R中logistics回归分析以及K-CV
2017-04-30 13:03
351 查看
K倍交叉验证是对模型的性能进行评估,可以用来防止过拟合,比如对决策树节点数目的确定或是回归模型参数个数地决定等情况。
1.对于一些特殊数据来说,在调用glm()方法时候,会出现两种常见错误
Warning: glm.fit: algorithm did not converge
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning messages:
1: glm.fit:算法没有聚合
2: glm.fit:拟合機率算出来是数值零或一
针对第一种,一般是因为在回归拟合的时候次数少,control=list(maxit=100)修改次数为100即可;
第二种一般就是数据已经分散好了,可以理解为一种过拟合,由于数据的原因,在回归系数的优化搜索过程中,使得分类的种类属于某一种类(y=1)的线性拟合值趋于大,分类种类为另一 类(y=0)的线性拟合值趋于小。
以鸢尾花数据为例子,
testdata$y <- c(1:80)
qplot(pl,y,data =testdata,colour =factor(species));
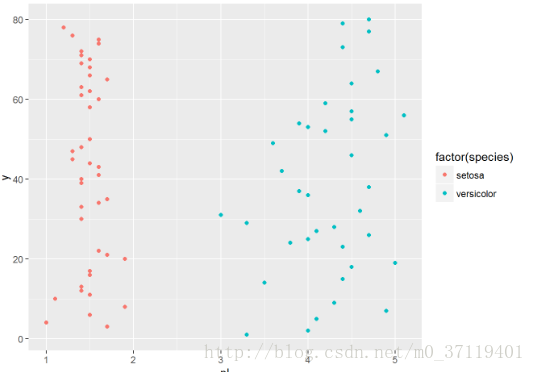
这种情况直接就可以划分了,无需回归分析
2.建立好回归模型,调用predict()进行评价,根据包里面的解释:

默认是线性预测因子的尺度; 若是
type= “response“<==>“响应”是响应变量的规模。
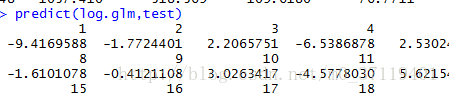
所以predict(log.glm) 返回的是”β0+β1x1+…βmxm”,而predict(log.glm,typee= “response“)返回的是P值。下图是我做的认为验证


3。下来就是通过K倍交叉验证评价模型好坏了,cv.glm(log.glm,trian,K=10)
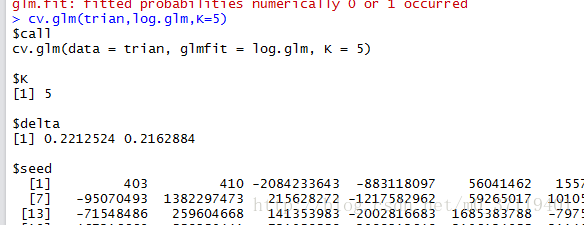
可以得到错误率;
4.最后可以画ROC曲线,由于cv.glm只有错误率没有P值,所以自己编了一个程序作了CV,得到图为:
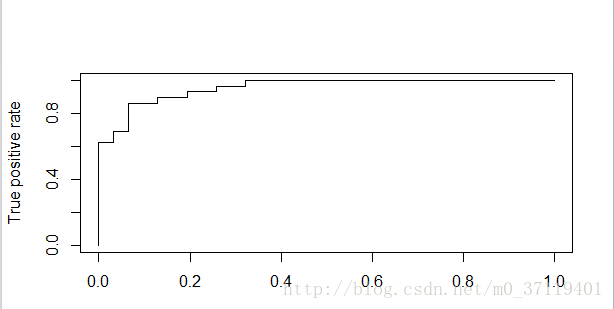
有一个疑问,就是做ROC曲线的时候,是不是把test_data分别带入相同模型五个不同的参数中得P值(以5倍交叉验证为例)??
自己也是蛮笨的,为了这个事情搞了一天半,加油吧,感情上是个loser,学习上盼望有点建树吧。
1.对于一些特殊数据来说,在调用glm()方法时候,会出现两种常见错误
Warning: glm.fit: algorithm did not converge
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning messages:
1: glm.fit:算法没有聚合
2: glm.fit:拟合機率算出来是数值零或一
针对第一种,一般是因为在回归拟合的时候次数少,control=list(maxit=100)修改次数为100即可;
第二种一般就是数据已经分散好了,可以理解为一种过拟合,由于数据的原因,在回归系数的优化搜索过程中,使得分类的种类属于某一种类(y=1)的线性拟合值趋于大,分类种类为另一 类(y=0)的线性拟合值趋于小。
以鸢尾花数据为例子,
这里写代码片
testdata$y <- c(1:80)
qplot(pl,y,data =testdata,colour =factor(species));
这种情况直接就可以划分了,无需回归分析
2.建立好回归模型,调用predict()进行评价,根据包里面的解释:
默认是线性预测因子的尺度; 若是
type= “response“<==>“响应”是响应变量的规模。
所以predict(log.glm) 返回的是”β0+β1x1+…βmxm”,而predict(log.glm,typee= “response“)返回的是P值。下图是我做的认为验证
3。下来就是通过K倍交叉验证评价模型好坏了,cv.glm(log.glm,trian,K=10)
可以得到错误率;
4.最后可以画ROC曲线,由于cv.glm只有错误率没有P值,所以自己编了一个程序作了CV,得到图为:
有一个疑问,就是做ROC曲线的时候,是不是把test_data分别带入相同模型五个不同的参数中得P值(以5倍交叉验证为例)??
自己也是蛮笨的,为了这个事情搞了一天半,加油吧,感情上是个loser,学习上盼望有点建树吧。

相关文章推荐
- 回归分析以及r语言实现(一)
- logistics回归--梯度上升算法以及改进--用于二分类
- 最速下降法 的原理以及在回归分析中的应用
- 生存分析cox回归R语言与SAS以及STATA参数估计结果不同
- 时间序列分析-R语言-随机游走以及回归画图
- 机器学习算法的Python实现 (1):logistics回归 与 线性判别分析(LDA)
- google的分析(analytics)js代码分析以及重写
- Tga图片格式分析以及程序实现
- 自我分析--惰性的形成以及提高现有的精神状况
- 数据绑定以及Container.DataItem几种方式与用法分析
- 另一种Atlas Scripts Intellisense的方法以及对比与分析
- 网络数据集的构建以及基于网络数据集的路径分析
- 数据绑定以及Container.DataItem的具体分析
- 位图文件(BMP)格式分析以及程序实现
- 团队开发规范(MSF)以及基于.Net的需求分析和解决方案设计
- NHibernate的关联映射(one-to-one,one-to-many,many-to-many)以及cascade分析
- U-Boot在GOLD44B0X开发板上的移植以及代码分析
- [cp] SLR分析表的生成 以及分析程序 (2)
- MS05-043漏洞利用分析以及ntdll!RtlFreeHeap中关于lookaside链表的操作
- [cp] SLR分析表的生成 以及分析程序(3)