逻辑斯蒂回归公式推导
2017-04-30 11:57
393 查看
逻辑斯蒂回归,一个不是很恰当的理解就是在线性回归的基础上加了一个sigmoid函数。将其输出空间映射到0-1上面来。
然后映射后的这个值就代表他被分为类别1的概率。
话不多说。这个就是逻辑回归(线性回归加上sigmoid的)最基本的公式。
线性回归是用y = wx_i +b 去拟合y_i也就是训练一组参数w使得wx+b尽可能的去逼近,而逻辑回归中的对数几率回归(周志华老师的书上有介绍,这里就不啰嗦了)用在分类问题上,它的目标是如果x是正样本,那么最后训练出的w和
b应该使得这个y尽可能的逼近1,负样本则是逼近于0。
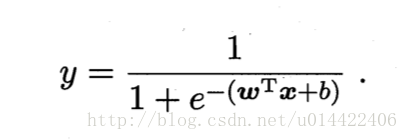

有了这两个公式。就可以用极大似然求解了。
极大似然的意思就是使训练样本中的数据出现的概率尽可能的大。
l(w,b)=∑i=1mlnp(yi|xi;w,b)
每个样本属于其真实标记的概率越大越好。
而
p(yi|xi;w,b)=p(y=0|xi;w,b)(1−yi)∗p(y=1|xi;w,b)yi
书上这里写得不是特别细。所以可能会有点误解。
解释一下上面的公式,当真实标记是1的时候前面一项为0,结果就是后面一项
p(yi|xi;w,b)=p(y=1|xi;w,b)记为p1
同理真实标记是0的时候
p(yi|xi;w,b)=p(y=0|xi;w,b)记为p0
带入极大似然函数得到
l(w,b)=∑i=1mlnp(yi|xi;w,b)=∑i=1mln(p(1−yi)0∗pyi1)=∑i=1m[(1−yi)lnp0+yilnp1]=∑i=1m[lnp0+yi(lnp1−lnp0)]
有前面的公式2,则有
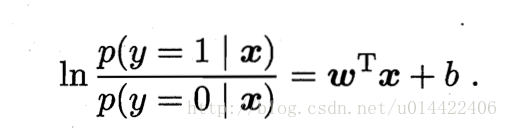
所以上面的
l(w,b)=∑i=1m[−ln(ewTx+b+1)+yi(wTx+b)]简写为∑i=1m[−ln(eβTxi+1)+yi(βTxi)]
求到这个地方就ok了。然后就是对他求导。
求导就直接用书上的公式了
只不过书上的公式和这相差一个负号。(注意相差一个负号)
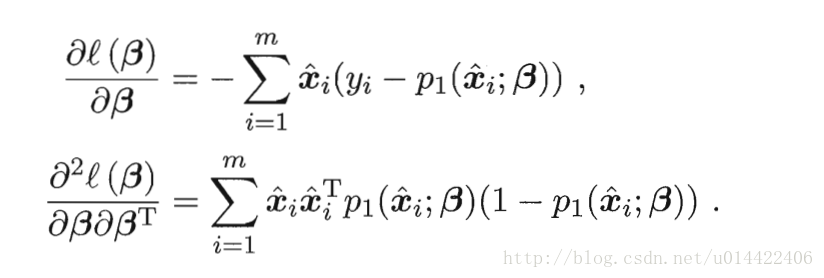
然后如果用梯度下降就直接用一阶导数迭代,牛顿法要用到一阶二阶导数。
然后映射后的这个值就代表他被分为类别1的概率。
话不多说。这个就是逻辑回归(线性回归加上sigmoid的)最基本的公式。
线性回归是用y = wx_i +b 去拟合y_i也就是训练一组参数w使得wx+b尽可能的去逼近,而逻辑回归中的对数几率回归(周志华老师的书上有介绍,这里就不啰嗦了)用在分类问题上,它的目标是如果x是正样本,那么最后训练出的w和
b应该使得这个y尽可能的逼近1,负样本则是逼近于0。
有了这两个公式。就可以用极大似然求解了。
极大似然的意思就是使训练样本中的数据出现的概率尽可能的大。
l(w,b)=∑i=1mlnp(yi|xi;w,b)
每个样本属于其真实标记的概率越大越好。
而
p(yi|xi;w,b)=p(y=0|xi;w,b)(1−yi)∗p(y=1|xi;w,b)yi
书上这里写得不是特别细。所以可能会有点误解。
解释一下上面的公式,当真实标记是1的时候前面一项为0,结果就是后面一项
p(yi|xi;w,b)=p(y=1|xi;w,b)记为p1
同理真实标记是0的时候
p(yi|xi;w,b)=p(y=0|xi;w,b)记为p0
带入极大似然函数得到
l(w,b)=∑i=1mlnp(yi|xi;w,b)=∑i=1mln(p(1−yi)0∗pyi1)=∑i=1m[(1−yi)lnp0+yilnp1]=∑i=1m[lnp0+yi(lnp1−lnp0)]
有前面的公式2,则有
所以上面的
l(w,b)=∑i=1m[−ln(ewTx+b+1)+yi(wTx+b)]简写为∑i=1m[−ln(eβTxi+1)+yi(βTxi)]
求到这个地方就ok了。然后就是对他求导。
求导就直接用书上的公式了
只不过书上的公式和这相差一个负号。(注意相差一个负号)
然后如果用梯度下降就直接用一阶导数迭代,牛顿法要用到一阶二阶导数。

相关文章推荐
- 逻辑斯蒂回归(LR)原理详解及公式推导
- [机器学习]逻辑回归公式推导及其梯度下降法的Python实现
- 逻辑回归-参数迭代公式推导
- Logistic Regression(逻辑回归)原理及公式推导
- 逻辑回归迭代公式推导
- 逻辑斯蒂回归参数梯度推导
- 逻辑回归公式推导过程
- 吴恩达老师深度学习视频课笔记:逻辑回归公式推导及C++实现
- Logistic Regression(逻辑回归)原理及公式推导
- Logistic Regression(逻辑回归)原理及公式推导
- 逻辑回归梯度下降公式详细推导
- 机器学习-逻辑回归-参数迭代公式推导
- 广义线性模型和逻辑回归的公式推导
- 逻辑斯蒂回归梯度下降法推导
- 转载-机器学习-逻辑回归-参数迭代公式推导
- 逻辑回归模型及LBFGS的Sherman Morrison(SM) 公式推导
- 逻辑回归公式推导
- [小白式机器学习(一)] logistic regression(LR)对数几率回归 / 逻辑回归 公式推导
- 十七、逻辑回归公式的数学推导
- 机器学习-逻辑回归-参数迭代公式推导