全量数据同步与数据校验实践——应对百亿量级分库分表异构库迁移
2017-04-21 14:44
661 查看
在一家发展中的公司搬砖,正好遇到分库分表,数据迁移的需求比较多,就入坑了。最近有个系统重构,一直做数据重构、迁移、校验等工作,基本能覆盖数据迁移的各个基本点,所以趁机整理一下。
数据同步的场景是:数据库拆分、数据冗余、数据表重构。
数据重构服务主要包括:全量迁移、全量数据校验、增量数据同步和增量数据校验四个功能。
本文主要讲述DB-DB全量迁移的通用解决方案,主要是解决几个问题:
显然不行,查询到千万的时候执行一个 sql 要30s了,越到后面,sql执行速度越慢。[深抠系列]大家都说offset慢,但为什么呢?
结合索引与limit
就是对 key 字段排序,取大于minIndex的row_count 行记录,然后取这row_count行记录的最大值,做下一页查询的minIndex。参考:分页查询的那些坑
insert ,但不支持重试,每次重试都要先清理表,才能执行批量 insert操作,否则就主键冲突或者重复了,而且清理大表时需要花费不少的等待时间。
insert …on duplicate key update, 可以做到在不存在主键或唯一键的情况下,执行insert 操作,否则执行 update 操作,支持多次重试。在生产环境先清空表,再做全量迁移,更为保险。Demo SQL:
注意:在 mysql RR 隔离级别的情况下,表结构中有主键和唯一键的情况下,并发执行insert …on duplicate key update 存在死锁问题,可以设置 session 为 RC 隔离级别,初始化 sql:
前提是公司中有团队专门维护,并且已应用于日常的分库分表需求中,那么在数据迁移的时候使用代理工具会变得非常简单,你只需要关注源数据查询与数据转换,后面的活都可以交给代理工具来办。但是,使用代理工具意味着需要先请求代理服务,代理服务进行 sql 解析,根据规则路由计算分片,最后才去执行。瓶颈往往会发生在 代理服务的sql 解析和规则计算。
自己计算分片与 insert
比较灵活,直接查询目标分片数据库。根据拆分字段,表数量,表前缀和分片算法计算目标表名,然后从目标表池中找到该目标表所在库。
譬如:拆分字段是ACCOUNT_ID,表数量4096,均匀分布在四个库中,表前缀是tb_account_detail, 分片算法是:拆分字段值对表数量4096取模;
那么,当ACCOUNT_ID = 88888888 时, 88888888 % 4096 = 1592,那么记录的分片目标表是tb_account_detail1592,在库表池中找到tb_account_detail1592,知道目标表在第二个库中;
把所有目标分片相同的记录都合并成一个批量 insert sql中执行。
优势:效率提高,由于使用固定的sql 格式,无需做sql 解析,可以对同一个目标分片的记录构造批量insert。
源数据的价格单位是元,同步到目标库后价格单位要是分;
一行记录,需要衍射出多行记录
根据字段 A,B 字段内容,构造 C 字段的值
本表字段值是 表2中 A字段值
我使用插件方式加载业务转换逻辑代码,分离数据迁移&校验主流程和业务逻辑转换,框架向业务转换逻辑提供分页数据,业务转换逻辑返回转换后的分页数据,框架执行后续迁移或校验的操作。
简单的,可以把业务转换逻辑代码安置在项目代码中,通过Class.forName()获取逻辑转换类并创建一个实例,这种方式不灵活。
复杂点,可以把业务转换逻辑代码,动态传入,可以以文件路径方式传入,也可以通过字符串方式传入,参考Java运行时动态生成class的方法
注意有坑:当更新部分字段时,表中有
网络传输主要受机房内部的传输带宽影响,可以暂时不考虑对硬件资源提升和底层传输协议优化;
插入目标记录和建立索引主要受表结构影响,记录的插入和建立索引都需要消费时间,通用工具不能改变表结构,因此插入目标记录和建立索引的效率优化在此也不考虑;
查询数据源方面,采用分页查询,为了避免使用 offset 导致查询效率越来越低,采用结合索引与limit 方案,可以使每一页查询都走索引查询,提高查询效率
数据处理步骤,包括数据包装、数据业务逻辑转换,计算目标分片等,主要是cpu 密集型。如果想简单粗暴些,cpu资源又充足的话,可以通过并发处理进行优化;但是个人不推荐效率优化都使用并发改造,治标不治本,我更喜欢是使用jprofile通过性能监控找到可优化的高 cpu 占用函数,再做函数优化。
目标数据同步部分优化,主要从批量数据插入和并发执行两个方面进行优化
全量数据迁移过程中,查询源数据步骤和插入目标数据步骤职责鲜明,插入目标数据步骤的处理速度一般情况下相比查询源数据慢,可以通过使用生产者消费者模型解耦这两个步骤。
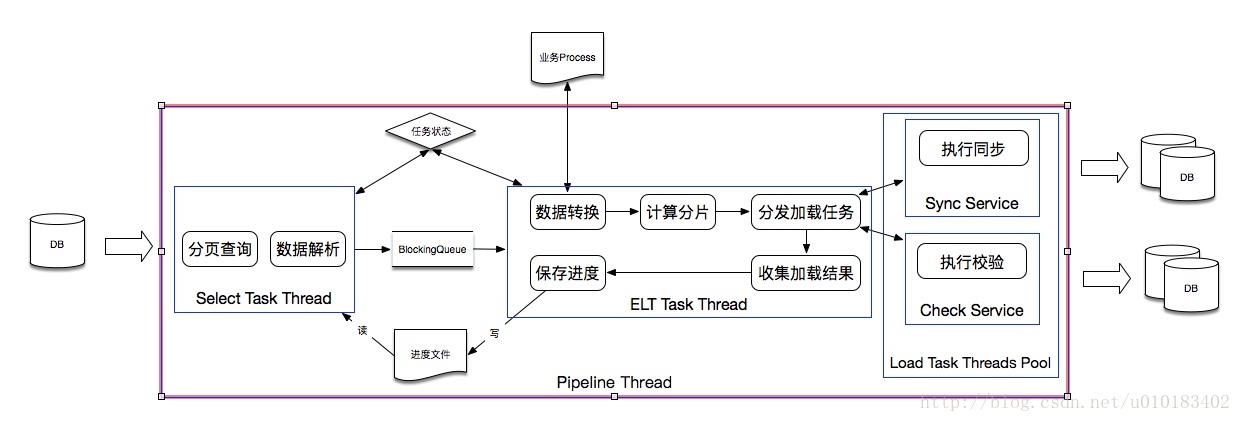
消费者线程从 Blocking Queue拉取分页数据后,依次执行数据业务逻辑转换,计算分片,分发并发任务执行插入,收集结果和保存处理进度
生产者与消费者共同监视一个volatile 关键字修饰的信号量,当任意一方发生失败,通过关闭信号量通知另一方终止任务。
同构/异构表数据表迁移
数据分库分表迁移与校验
数据同步的场景是:数据库拆分、数据冗余、数据表重构。
数据重构服务主要包括:全量迁移、全量数据校验、增量数据同步和增量数据校验四个功能。
本文主要讲述DB-DB全量迁移的通用解决方案,主要是解决几个问题:
NO.1 如何把一个亿量级的单表迁移至一个目标表?
分页查询sql选型
使用 offsetSELECT … LIMIT row_count OFFSET offset
显然不行,查询到千万的时候执行一个 sql 要30s了,越到后面,sql执行速度越慢。[深抠系列]大家都说offset慢,但为什么呢?
结合索引与limit
SELECT * FROM schemaAndTableWHERE{key} >= minIndexORDERBY{key} LIMIT ${row_count}就是对 key 字段排序,取大于minIndex的row_count 行记录,然后取这row_count行记录的最大值,做下一页查询的minIndex。参考:分页查询的那些坑
批量 insert sql 选型
只讨论 mysql 的情况,可以直接使用批量insert sql,也可以使用批量 insert …on duplicate key update sql。insert ,但不支持重试,每次重试都要先清理表,才能执行批量 insert操作,否则就主键冲突或者重复了,而且清理大表时需要花费不少的等待时间。
insert …on duplicate key update, 可以做到在不存在主键或唯一键的情况下,执行insert 操作,否则执行 update 操作,支持多次重试。在生产环境先清空表,再做全量迁移,更为保险。Demo SQL:
INSERT INTO`test`(`value`,`value2`,`value3`) VALUES ('v','g', 9), ('w','g', 5) ON DUPLICATE KEY UPDATE value=VALUES(value), value2=VALUES(value2), value3=VALUES(value3)注意:在 mysql RR 隔离级别的情况下,表结构中有主键和唯一键的情况下,并发执行insert …on duplicate key update 存在死锁问题,可以设置 session 为 RC 隔离级别,初始化 sql:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
NO.2 如何把一个亿量级的单表迁移至由多个实例数据库组成的分库分表中?
使用类似tddl的分库分表代理工具前提是公司中有团队专门维护,并且已应用于日常的分库分表需求中,那么在数据迁移的时候使用代理工具会变得非常简单,你只需要关注源数据查询与数据转换,后面的活都可以交给代理工具来办。但是,使用代理工具意味着需要先请求代理服务,代理服务进行 sql 解析,根据规则路由计算分片,最后才去执行。瓶颈往往会发生在 代理服务的sql 解析和规则计算。
自己计算分片与 insert
比较灵活,直接查询目标分片数据库。根据拆分字段,表数量,表前缀和分片算法计算目标表名,然后从目标表池中找到该目标表所在库。
譬如:拆分字段是ACCOUNT_ID,表数量4096,均匀分布在四个库中,表前缀是tb_account_detail, 分片算法是:拆分字段值对表数量4096取模;
那么,当ACCOUNT_ID = 88888888 时, 88888888 % 4096 = 1592,那么记录的分片目标表是tb_account_detail1592,在库表池中找到tb_account_detail1592,知道目标表在第二个库中;
把所有目标分片相同的记录都合并成一个批量 insert sql中执行。
优势:效率提高,由于使用固定的sql 格式,无需做sql 解析,可以对同一个目标分片的记录构造批量insert。
No.3 如何设计工具的系统结构,以应对业务对行记录进行转换需求呢?
数据迁移过程中,业务对数据有各种各样的转换需求,譬如:源数据的价格单位是元,同步到目标库后价格单位要是分;
一行记录,需要衍射出多行记录
根据字段 A,B 字段内容,构造 C 字段的值
本表字段值是 表2中 A字段值
我使用插件方式加载业务转换逻辑代码,分离数据迁移&校验主流程和业务逻辑转换,框架向业务转换逻辑提供分页数据,业务转换逻辑返回转换后的分页数据,框架执行后续迁移或校验的操作。
简单的,可以把业务转换逻辑代码安置在项目代码中,通过Class.forName()获取逻辑转换类并创建一个实例,这种方式不灵活。
public EventProcessor getProcessor(String processorName) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
Class<EventProcessor> processorClass = (Class<EventProcessor>) Class.forName("com.weidian.tech.baymax.processor.impl." + processorName);
return processorClass.newInstance();
}复杂点,可以把业务转换逻辑代码,动态传入,可以以文件路径方式传入,也可以通过字符串方式传入,参考Java运行时动态生成class的方法
注意有坑:当更新部分字段时,表中有
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP字段的需要特别注意,如果业务依赖该字段,需要把原update_time 值设置到 update sql中。
No.4 如何加速迁移效率?
迁移效率主要受查询数据源、数据处理、网络传输、插入目标记录、建立索引等步骤影响,网络传输主要受机房内部的传输带宽影响,可以暂时不考虑对硬件资源提升和底层传输协议优化;
插入目标记录和建立索引主要受表结构影响,记录的插入和建立索引都需要消费时间,通用工具不能改变表结构,因此插入目标记录和建立索引的效率优化在此也不考虑;
查询数据源方面,采用分页查询,为了避免使用 offset 导致查询效率越来越低,采用结合索引与limit 方案,可以使每一页查询都走索引查询,提高查询效率
数据处理步骤,包括数据包装、数据业务逻辑转换,计算目标分片等,主要是cpu 密集型。如果想简单粗暴些,cpu资源又充足的话,可以通过并发处理进行优化;但是个人不推荐效率优化都使用并发改造,治标不治本,我更喜欢是使用jprofile通过性能监控找到可优化的高 cpu 占用函数,再做函数优化。
目标数据同步部分优化,主要从批量数据插入和并发执行两个方面进行优化
全量数据迁移过程中,查询源数据步骤和插入目标数据步骤职责鲜明,插入目标数据步骤的处理速度一般情况下相比查询源数据慢,可以通过使用生产者消费者模型解耦这两个步骤。
解决方案
原理描述:
生产者线程从源数据库分页查询并组装数据后,推进 Blocking Queue消费者线程从 Blocking Queue拉取分页数据后,依次执行数据业务逻辑转换,计算分片,分发并发任务执行插入,收集结果和保存处理进度
生产者与消费者共同监视一个volatile 关键字修饰的信号量,当任意一方发生失败,通过关闭信号量通知另一方终止任务。
该方案能解决什么?
业务定制化数据转换同构/异构表数据表迁移
数据分库分表迁移与校验
单机房性能指标
据生产环境迁移情况,内存占用小于2G,迁移14亿数据花费24小时,平均迁移效率约为40w行/分钟
相关文章推荐
- MySQL分库分表单库分表和迁移数据(4th)
- 阿里巴巴去Oracle数据迁移同步工具(全量+增量,目标支持MySQL/DRDS)
- 应用迁移,流量切换,数据切换. mysql 同步. 同构,异构两种情况分析.
- MongoDB在58同城百亿量级数据下的应用实践
- 赶集网CDC案例-蔡峰:赶集网CDC异构数据同步方案实践-IT168 信息化专区
- 数据库分库分表(sharding)系列(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
- 【VMware虚拟化解决方案】vmware P2V迁移同步实践
- 异构存储系统数据迁移步骤分享
- django开发利器:South(数据层同步迁移)
- DSG异构平台零停机业务数据迁移方案及案例
- [置顶] 数据库分库分表(sharding)系列(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
- 物化视图实践(1)----实现远程数据同步
- DSG-Oracle数据库异构平台数据实时迁移解决方案
- 数据库分库分表(sharding)系列(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
- MongoDB远程主从部署下的全量数据同步及故障恢复策略
- 物化视图实践(1)----实现远程数据同步
- mysql 备份与迁移 数据同步方法
- 数据库分表(sharding)系列(五) 一种支持自由规划无须数据迁移和修改路由代码的Sharding扩容方案
- oracle10G 数据库名、实例名、ORACLE_SID 及创建数据库- hl3292转载修改(实践部分待校验)