base64编码原理及简单Python实现
2016-05-31 22:17
701 查看
廖老师的Python3教程中对base64编码的讲解讲得不是很清楚,我经过搜索和询问研究生同学,把一些有用的资料结合起来了,希望对你们有用。
base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,用来将非ASCII字符的数据转换成ASCII字符的一种方法,因为某些系统中只能使用ASCII字符,比如Email,由于历史原因,Email只被允许传送ASCII字符,即一个8位字节的低7位。因此,如果您发送了一封带有非ASCII字符(即字节的最高位是1)的Email通过有“历史问题”的网关时就可能会出现问题。网关可能会把最高位置为0!很明显,问题就这样产生了!基于以上的一些主要原因产生了Base64编码,它要求把每3个8Bit的字节转换为4个6Bit的字节,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。Base64编码可用于在HTTP环境下传递较长的标识信息,编码的数据不会被人用肉眼所直接看到,适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
1. base64的编码都是按字符串长度,以每3个8bit的字符为一组。
2. 然后针对每组,首先获取每个字符的ASCII编码。
3. 然后将ASCII编码转换成8bit的二进制,得到一组3*8=24bit的字节。
4. 然后再将这24bit划分为4个6bit的字节,并在每个6bit的字节前面都填两个高位0,得到4个8bit的字节。
5. 然后将这4个8bit的字节转换成10进制,对照Base64编码表,得到对应编码后的字符。
注:
• 由于要求被编码字符是8bit,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
• 由于2^6=64,而以1个6bit为一个单元,因此一定能在0~63的编码表中找到对应的编码!
举例如下:
(一)字符长度为能被3整除时:比如“Tom”:

(二)字符串长度不能被3整除时,比如“Lucy”:

由于Lucy只有4个字母,所以按3个一组的话,第二组还有两个空位,所以需要用0来补齐。这里就需要注意,因为是需要补齐而出现的0,所以转化成十进制的时候就不能按常规用base64编码表来对应,所以不是a, 可以理解成为一种特殊的“异常”,编码应该对应“=”。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号(最多2个=号,理解?),表示补了多少字节,解码的时候,会自动去掉。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。

由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种”url safe”的base64编码,其实就是把字符+和/分别变成-和_:
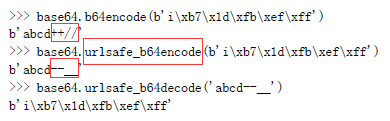
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:

去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。

这是做完我会在评论里面体现。
一、产生原因及作用
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,用来将非ASCII字符的数据转换成ASCII字符的一种方法,因为某些系统中只能使用ASCII字符,比如Email,由于历史原因,Email只被允许传送ASCII字符,即一个8位字节的低7位。因此,如果您发送了一封带有非ASCII字符(即字节的最高位是1)的Email通过有“历史问题”的网关时就可能会出现问题。网关可能会把最高位置为0!很明显,问题就这样产生了!基于以上的一些主要原因产生了Base64编码,它要求把每3个8Bit的字节转换为4个6Bit的字节,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。Base64编码可用于在HTTP环境下传递较长的标识信息,编码的数据不会被人用肉眼所直接看到,适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
二、编码原理
Base64编码表由64个字符组成,编码后的字符由表中字符组合而成,流程如下:1. base64的编码都是按字符串长度,以每3个8bit的字符为一组。
2. 然后针对每组,首先获取每个字符的ASCII编码。
3. 然后将ASCII编码转换成8bit的二进制,得到一组3*8=24bit的字节。
4. 然后再将这24bit划分为4个6bit的字节,并在每个6bit的字节前面都填两个高位0,得到4个8bit的字节。
5. 然后将这4个8bit的字节转换成10进制,对照Base64编码表,得到对应编码后的字符。
注:
• 由于要求被编码字符是8bit,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
• 由于2^6=64,而以1个6bit为一个单元,因此一定能在0~63的编码表中找到对应的编码!
举例如下:
(一)字符长度为能被3整除时:比如“Tom”:
(二)字符串长度不能被3整除时,比如“Lucy”:
由于Lucy只有4个字母,所以按3个一组的话,第二组还有两个空位,所以需要用0来补齐。这里就需要注意,因为是需要补齐而出现的0,所以转化成十进制的时候就不能按常规用base64编码表来对应,所以不是a, 可以理解成为一种特殊的“异常”,编码应该对应“=”。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号(最多2个=号,理解?),表示补了多少字节,解码的时候,会自动去掉。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
三、简单Python实现
Python内置的base64可以直接进行base64的编解码:由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种”url safe”的base64编码,其实就是把字符+和/分别变成-和_:
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
四、练习
请写一个能处理去掉=的base64解码函数:这是做完我会在评论里面体现。

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法