[ElasticSearch2.x]原理之分布式搜索
2017-05-27 15:26
148 查看
这个要比基本的创建-读取-更新-删除(CRUD)请求要难一些。CRUD操作是处理的单个文档。这就意味着我们明确的知道集群中的哪个分片存储我们想要的文档。一个 CRUD 操作只对单个文档进行处理,文档有唯一的组合,由
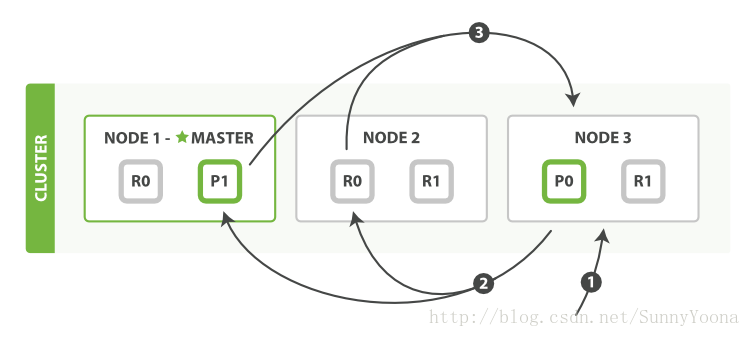
Query阶段包含如下步骤:(1) 客户端发送一个
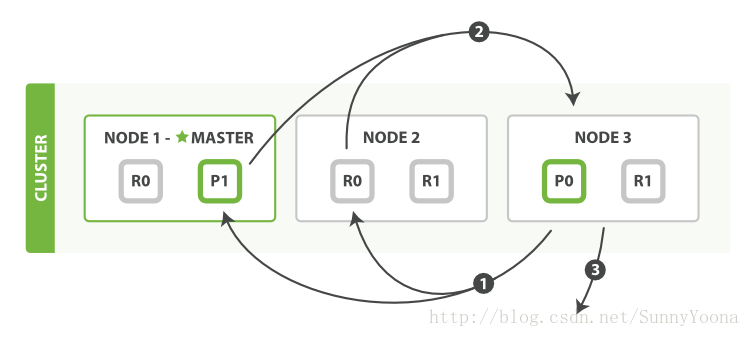
分发阶段由以下步骤构成:(1) 协调节点标示出哪些文档需要取回,并且向相关分片发出GET请求。(2) 如果需要,每个分片加载文档,然后将文档返回协调节点。(3) 一旦所有的文档都被取回,协调节点将结果返回给客户端。协调节点首先决定哪些文档是实际需要取回的。例如,如果我们查询指定
_index,
_type, 和 路由值 (默认是该文档的
_id)组成。 这表示我们确切的知道此文档在集群中哪个分片中。搜索请求是更复杂的执行模型,因为我们不知道哪些文档会与查询匹配,它们可能存在在集群中的任意一个分片中。一个搜索请求不得不搜索我们关注的一个或多个索引中的每个分片拷贝(主分片或者副本分片),以查看分片中中是否有匹配的文档。但找到所有匹配到文档只是完成了一半工作.在
searchAPI返回一“页”结果之前,来自多个分片的结果必须聚合成单个排序的列表。 因此,搜索在两阶段过程中执行,
query和
fetch。
1. Query阶段
在初始化查询阶段(query phase),查询将广播到索引中的每个分片的拷贝上(主分片或者副本分片)。每个分片在本地执行搜索并且建立了匹配文档的优先队列(priority queue)。1.1 优先级队列
优先级队列priority queue只是一个存有前n个(top-n)匹配文档的有序列表。优先级队列的大小取决于
from和
size分页参数。 例如,以下搜索请求将需要足够大的优先级队列来容纳100个文档:
GET /_search
{
"from": 90,
"size": 10
}1.2 Query
Query阶段过程如下图所示:Query阶段包含如下步骤:(1) 客户端发送一个
Search请求给节点 3,节点 3 创建了一个长度为
from+size的空优先级队列。(2) 节点3将搜索请求转发到索引中每个分片的一个主分片或副本分片上( forwards the search request to a primary or replica copy of every shard in the index)。 每个分片在本地执行查询,并将结果添加到大小为
from+
size的本地排序的优先级队列中。(3) 每个分片将其优先级队列中的所有文档的文档ID和排序值返回给协调节点节点3,节点3将这些值合并到其自己的优先级队列中,以生成全局排序的结果列表。当一个搜索请求被发送到一个节点,这个节点就变成了协调节点。这个节点的工作是向所有相关的分片广播搜索请求并且把它们的响应整合成一个全局的有序结果集。将这个结果集返回给客户端。第一步是将请求广播到索引里每个节点的一个主分片或者副本分片上(broadcast the request to a shard copy of every node in the index)。就像document的GET请求一样,搜索请求可以被主分片或者任意副本分片处理。所以说更多的副本能够更高效的提高搜索。协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。每一个分片在本地执行查询和建立一个长度为
from+size的有序优先级队列——这个长度意味着它自己的结果数量就足够满足全局的请求要求。分片返回一个轻量级的结果列表给协调节点。只包含文档ID值和排序需要用到的值,例如_score。协调节点将这些分片结果合并到其自己的排序优先级队列中,表示全局排序的结果集。 到此查询阶段结束。备注索引可以由一个或多个主分片组成,因此针对单个索引的搜索请求需要能够组合来自多个分片的结果。 搜索多个或所有索引的工作方式完全相同 - 只是会涉及更多的分片。
2. Fetch 阶段
查询阶段标示出哪些文档满足我们的搜索请求,我们只返回了文档ID以及对排序有用的值,并没有返回文档本身。们仍然需要检索那些文档。这就是fetch阶段的工作,过程如下图所示:
分发阶段由以下步骤构成:(1) 协调节点标示出哪些文档需要取回,并且向相关分片发出GET请求。(2) 如果需要,每个分片加载文档,然后将文档返回协调节点。(3) 一旦所有的文档都被取回,协调节点将结果返回给客户端。协调节点首先决定哪些文档是实际需要取回的。例如,如果我们查询指定
{ "from": 90, "size": 10 },那么前90条结果将会被丢弃,只需要检索接下来的10个结果。这些文档可能来自与查询请求相关的一个、多个或者全部分片。协调节点给拥有相关文档的每个分片创建一个multi-get request,并发送请求给同样处理查询阶段的分片拷贝。分片加载文档体--
_source字段--如果有需要,用
metadata和
search snippet highlighting丰富结果文档。 一旦协调节点接收到所有的结果文档,它就组合这些结果为单个响应返回给客户端。原文:https://www.elastic.co/guide/en/elasticsearch/guide/current/distributed-search.htmlhttps://www.elastic.co/guide/en/elasticsearch/guide/current/_query_phase.htmlhttps://www.elastic.co/guide/en/elasticsearch/guide/current/_fetch_phase.html

相关文章推荐
- 分布式搜索elasticsearch高级配置之(一)------分片分布规则设置
- 分布式搜索elasticsearch java API 之(七)------与MongoDB同步数据
- [Elasticsearch] 分布式搜索
- 分布式搜索elasticsearch java API 之(五)------搜索
- 分布式搜索elasticsearch java API
- 分布式搜索elasticsearch集群监控工具bigdesk
- 分布式搜索elasticsearch java API 之(七)------与MongoDB同步数据
- 实时的分布式搜索和分析引擎——Elasticsearch 3ff0
- 分布式搜索elasticsearch配置文件详解
- 分布式搜索 Elasticsearch —— 项目
- 分布式搜索elasticsearch高级配置之(二)------线程池设置
- 分布式搜索elasticsearch 基本概念
- 分布式搜索elasticsearch高级配置之(二)------线程池设置
- 分布式搜索elasticsearch高级配置之(二)------线程池设置
- 分布式搜索elasticsearch 环境搭建
- 分布式搜索elasticsearch java API 之(八)------使用More like this实现基于内容的推荐
- 分布式搜索elasticsearch java API 之(二)------put Mapping定义索引字段属性
- 分布式搜索elasticsearch java API 之(二)------put Mapping定
- 分布式搜索elasticsearch配置文件详解
- 分布式搜索elasticsearch java API 之(六)------批量添加删除索引