[人工智能]机器学习实践中数据和模型的选择
2017-05-13 14:42
363 查看
前言
人工智能这一领域还是非常值得去做的,前言技术,今后将越来越多的智能化领域将运用这一技术,互联网领域将进行重新一次洗牌.搞算法的朋友们,大家都知道,最近特别火的机器学习和深度学习,尤其是深度学习,现在是相当的火爆,不管是正在学的还是即将入坑的朋友,搞算法离不开两样基本东西:
1.数据 2.模型
不管是机器学习,还是深度学习那么我们在实践中所遇到的困惑有哪些呢?
困惑1:数据从哪里来? 困惑2:数据该如何处理? 困惑3:模型该如何去建模? 困惑4:实践结果不理想,如何去调参?
等等一系列的困惑…….在这对上面的困惑给大家建议建议,有没说到的或说的不对希望大家补充和包容.
困惑1:数据从哪里来?
大家都知道,能够玩得起人工智能的公司,公司都有至少5年以上的相关积累,一个刚成立1-2年公司,几乎不太可能,数据量太少.所以…..所以数据来源一般都是公司后台数据库中的数据或者是大量的日志文件信息等.然后你获得仅仅是原始数据,然而这些数据可能”并没有什么卵用”!,是不是很失望!
困惑2:数据该如何处理?
只有好数据,才会有好模型,进而才会有好的实践结果,那么如何把一波原始杂乱无序的数据变成好数据呢,这里要提到一个术语叫:数据清洗.互联网数据基本上需要进行分析的都以日志数据为主,不管是点击数据还是浏览数据,都是海量的日志型数据,处理日志,如何清理无用数据,如何清除机器流量,去掉恶意点击,去掉重复数据,这个就没什么套路了,八仙过海,各显神通,能过去就能沉淀下有用的数据,过不去你怎么调模型也得不到想要的结果。
然而数据清洗,这是一个长期的,需要坚持不懈的,枯燥无趣的,技巧性很强的劳动。那么如何进行数据清洗呢?
据很多人的经验数据清洗的步骤,这里总结一下:
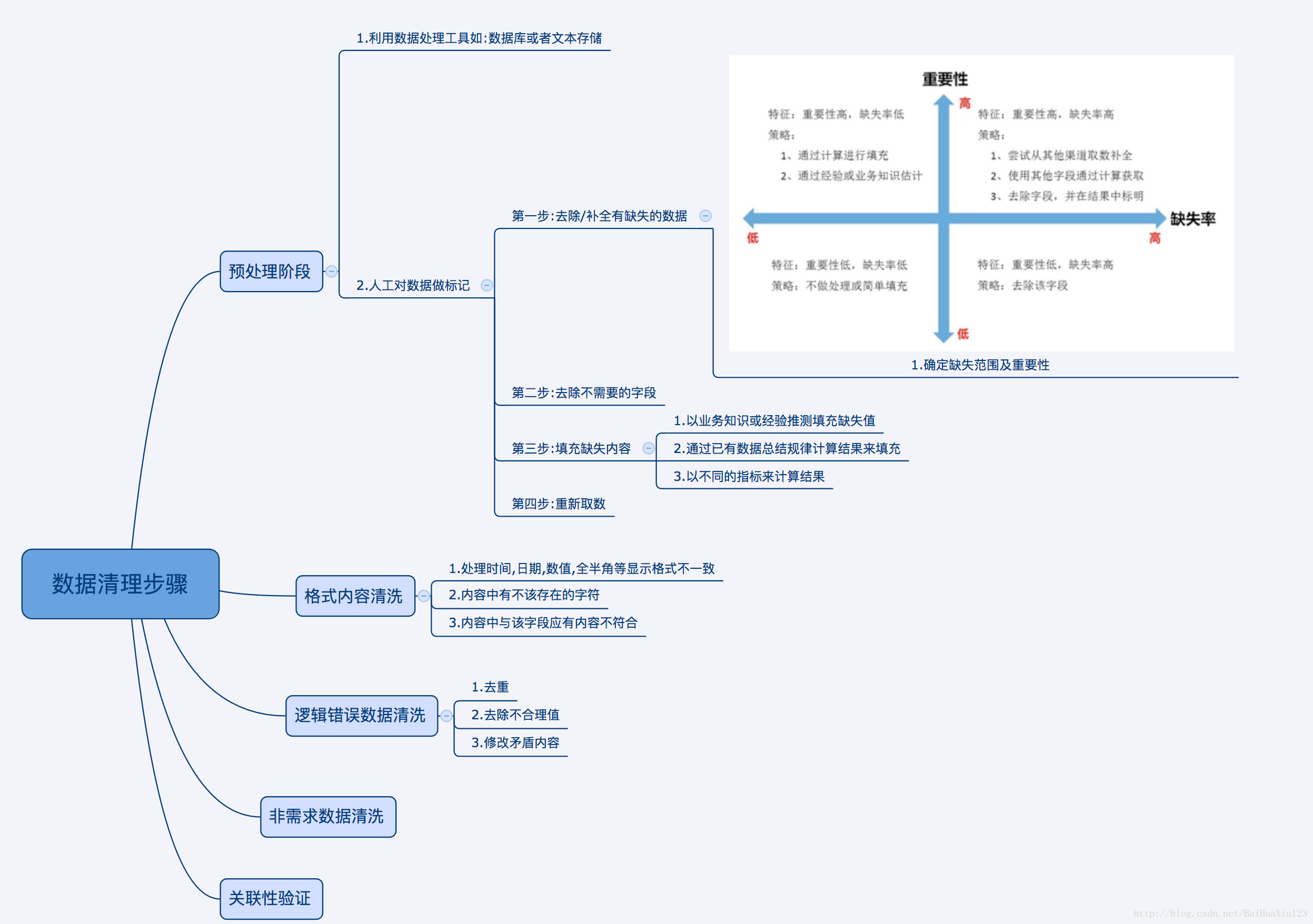
所有,数据清理是个体力活,同样也是整个数据分析过程中不可缺少的一个环节,其结果质量直接关系到模型效果和最终结论。在实际操作中,数据清洗通常会占据分析过程的50%—80%的时间。
困惑3:模型该如何去选
现在问题来了,碰到一个场景,那你应该用哪个模型?基本上现在的机器学习,都是个分类的问题,不管广告中的是点击率预估还是文本分类,垃圾邮件分析,图像识别,其实说到底都是个分类的问题,所以上面说的那些个模型也基本都是分类模型,那么实际情况中用什么模型呢?我们看到各种书上介绍朴素贝叶斯的时候必然会提到垃圾邮件分类,仿佛这是垃圾邮件分类的标准模型,但为什么不用逻辑回归呢?这里你可以说是经验,因为大家都用贝叶斯方法来做垃圾邮件过滤,所以他的效果可能更好。但是在实际工程应用中可不是每个都有经验的,遇到一个新问题,用哪个模型呢?这个是你学习完各种高大上模型,推导完各种公式以后,还是很难解决的问题。就说垃圾邮件过滤这个,你觉得QQ邮箱的垃圾邮件过滤,Gmail的垃圾邮件过滤,是用的朴素贝叶斯?
即便通过牛逼的理论知识,选择了合适的模型,跑起了数据,得到了结果,但是结果并不令人满意,这时,你还能做什么呢?呵呵呵呵,调参数吧。
所以说,光从模型上来说,就牵扯到具体问题具体分析的情况,这还只是第一步,因为你无论理论多么强,无论怎么分析,确定一个合适的模型以后,希望能够通过这个模型有较好的产出,其实吧,并没有什么卵用。后面还有一座数据的大山需要你去攀登。
所以数据处理很重要,数据处理好了,几个相近的模型最终得出的实验效果是差不多的,如何通过目标来选出一个模型,最终得出一个相对较好好的效果?
这里给大家总结几点:
1.靠经验 2.前提数据清洗,只要是数据清洗的好,在相近的算法得出的效果差不多
困惑4:实践结果不理想,如何去调参?
调参下一节详细讲解,请关注

相关文章推荐
- 机器学习如何选择模型 & 机器学习与数据挖掘区别 & 深度学习科普
- 如何选择机器学习模型进行数据分析_简要笔记
- 机器学习如何选择模型 & 机器学习与数据挖掘区别 & 深度学习科普
- 面对数据缺失,如何选择合适的机器学习模型?
- python机器学习库sklearn——数据归一化、标准化、特征选择、逻辑回归、贝叶斯分类器、KNN模型、支持向量机、参数优化
- vs2010/vs2012 创建ADO.NET实体数据模型时选择数据库跳出
- 机器学习、统计分析、数据挖掘、神经网络、人工智能、模式识别,
- JCR和RDBMS数据模型的技术选择
- 机器学习中规则化和模型选择知识
- 人工智能,机器学习,统计学习,数据挖掘概念解读
- 机器学习与数据挖掘_线性模型 II
- 分布式机器学习的故事(四):Rephil和MapReduce——描述长尾数据的数学模型
- 小白学数据分析----->付费用户的金字塔模型实践操作
- 美团推荐算法实践:机器学习重排序模型成亮点
- 万物相联:传感器、大数据、机器学习、人工智能和机器人是怎样联系在一起的?
- 加州理工学院公开课:机器学习与数据挖掘_线性模型 II(第九课)
- 机器学习之模型评估与模型选择(学习笔记)
- ASP.NET MVC 模型和数据对象映射实践
- 人工智能、机器学习、模式识别、数据挖掘、自然语言处理
- 【机器学习实践(2)】K近邻(KNN)模型