30 Examples For Awk Command In Text Processing
2017-05-09 11:19
435 查看
command and we saw many examples of using it in text processing and we saw how it is good in this, but it has some limitations. Sometimes you need a more advanced tool for manipulating data, one that provides a more programming-like environment, giving
you more control to modify data in a file. This is where awk command comes in.
The awk command or GNU awk in specific takes stream editing one step further than the sed editor by providing a scripting language instead of just editor commands. Within the awk scripting language, you can do the following:
Define variables to store data.
Use arithmetic and string operators to operate on data.
Use structured programming concepts and control flow, such as if-then statements and loops, to add logic to your text processing.
Generate formatted reports.
Actually, generating formatted reports comes very handy when working with log
files that contain maybe millions of lines to output a readable report that you can benefit from.
Table of Contents [hide]
1 awk
command options
2 Reading
the program script from the command line
3 Using
data field variables
4 Using
multiple commands
5 Reading
the program from a file
6 Running
scripts before processing data
7 Running
scripts after processing data
8 Built-in
variables
9 Data
variables
10 User
defined variables
11 Structured
Commands
11.1 While
loop
11.2 The
for loop
12 Formatted
Printing
13 Built-In
Functions
13.1 Mathematical
functions
14 String
functions
15 User
Defined Functions
awk command options
The awk command has a basic format as follows:$ awk options program file
And these are some of the options for the awk command that you will use often:
-F fs To specify a file separator for the fields in a line.
-f file To specify a file name to read the program from.
-v var=value To define a variable and default value used in the awk command.
–mf N
To specify the maximum number of fields to process in the data file.
–mr N
To specify the maximum record size in the data file.
You can write scripts to read the data from a text line and then manipulate the data and display the result.
Reading the program script from the command line
Awk program script is defined by opening and closing braces. Also, you must write your script between single quotation marks like this:$ awk '{print
"Welcome to awk command tutorial"}'
If you run this command, nothing happenes!! And this because no filename was defined in the command line.
The awk command retrieves data from STDIN.
If you type a line of text and press Enter, the awk command runs the program through the text. Just like the sed editor, the awk command executes the program script on each line of text available in the data stream.
$ awk '{print
"Welcome to awk command tutorial "}'

If you type anything, it returns the same welcome string we provide.
To terminate the program, we have to send End-of-File (EOF) character. The Ctrl+D key combination sends an EOF character. Maybe you disappointed with this example but wait for the awesomeness.
Using data field variables
One of the main features of awk is its ability to manipulate data in a text file. It does this by automatically assigning a variable to each element in a line. By default, awk uses the following variables for each data field it detects in a line of text:$0 for the entire line of text.
$1 for the first data field in the line.
$2 for the second data field in the line.
$n for the nth data field in the line.
Each data field is defined in a text line by a field separation character.
The default field separation character in awk is any whitespace character like tab or space.
Look at the following file and see how awk deals with it:
$ awk '{print
$1}' myfile
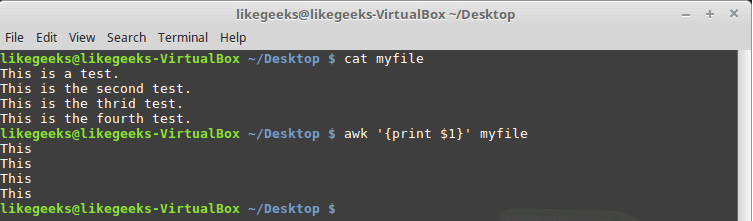
This command uses the $1 field variable to display only the first data field for each line of text.
Sometimes the separator in some files is not space nor tab but something else. You can specify it using –F option:
$ awk -F: '{print
$1}' /etc/passwd
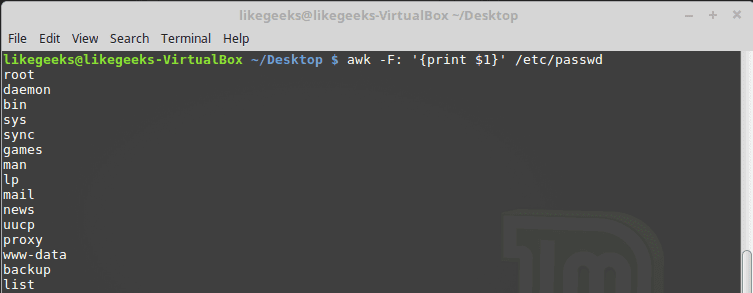
This command shows the first data field in the passwd file. Because the /etc/passwd file uses a colon to separate the data fields, I use the colon as a separator.
Using multiple commands
The awk scripting language allows you to combine commands in a normal program.To run multiple commands on the command line, put a semicolon between commands like this:
$ echo "My
name is Tom" | awk '{$4="Adam";
print $0}'

The first command assigns a value to the $4 field variable. The second command prints the entire line.
Reading the program from a file
As with the sed command, the awk command allows you to store your script in a file and refer to it from the command line with the -f option.Our file contains this script:
{print $1 "
has a home directory at " $6}
$ awk -F: -f testfile /etc/passwd
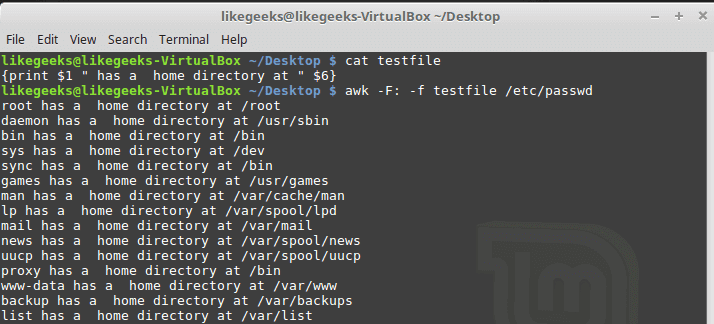
Here we print the username which is the first field $1 and the home path, which is the sixth field $6 from /etc/passwd, and we specify the file that contains that script which is called myscipt with the -f option and surely the separator is specified with capital
-F which is the colon.
You can specify multiple commands in the script file, just place each command on a separate line.
This is our file:
| 1234567 | { text = " has a home directory at " print $1 $6 } |

Here we define a variable that holds a text string used in the print command.
Running scripts before processing data
If you need to create a header section for the report or something similar, you need to run a script before processing the data.The BEGIN keyword is used to accomplish this. It forces awk to execute the script specified after the BEGIN keyword and before awk reads the data:$ awk 'BEGIN {print "Hello World!"}'Let’s apply it to something we can see the result:| 1 2 3 | $ awk 'BEGIN {print "The File Contents:"} $0}' myfile |
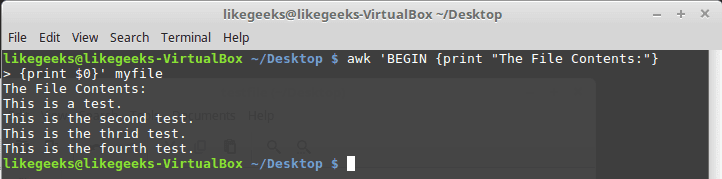
Don’t forget the single quotation marks.
Running scripts after processing data
To run a script after processing the data, use the END keyword:| 12345 | $ awk 'BEGIN {print "The File Contents:"} {print $0} END {print "End of File"}' myfile |
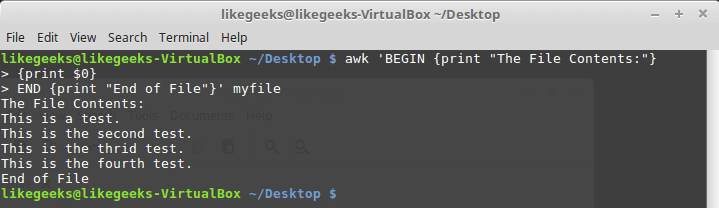
After printing the file contents is finished, the awk command executes the commands in the END section. This is useful, you can use it to add a footer for example.We can put all these elements together into a nice little script file:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | BEGIN { "The latest list of users and shells" " UserName \t HomePath" "-------- \t -------" FS=":" } { $1 " \t " $6 } END { "The end" } |
$ awk -f myscript /etc/passwd
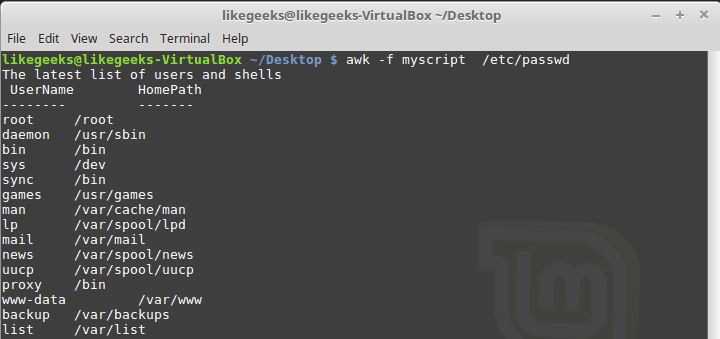
This shows you a small piece of the power available when you use simple awk scripts.
Built-in variables
The awk command uses built-in variables to reference specific features within the program data.We saw the data field variables $1, $2 $3, etc are used to extract data fields, we also deal with the field separator FS which is by default is a whitespace character, such as space or a tab.
But these are not the only variables, there are more built-in variables.
The following list shows some of the built-in variables:
FIELDWIDTHS Specifies the list of numbers that defines the exact width (in spaces) of each data field.
RS Input record separator character.
FS Input field separator character.
OFS Output field separator character.
ORS Output record separator character.
By default, awk sets the OFS variable to space, By setting the OFS variable, you can use any string to separate data fields in the output:
$ awk 'BEGIN{FS=":";
OFS="-"} {print $1,$6,$7}' /etc/passwd
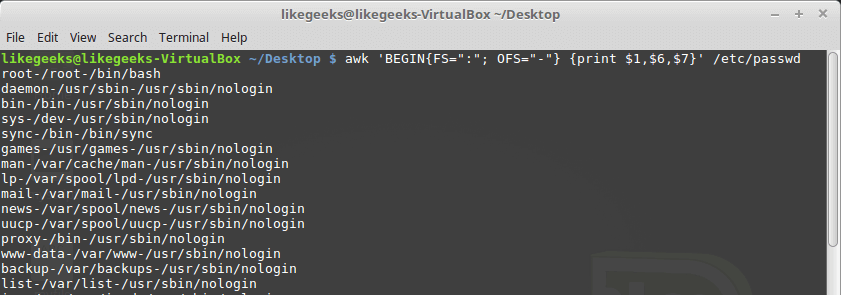
The FIELDWIDTHS variable enables you to read records without using a field separator character.
In some cases, instead of using a field separator, the data is placed in specific columns within the record. In these cases, you must set the FIELDWIDTHS variable to match the layout of the data in the records.
After you set the FIELDWIDTHS variable, awk ignores the FS and calculates data fields based on the provided field width sizes.
Suppose we have this content:
| 12345 | 1235.9652147.91 927-8.365217.27 36257.8157492.5 |
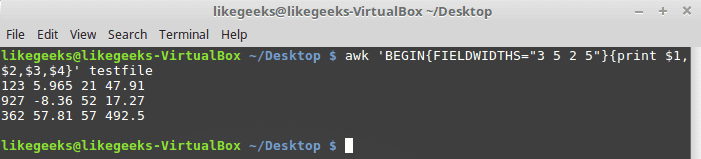
Look at the output. The FIELDWIDTHS variable defines four data fields, and awk command parses the data record accordingly. The numbers in each record are separated by the defined field width values.The RS and ORS variables define how your awk command handles records in the data. By default, awk sets the RS and ORS variables to the newline character which means that each new line of text in the input data stream is a new record.If your data fields are spread across multiple lines in the data stream like the following:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | Person Name 123 High Street (222) 466-1234 Another person 487 High Street (523) 643-8754 |
All you need to do is to set the FS variable to the newline character.
Also, you need to set the RS variable to an empty string. The awk command interprets each blank line as a record separator.
$ awk 'BEGIN{FS="\n";
RS=""} {print $1,$3}' addresses
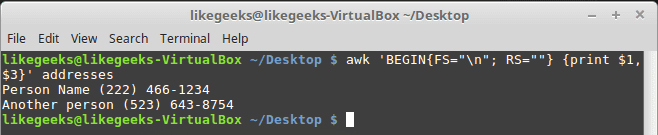
Awesome! The awk command interpreted each line in the file as a data field and the blank lines as record separators.
Data variables
Besides the built-in variables that you saw, there are some other built-in variables that help you knowing what’s going on with your data and how to extract information from the shell environment:ARGC Retrieves the number of command line parameters present.
ARGIND Retrieves the index in ARGV of the current file being processed.
ARGV Retrieves an array of command line parameters.
ENVIRON Retrieves an associative array of the current shell environment variables and their values.
ERRNO Retrieves the system error if an error occurs when reading or closing input files.
FILENAME Retrieves the filename of the data file used for input to the awk command.
NF The total number of data fields in the data file.
NR The number of input records processed.
FNR Retrieves the current record number in the data file.
IGNORECASE If set to a non-zero value it will ignore the case of characters.
You should know a few of these variables from the previous post about shell
scripting.
The ARGC and ARGV variables enable you to get the number of command line parameters.
This can be little tricky because the awk command doesn’t count the script as a part of the command line parameters.
$ awk 'BEGIN{print
ARGC,ARGV[1]}' myfile

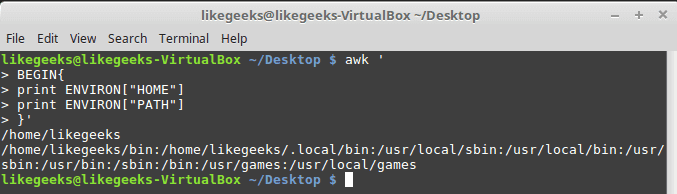
The ENVIRON variable uses an associative array to retrieve shell environment variables like this:
| 123456789 | $ awk ' BEGIN{ print ENVIRON["HOME"] print ENVIRON["PATH"] }' |
You can use shell variables without ENVIRON variables like this:$ echo | awk -v home=$HOME '{print "My home is " home}'

The NF variable enables you to specify the last data field in the record without having to know its position:$ awk 'BEGIN{FS=":"; OFS=":"} {print $1,$NF}' /etc/passwd
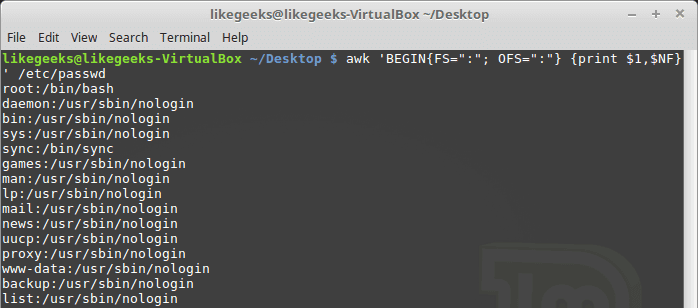
The NF variable contains the numerical value of the last data field in the data file. You can use this variable as a data field variable by placing a dollar sign in front of it.The FNR and NR variables are similar to each other but somewhat different. The FNR variable holds the number of records processed in the current data file. The NR variable holds the total number of records processed.Let’s take a look at these two examples to know the difference:$ awk 'BEGIN{FS=","}{print $1,"FNR="FNR}' myfile myfile
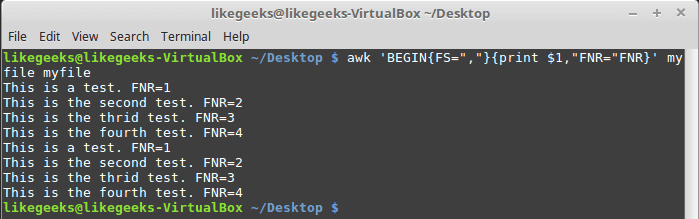
In this example, the awk command defines two input files. It defines the same input file 2 times. The script prints the first data field value and the current value of the FNR variable.Now, let’s add the NR variable and see the difference:
| 1 2 3 4 5 6 7 | $ awk ' BEGIN {FS=","} $1,"FNR="FNR,"NR="NR} END{print "There were",NR,"records processed"}' myfile myfile |
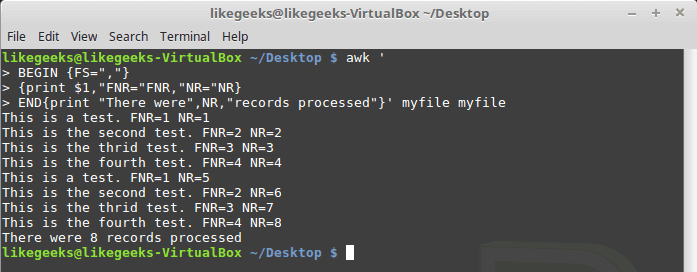
The FNR variable value was reset to 1 when awk processed the second data file, but the NR variable maintained its count in the second data file.
User defined variables
Like any other programming language, awk allows you to define your own variables.awk user-defined variable name can be any number of letters, digits, and underscores, but it can’t begin with a
digit.
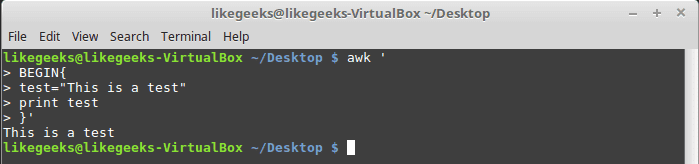
You can assign a variable as in shell scripting like this:
| 123456789 | $ awk ' BEGIN{ test="This is a test" print test }' |
Structured Commands
The awk scripting language supports the standard if-then-else format of the if statement. You must specify a condition for the if statement to evaluate, and enclosed in parentheses.The testfile contains the following:101563345$ awk '{if ($1 > 20) print $1}' testfile
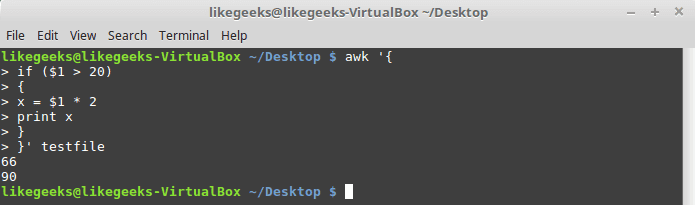
Just that simple.If you want to execute multiple statements in the if statement, you must enclose them in braces:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | $ awk '{ if ($1 > 20) { x = $1 * 2 x } }' testfile |
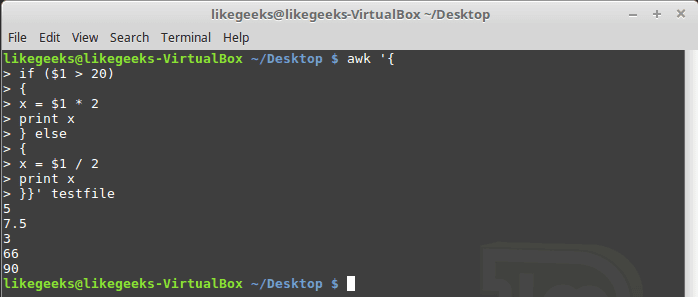
The awk if statement also supports the else clause like this:
| 12345678910111213141516171819 | $ awk '{ if ($1 > 20) { x = $1 * 2 print x } else { x = $1 / 2 print x }}' testfile |
You can use the else clause on a single line, but you need to use a semicolon after the if statement:
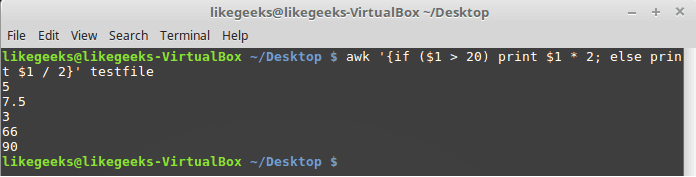
$ awk '{if ($1 > 20) print $1 * 2; else print $1 / 2}' testfile
While loop
The while loop enables you to iterate over a set of data, checking a condition that stops the iteration.cat myfile124 127 130112 142 135175 158 245| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | $ awk '{ total = 0 i = 1 while (i < 4) { total += $i i++ } avg = total / 3 "Average:",avg }' testfile |
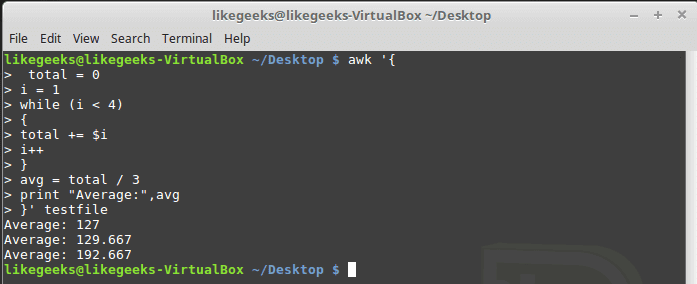
The while statement iterates over the data fields in the record and adds each value to the total variable and increments the counter variable i by 1.
When the counter value becomes 4, the while condition becomes FALSE, and the loop terminates, going to the next statement in the script. That statement estimates the average and prints it.
The awk scripting language supports using the break and continue statements in while loops, allowing you to jump out of the middle of the loop.
| 12345678910111213141516171819202122232425 | $ awk '{ total = 0 i = 1 while (i < 4) { total += $i if (i == 2) break i++ } avg = total / 2 print "The average of the first two elements is:",avg }' testfile |
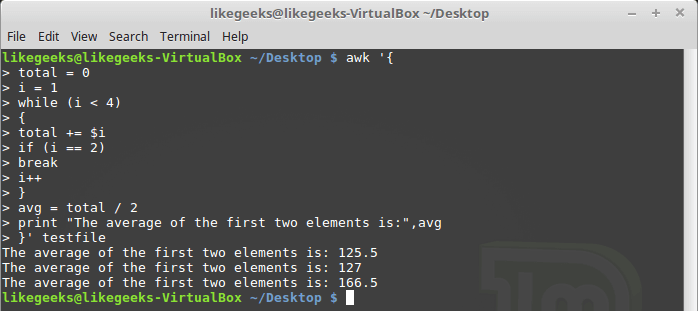
The for loop
The for loop is a common technique used in many programming languages for looping.The awk scripting language supports the for loops:| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | $ awk '{ total = 0 for (i = 1; i < 4; i++) { total += $i } avg = total / 3 "Average:",avg }' testfile |
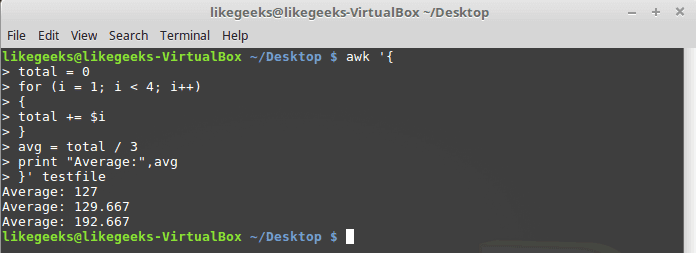
Formatted Printing
The printf command in awk allows you to specify detailed instructions on how to display data.It defines how the formatted output should appear, using both text elements and format specifiers.
A format specifier is a special code that implies what type of variable is displayed and how to display it. The awk command uses each format specifier as a placeholder for each variable listed in the command.
The format specifiers use the following format:
%[modifier]control-letter
This list shows the format specifiers you can use with printf:
c Prints a number as an ASCII character.
d Prints an integer value.
i Prints an integer value (same as d).
e Prints a number in scientific notation.
f Prints a floating-point value.
g Prints either scientific notation or floating point.
o Prints an octal value.
s Prints a text string.
Here we use printf to format our output:
| 1234567 | $ awk 'BEGIN{ x = 100 * 100 printf "The result is: %e\n", x }' |
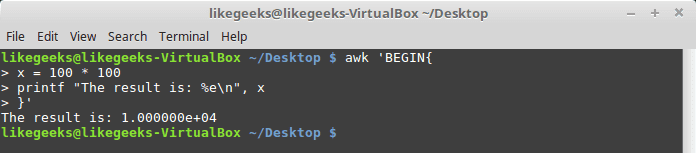
Here as an example, we display a large value using scientific notation %e.We are not going to try every format specifier. You know the concept.
Built-In Functions
The awk scripting language provides a few built-in functions that perform mathematical, string, and time functions. You can utilize these functions in your awk scripts.Mathematical functions
If you love math, these are some of the mathematical functions you can use with awk:cos(x) | exp(x) | int(x) | log(x) | rand() | sin(x) | sqrt(x)And they can be used normally:$ awk 'BEGIN{x=exp(5); print x}'
String functions
There are many string functions, you can check the list, but we will examine one of them as an example and the rest is the same:$ awk 'BEGIN{x = "likegeeks"; print toupper(x)}'
The function toupper converts character case to upper case for the passed string.
User Defined Functions
You can create your own functions for using in awk scripts, just define them and use them.| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | $ awk ' function myprint() { printf "The user %s has home path at %s\n", $1,$6 } BEGIN{FS=":"} { myprint() }' /etc/passwd |
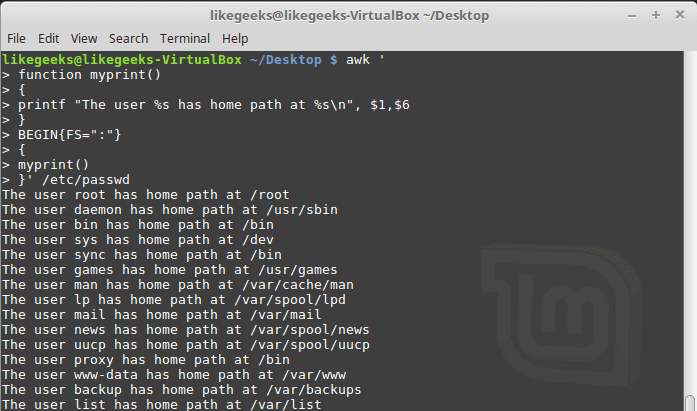
Here we define a function called myprint, then we use it in our script to print output using printf function.
I hope you like the post.
Thank you.

相关文章推荐
- Top 30 Nmap Command Examples For Sys/Network Admins
- Top 30 Nmap Command Examples For Sys/Network Admins
- Top 30 Nmap Command Examples For Sys/Network Admins
- Top 30 Nmap Command Examples For Sys/Network Admins
- for command in windows batch(tokens)/在batch中for命令的tokens
- HowTo: Use grep Command In Linux / UNIX [ Examples ]
- exec text in vim as Shell command!
- sql安装出错,出现command line optoin synatax error.type command?for help.
- Can not find so for swat in Samba in Solaris? Try crle command to update runtime linking configuration.
- Text Processing in Python
- Attached Command for Windows 8 Metro Style in C#
- Command for converting between ASCII text files and binary files
- John Paul Mueller, «Windows Administration at the Command Line for Windows 2003, Windows XP, and Windows 2000: In the Field Resu
- How to use "for/" batch command in Dos extention
- netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}';netstat -nat |wc -l
- Controlling text size in Safari for iOS without disabling user zoom
- Set CommandTimeout for a TableAdapter in the DataSet
- set timeout for a shell command in python
- 15 Practical Grep Command Examples In Linux / UNIX
- [转] Implementation of Fast Fourier Transform for Image Processing in DirectX 10