self.vocablen])
for indx in range(self.doclength):
for word in trainset[indx]:
self.tf[indx,self.vocabulary.index(word)] +=1
# 消除不同句长导致的偏差
self.tf[indx] = self.tf[indx]/float(len(trainset[indx]))
for signleword in set(trainset[indx]):
self.idf[0,self.vocabulary.index(signleword)] +=1
self.idf = np.log(float(self.doclength)/self.idf)
self.tf = np.multiply(self.tf,self.idf) # 矩阵与向量的点乘
'''
# 生成普通的词频向量
def calc_wordfreq(self,trainset):
self.idf = np.zeros([1,self.vocablen]) # 1*词典数
self.tf = np.zeros([self.doclength,self.vocablen]) # 训练集文件数*词典数
for indx in range(self.doclength): # 遍历所有的文本
for word in trainset[indx]: # 遍历文本中的每个词
self.tf[indx,self.vocabulary.index(word)] +=1 # 找到文本的词在字典中的位置+1
for signleword in set(trainset[indx]):
self.idf[0,self.vocabulary.index(signleword)] +=1
# 计算每个分类在数据集中的概率:P(yi)
def cate_prob(self,classVec):
self.labels = classVec
labeltemps = set(self.labels) # 获取全部分类
for labeltemp in labeltemps:
# 统计列表中重复的值:self.labels.count(labeltemp)
self.Pcates[labeltemp] = float(self.labels.count(labeltemp))/float(len(self.labels))
#按分类累计向量空间的每维值:P(x|yi)
def build_tdm(self):
self.tdm = np.zeros([len(self.Pcates),self.vocablen]) #类别行*词典列
sumlist = np.zeros([len(self.Pcates),1]) # 统计每个分类的总值
for indx in range(self.doclength):
self.tdm[self.labels[indx]] += self.tf[indx] # 将同一类别的词向量空间值加总
sumlist[self.labels[indx]]= np.sum(self.tdm[self.labels[indx]]) # 统计每个分类的总值--是个标量
self.tdm = self.tdm/sumlist # P(x|yi)
# 测试集映射到当前词典
def map2vocab(self,testdata):
self.testset = np.zeros([1,self.vocablen])
for word in testdata:
self.testset[0,self.vocabulary.index(word)] +=1
# 输出分类类别
def predict(self,testset):
if np.shape(testset)[1] != self.vocablen:
print ("输入错误")
exit(0)
predvalue = 0
predclass = ""
for tdm_vect,keyclass in zip(self.tdm,self.Pcates):
# P(x|yi)P(yi)
temp = np.sum(testset*tdm_vect*self.Pcates[keyclass])
if temp > predvalue:
predvalue = temp
predclass = keyclass
return predclass最后输出结果为0。
代码来自郑洁著的机器学习算法原理与编程实践这本书。此书用的Python2.7,我用的是Python3.6 。修改了原著中的少部分代码。
朴素贝叶斯分类原理基础参考这篇博客

相关文章推荐
- 数据挖掘笔记-分类-贝叶斯-原理与简单实现
- 朴素贝叶斯算法文本分类原理
- 朴素贝叶斯原理及Python实现
- 贝叶斯案例3:文本关键词提取、新闻分类(python实现)
- 贝叶斯分类方法学习三 python+jieba+mongodb实现朴素贝叶斯新闻文本自动分类
- 朴素贝叶斯中文文本分类器的研究与实现(2)[88250、zy、Sindy原创]
- 一个简单的程序,统计文本文档中的单词和汉字数,逆序排列(出现频率高的排在最前面)。python实现。
- PYTHON实现简单写文本日志
- python图片文本识别的简单实现
- 数据挖掘笔记-分类-KNN-原理与简单实现
- python基于Tkinter库实现简单文本编辑器实例
- 数据挖掘笔记-分类-Adaboost-原理与简单实现
- 朴素贝叶斯中文文本分类器的研究与实现(1)[88250原创]
- [python] 基于k-means和tfidf的文本聚类代码简单实现
- base64编码原理及简单Python实现
- python基于Tkinter库实现简单文本编辑器实例
- 用MATLAB的GUI实现文本的简单加密原理
- 朴素贝叶斯中文文本分类器的研究与实现(2)[88250、zy、Sindy原创]
- 贝叶斯文本分类 java实现
- 【Python 编程】实现文本分类中的信息增益算法