Dubbo扩展机制:ExtensionLoader
2017-04-26 00:00
405 查看
一、前言
Dubbo的ExtensionLoader是实现“微内核+插件式”的重要组件,它基于java spi机制却又提供了如下扩展:jdk spi仅仅通过接口类名获取所有实现,而ExtensionLoader则通过接口类名和key值获取一个实现
Adaptive实现,就是生成一个代理类,这样就可以根据实际调用时的一些参数动态决定要调用的类了
自动包装实现,这种实现的类一般是自动激活的,常用于包装类,比如Protocol的两个实现类:ProtocolFilterWrapper、ProtocolListenerWrapper
jdk spi具有以下缺点:
虽然ServiceLoader也算是使用的延迟加载,但是基本只能通过遍历全部获取,也就是接口的实现类全部加载并实例化一遍。如果你并不想用某些实现类,它也被加载并实例化了,这就造成了浪费。
获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类
Dubbo框架是以URL为总线的模式,即运行过程中所有的状态数据信息都可以通过URL来获取,比如当前系统采用什么序列化,采用什么通信,采用什么负载均衡等信息,都是通过URL的参数来呈现的,所以在框架运行过程中,运行到某个阶段需要相应的数据,都可以通过对应的Key从URL的参数列表中获取,比如在cluster模块,到服务调用触发到该模块,则会从URL中获取当前调用服务的负载均衡策略,以及mock信息等。
ExtensionLoader本身是一个单例工厂类,它对外暴露getExtensionLoader静态方法返回一个ExtensionLoader实体,这个方法的入参是一个Class类型,这个方法的意思是返回某个接口的ExtensionLoader。那么对于某一个接口,只会有一个ExtensionLoader实体。ExtensionLoader中主要提供了以下方法实现扩展点的操作:
static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type); String getExtensionName(T extensionInstance); String getExtensionName(Class<?> extensionClass); List<T> getActivateExtension(URL url, String key); List<T> getActivateExtension(URL url, String[] values); List<T> getActivateExtension(URL url, String key, String group); List<T> getActivateExtension(URL url, String[] values, String group); boolean isMatchGroup(String group, String[] groups); boolean isActive(Activate activate, URL url) ; T getLoadedExtension(String name); Set<String> getLoadedExtensions(); T getExtension(String name) ; T getDefaultExtension(); boolean hasExtension(String name); Set<String> getSupportedExtensions(); String getDefaultExtensionName(); void addExtension(String name, Class<?> clazz) ; T getAdaptiveExtension() ;
二、扩展点注解
1、SPI
Dubbo的SPI规范除了制定了在指定文件夹下面描述服务的实现信息之外,作为扩展点的接口必须标注SPI注解,用来告诉Dubbo这个接口是通过SPI来进行扩展实现的,否则ExtensionLoader则不会对这个接口创建ExtensionLoader实体,并且调用ExtensionLoader.getExtensionLoader方法会出现IllegalArgumentException异常。在接口上标注SPI注解的时候可以配置一个value属性用来描述这个接口的默认实现别名,例如Transporter的@SPI(“netty”)就是指定Transporter默认实现是NettyTransporter,因为NettyTransporter的别名是netty。这里再对服务别名补充有点,别名是站在某一个接口的维度来区分不同实现的,所以一个接口的实现不能有相同的别名,否则Dubbo框架将启动失败,当然不同接口的各自实现别名可以相同。到此ExtensionLoader的实现原则和基本原理介绍完了,接下来我们来看看怎么基于Dubbo的ExtensionLoader来实施我们自己的插件化。同样还是dubbo-demo项目中进行演示,在其中创建了一个demo-extension模块。Dubbo中有很多的扩展点,这些扩展点接口有以下这些:
CacheFactory Compiler ExtensionFactory LoggerAdapter Serialization StatusChecker DataStore ThreadPool Container PageHandler MonitorFactory RegistryFactory ChannelHandler Codec Codec2 Dispatcher Transporter Exchanger HttpBinder Networker TelnetHandler ZookeeperTransporter ExporterListener Filter InvokerListener Protocol ProxyFactory Cluster ConfiguratorFactory LoadBalance Merger RouterFactory RuleConverter ClassNameGenerator Validation
看一下SPI接口的定义:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
/**
* 缺省扩展点名,默认为空
*/
String value() default "";
}比如Transporter扩展点:
@SPI("netty")
public interface Transporter {
/**
* Bind a server.
*
* @see com.alibaba.dubbo.remoting.Transporters#bind(URL, Receiver, ChannelHandler)
* @param url server url
* @param handler
* @return server
* @throws RemotingException
*
* 作为服务端,注意bind之后返回的是一个Server,而参数是要监听的url和其对应的dubbo handler
*/
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
Server bind(URL url, ChannelHandler handler) throws RemotingException;
/**
* Connect to a server.
*
* @see com.alibaba.dubbo.remoting.Transporters#connect(URL, Receiver, ChannelListener)
* @param url server url
* @param handler
* @return client
* @throws RemotingException
*
* 作为客户端,注意connect之后返回的是一个Client,其参数为要连接的url和对应的dubbo hanlder
*/
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}2、Adaptive
上面看到了一个新的注解:Adaptive,它表示适配的意思,ExtensionLoader通过分析接口配置的adaptive规则动态生成adaptive类并且加载到ClassLoader中,来实现动态适配。配置adaptive的规则也是通过Adaptive注解来设置,该注解有一个value属性,通过设置这个属性便可以设置该接口的Adaptive的规则,上面说过服务调用的所有数据均可以从URL获取(Dubbo的URL总线模式),那么需要Dubbo帮我们动态生成adaptive的扩展接口的方法入参必须包含URL,这样才能根据运行状态动态选择具体实现。@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Adaptive {
/**
* 作为URL的Key名,对应的Value作为要Adapt成的Extension名。
* 如果URL中这些Key都没有Value,就使用缺省的扩展(在接口的SPI注解中设定的值)。
* 比如,String[] {"key1", "key2"},表示
* 先在URL上找key1的Value作为要Adapt成的Extension名;
* key1没有Value,则使用key2的Value作为要Adapt成的Extension名。
* key2没有Value,使用缺省的扩展(SPI中指定)。
* 如果没有设定缺省扩展,则方法调用会抛出IllegalStateException。
* 如果不设置则缺省使用Extension接口类名的点分隔小写字串。
* 即对于Extension接口com.alibaba.dubbo.xxx.YyyInvokerWrapper的缺省值为
* String[] {"yyy.invoker.wrapper"}
*
* @see SPI#value()
*/
String[] value() default {};
}这里仍以上面的Transporter接口中配置的adaptive规则为例,Transporter接口提供了两个方法,一个是connect(用来创建客户端连接),另一个是bind(用来绑定服务端端口提供服务),并且这两个方法上面均通过Adaptive注解配置了value属性,bind配置的是server和transporter,connect配置的是client和transporter。那么配置这些值有什么用呢?下面看看ExtensionLoader根据这些生成了什么样的adaptive代码。
public class Transporter$Adpative implements com.alibaba.dubbo.remoting.Transporter {
public com.alibaba.dubbo.remoting.Client connect(com.alibaba.dubbo.common.URL arg0, com.alibaba.dubbo.remoting.ChannelHandler arg1) throws com.alibaba.dubbo.remoting.RemotingException {
if (arg0 == null) throw new IllegalArgumentException("url == null");
com.alibaba.dubbo.common.URL url = arg0;
String extName = url.getParameter("client", url.getParameter("transporter", "netty"));
if (extName == null)
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.remoting.Transporter) name from url(" + url.toString() + ") use keys([client, transporter])");
com.alibaba.dubbo.remoting.Transporter extension = (com.alibaba.dubbo.remoting.Transporter) ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.remoting.Transporter.class).getExtension(extName);
return extension.connect(arg0, arg1);
}
public com.alibaba.dubbo.remoting.Server bind(com.alibaba.dubbo.common.URL arg0, com.alibaba.dubbo.remoting.ChannelHandler arg1) throws com.alibaba.dubbo.remoting.RemotingException {
if (arg0 == null) throw new IllegalArgumentException("url == null");
com.alibaba.dubbo.common.URL url = arg0;
String extName = url.getParameter("server", url.getParameter("transporter", "netty"));
if (extName == null)
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.remoting.Transporter) name from url(" + url.toString() + ") use keys([server, transporter])");
com.alibaba.dubbo.remoting.Transporter extension = (com.alibaba.dubbo.remoting.Transporter) ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.remoting.Transporter.class).getExtension(extName);
return extension.bind(arg0, arg1);
}
}可以看到bind方法先对url参数(arg0)进行了非空判断,然后便是调用url.getParameter方法,首先是获取server参数,如果没有获取成功就获取transporter参数,最后如果两个参数均没有,extName便是netty。获取完参数之后,紧接着对extName进行非空判断,接下来便是获取Transporter的ExtensionLoader,并且获取别名为extName的Transporter实现,并调用对应的bind,进行绑定服务端口操作。connect也是类似,只是它首先是从url中获取client参数,在获取transporter参数,同样如果最后两个参数都没有,那么extName也是netty,也依据extName获取对已的接口扩展实现,调用connect方法。
需要注意的是,没有打上Adaptive注解的方法是不可以调用的,否则会抛出UnsupportedOperationException异常。同时,Adaptive还可以打在一个接口的实现类上,这通常用于接口的方法参数中没有URL(因此也就没有办法动态路由到具体实现类),因此这个时候就需要手动实现一个扩展点接口的Adaptive实现类,比如先顶一个扩展点接口:
@SPI("default")
public interface MyFirstExtension {
public String sayHello(String name,ExtensionType type);
}接下来就是对这个插件接口提供不同的实现,可以上面接口方法sayHello方法入参中并没有URL类型,所以不能通过Dubbo动态生成adaptive类,需要自己来实现一个适配类。适配类如下:
@Adaptive
public class AdaptiveExtension implements MyFirstExtension {
@Override
public String sayHello(String name,ExtensionType type) {
ExtensionLoader extensionLoader = ExtensionLoader.getExtensionLoader(MyFirst Extension.class);
MyFirstExtension extension= (MyFirstExtension) extensionLoader.getDefaultExtension();
switch (type){
case DEFAULT:
extension= (MyFirstExtension) extensionLoader.getExtension("default");
break;
case OTHER:
extension= (MyFirstExtension) extensionLoader.getExtension("other");
break;
}
return extension.sayHello(name,type);
}
}可见在AdaptiveExtension中将会根据ExtensionType分发扩展的具体实现,并调用其sayHello方法。
注:一个接口只可能存在一个Adaptive适配实现。
3、Activate
Activate注解主要用处是标注在插件接口实现类上,用来配置该扩展实现类激活条件。首先看一下Activate注解定义:@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Activate {
/**
* Group过滤条件。
* <br />
* 包含{@link ExtensionLoader#getActivateExtension}的group参数给的值,则返回扩展。
* <br />
* 如没有Group设置,则不过滤。
*/
String[] group() default {};
/**
* Key过滤条件。包含{@link ExtensionLoader#getActivateExtension}的URL的参数Key中有,则返回扩展。
* <p />
* 示例:<br/>
* 注解的值 <code>@Activate("cache,validatioin")</code>,
* 则{@link ExtensionLoader#getActivateExtension}的URL的参数有<code>cache</code>Key,或是<code>validatioin</code>则返回扩展。
* <br/>
* 如没有设置,则不过滤。
*/
String[] value() default {};
/**
* 排序信息,可以不提供。
*/
String[] before() default {};
/**
* 排序信息,可以不提供。
*/
String[] after() default {};
/**
* 排序信息,可以不提供。
*/
int order() default 0;
}在Dubbo框架里面的Filter的各种实现类都通过Activate标注,用来描述该Filter什么时候生效。比如MonitorFilter通过Activate标注用来告诉Dubbo框架这个Filter是在服务提供端和消费端会生效的;而TimeoutFilter则是只在服务提供端生效,消费端是不会调用该Filter。 ValidationFilter要激活的条件除了在消费端和服务提供端激活,它还配置了value,这个表述另一个激活条件,上面介绍要获取activate extension都需要传入URL对象,那么这个value配置的值则表述URL必须有指定的参数才可以激活这个扩展。例如ValidationFilter则表示URL中必须包含参数validation(Constants.VALIDATION_KEY常量的值就是validation),否则即使是消费端和服务端都不会激活这个扩展实现,仔细的同学还会发现在ValidationFilter中的Activate注解还有一个参数order,这是表示一种排序规则。因为一个接口的实现有多种,返回的结果是一个列表,如果不指定排序规则,那么可能列表的排序不可控,为了实现这个所以添加了order属性用来控制排序,其中order的值越大,那么该扩展实现排序就越靠前。除了通过order来控制排序,还有before和after来配置当前扩展的位置,before和after配置的值是扩展的别名(扩展实现的别名是在图23中等号左边内容,下面出现的别名均是此内容)。
@SPI
public interface Filter {
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
}@Activate(group = {Constants.PROVIDER, Constants.CONSUMER})
public class MonitorFilter implements Filter {……}
@Activate(group = Constants.PROVIDER)
public class TimeoutFilter implements Filter {……}
@Activate(group = { Constants.CONSUMER, Constants.PROVIDER }, value = Constants.VALIDATION_KEY, order = 10000)
public class ValidationFilter implements Filter {……}上面基本对activate介绍的差不多了,在Dubbo框架中对这个用的最多的就是Filter的各种实现,因为Dubbo的调用会经过一个过滤器链,哪些Filter这个链中是通过各种Filter实现类的Activate注解来控制的。包括上面说的排序,也可以理解为过滤器链中各个Filter的前后顺序。这里的顺序需要注意一个地方,这里的排序均是框架本身实现扩展的进行排序,用户自定义的扩展默认是追加在列表后面。说到这里具体例子:
<dubbo:reference id=”fooRef” interface=”com.foo.Foo” ….. filter=”A,B,C”/>
假设上面是一个有效的消费端服务引用,其中配置了一个filter属性,并且通过逗号隔开配置了三个过滤器A,B,C(A,B,C均为Filter实现的别名),那么对于接口Foo调用的过滤器链是怎么样的呢?首先Dubbo会加载默认的过滤器(一般消费端有三个ConsumerContextFilter,MonitorFilter,FutureFilter),并且对这些默认的过滤器实现进行排序(ActivateComparator实现排序逻辑),这写默认过滤器实现会在过滤器链前面,后面紧接着的才是A,B,C三个自定义过滤器。
4、wrapper
dubbo中还存在另一种扩展实现,那就是装饰器,装饰器扩展本身也只是一个扩展接口的实现而已,唯一的特殊在于,它具有一个参数类型为自身类型的构造函数,因此该扩展实现的作用主要用来增强、装饰其他扩展。一下代码片段来自:loadFile方法。} else {// 不是@Adaptive类型
try {
// 如果有一个构造器的参数类型为本类型,那么这就是一个装饰器类
// 判断是否Wrapper类型
clazz.getConstructor(type);
Set<Class<?>> wrappers = cachedWrapperClasses;
if (wrappers == null) {
cachedWrapperClasses = new ConcurrentHashSet<Class<?>>();
wrappers = cachedWrapperClasses;
}
// 放入到Wrapper实现类缓存中
wrappers.add(clazz);
} catch (NoSuchMethodException e) {在一个扩展实现被加载时,该扩展接口对应的多有装饰器都会被无序的装饰到这个扩展实现上。这在createExtension中可以清晰的看到:
private T createExtension(String name) {
// 得到所有的扩展类缓存
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
// 没有扩展实现
throw findException(name);
}
try {
// 现在缓存中看看有没有对应的实例
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
// 如果没有,就新建一个扩展类的实例,并放入缓存
EXTENSION_INSTANCES.putIfAbsent(clazz, (T) clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 给这个实例注入各种属性(set注入)
injectExtension(instance);
// 一个接口类型type的所有实现类中,如果构造器只有一个参数且这个参数类型为type,那么会被作为一个装饰器
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && wrapperClasses.size() > 0) {
for (Class<?> wrapperClass : wrapperClasses) {
// 装饰器(对每个装饰后的实例都要执行set注入)
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance(name: " + name + ", class: " +
type + ") could not be instantiated: " + t.getMessage(), t);
}
}三、使用方法总结
每个定义的SPI的接口都会构建一个ExtensionLoader实例,ExtensionLoader采用工厂模式,以静态方法向外提供ExtensionLoader的实例。实例存储在ExtensionLoader内部静态不可变Map中。外部使用时调用:
ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();getExtensionLoader方法创建ExtensionLoader实例,getAdaptiveExtension方法会加载扩展点中的实现类,并创建或者选择适配器。
读取SPI注解的value值,如果value不为空则作为缺省的扩展点名
依次读取指定路径下的扩展点
META-INF/dubbo/internal/
META-INF/dubbo/
META-INF/dubbo/services/
getAdaptiveExtension方法最终调用loadFile方法逐行读取SPI文件内容并进行解析
实现类上是否含有@Adaptive注解,如果有,则将其作为适配器缓存到cachedAdaptiveClass,并进入下一行配置的解析,一个SPI只能有一个适配器,否则会报错;
如果实现类上没有@Adaptive注解,那么看其是否存在以当前获取接口类型为入参的构造器,如果有,则将其作为包装器(wrapper)存入cachedWrapperClasses变量;
如果实现类既没有@Adaptive注解,也不是包装器,那它就是扩展点的具体实现
判断扩展实现上是否有@Activate注解,如果有,将其缓存到cachedActivates(一个类型为
Map<String, Activate>的变量)中,然后将其key作为扩展点的名字,放入cachedClasses(一个类型为
Holder<Map<String, Class<?>>>的变量)中,dubbo支持在配置文件中n:1的配置方式,即:不同名的协议使用同一个SPI实现,只要配置名字按照正则
\s*[,]+\s*命名即可。
完成对文件的解析后,getAdaptiveExtension方法开始创建适配器实例。如果cachedAdaptiveClass已经在解析文件中确定,则实例化该对象;如果没有,则创建适配类字节码。
Dubbo能够为没有适配器的SPI生成适配器字节码的必要条件:
接口方法中必须至少有一个方法打上了@Adaptive注解
打上了@Adaptive注解的方法参数必须有URL类型参数或者有参数中存在getURL()方法
Dubbo生成代码后需要对代码进行编译,大家注意,Dubbo中服务皆是SPI,编译器的获取依然需要ExtensionLoader来加载,Dubbo缺省编译器为javassist。Dubbo在加载Compiler时,Compiler的实现类之一AdaptiveCompiler中有@Adaptive的注解,即有已实现的适配器,Dubbo不必为Compiler生成字节码,不然此时就死循环了。
拿到适配器Class后,Dubbo对适配器进行实例化,并且实现了一个类似IOC功能的变量注入。IOC代码非常简单,拿出类中public的set方法,从objectFactory中获得对应的属性值进行设置。
四、流程图
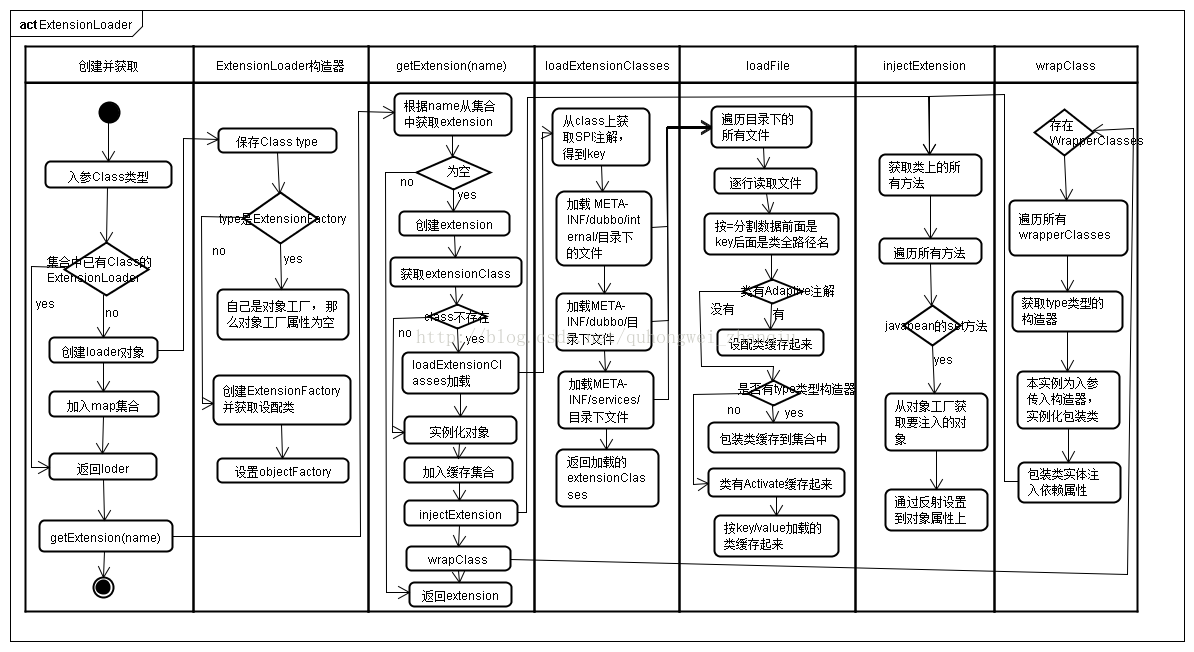
四、参考资料
https://my.oschina.net/bieber/blog/418949http://blog.csdn.net/quhongwei_zhanqiu/article/details/41577235
http://gaofeihang.cn/archives/278

相关文章推荐
- Dubbo扩展点加载机制 - ExtensionLoader
- Dubbo扩展点加载机制 - ExtensionLoader
- Dubbo的扩展机制
- Dubbo的扩展点机制分析(一)
- Dubbo扩展点机制分析(二)
- dubbo扩展机制
- Dubbo——扩展点加载机制
- Dubbo源码分析----扩展机制
- Dubbo调度机制解析(LoadBalance扩展)
- 深入dubbo之ExtensionLoader,灵活的扩展点加载机制
- 一、ExtensionLoader扩展点加载类解析(dubbo)
- Dubbo系列-3.扩展核心ExtensionLoader
- Dubbo/Dubbox的服务暴露(二)-扩展点机制
- Dubbo源码分析 ---- 基于SPI的扩展实现机制
- 聊聊Dubbo - Dubbo可扩展机制实战
- Dubbo中SPI扩展机制解析
- 关于Dubbo扩展点加载机制(1)
- dubbo源码解析(一): 扩展点加载(ExtensionLoader)
- 扩展点加载机制(ExtensionLoader)
- Dubbo源码解析之扩展点(ExtensionLoader)篇