Caffe源码解读(十):Caffe五种层的实现和参数配置
2017-04-21 01:25
344 查看
以mnist数据集的lenet_train_test.prototxt网络为例介绍
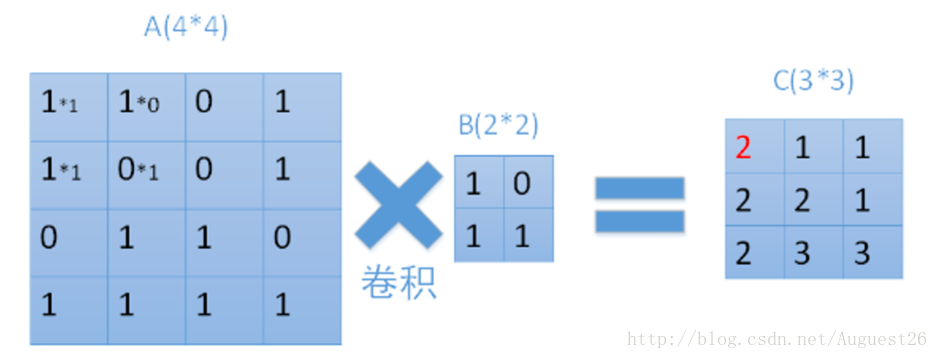
输入为28*28的图像,经过5*5的卷积之后,得到一个(28-5+1)*(28-5+1) = 24*24的map。
map:就是一张图像经过一个卷积核之后的图像
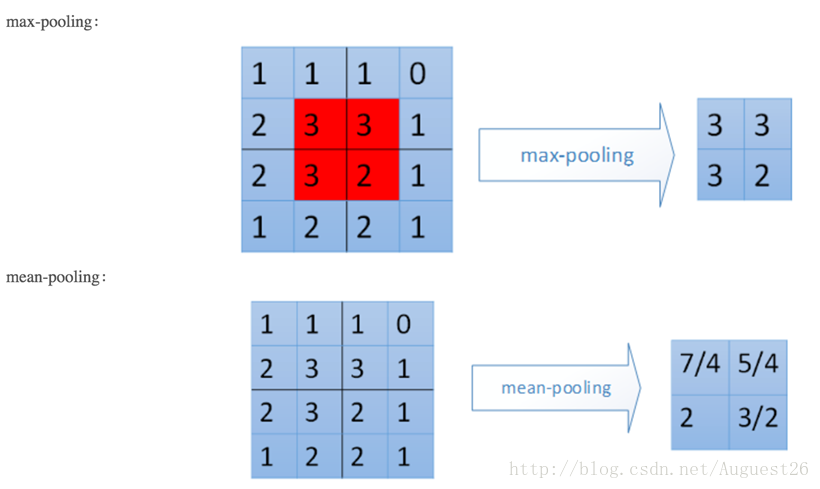
例子:
输入为卷积层1的输出,大小为24*24,对每个不重叠的2*2的区域进行降采样。对于max-pooling,选出每个区域中的最大值作为输出。而对于mean-pooling,需计算每个区域的平均值作为输出。最终,该层输出一个(24/2)*(24/2)的map
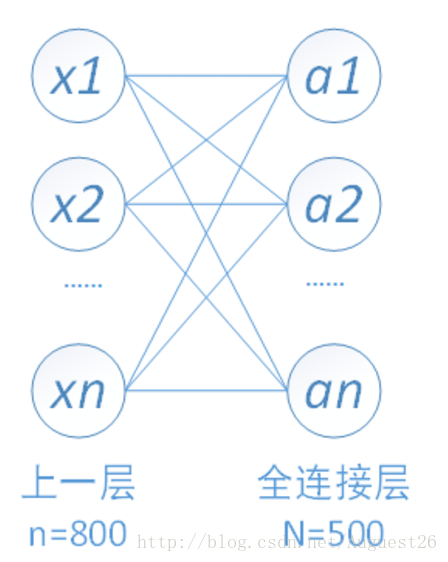
50*4*4=800个输入结点和500个输出结点
激活函数一般具有以下性质:
- 非线性: 线性模型的不足我们前边已经提到。
- 处处可导:反向传播时需要计算激活函数的偏导数,所以要求激活函数除个别点外,处处可导。
- 单调性:当激活函数是单调的时候,单层网络能够保证是凸函数。
- 输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
Softmax公式:
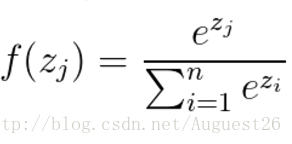
通常情况下softmax会被用在网络中的最后一层,用来进行最后的分类和归一化。
卷积层
输入为28*28的图像,经过5*5的卷积之后,得到一个(28-5+1)*(28-5+1) = 24*24的map。
map:就是一张图像经过一个卷积核之后的图像
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1 #学习率1,和权值更新相关
}
param {
lr_mult: 2 #学习率2,和权值更新相关
}
convolution_param {
num_output: 50 # 50个输出的map
kernel_size: 5 #卷积核大小为5*5
stride: 1 #卷积步长为1
weight_filler { #权值初始化方式
type: “xavier" #默认为"constant",值全为0,很多时候我们也可以用"xavier"或者”gaussian"来进行初始化
}
bias_filler { #偏置值的初始化方式
type: "constant" #该参数的值和weight_filler类似,一般设置为"constant",值全为0
}
}池化层
例子:
输入为卷积层1的输出,大小为24*24,对每个不重叠的2*2的区域进行降采样。对于max-pooling,选出每个区域中的最大值作为输出。而对于mean-pooling,需计算每个区域的平均值作为输出。最终,该层输出一个(24/2)*(24/2)的map
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX #Pool为池化方式,默认值为MAX,可以选择的参数有MAX、AVE、STOCHASTIC
kernel_size: 2 #池化区域的大小,也可以用kernel_h和kernel_w分别设置长和宽
stride: 2 #步长,即每次池化区域左右或上下移动的距离,一般和kernel_size相同,即为不重叠池化。也可以也可以小于kernel_size,即为重叠池化,Alexnet中就用到了重叠池化的方法
}
}全连接层
50*4*4=800个输入结点和500个输出结点
#参数和卷积层表达一样
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}激活函数层
激活函数作用:激活函数是用来引入非线性因素的。激活函数一般具有以下性质:
- 非线性: 线性模型的不足我们前边已经提到。
- 处处可导:反向传播时需要计算激活函数的偏导数,所以要求激活函数除个别点外,处处可导。
- 单调性:当激活函数是单调的时候,单层网络能够保证是凸函数。
- 输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}softmax层
Softmax回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,待分类的类别数量大于2,且类别之间互斥。Softmax公式:
通常情况下softmax会被用在网络中的最后一层,用来进行最后的分类和归一化。

相关文章推荐
- Caffe学习笔记5--Caffe可视化和五种类型的层的实现和参数配置
- caffe中五种层的实现与参数配置(1)------卷积层
- caffe中五种层的实现与参数配置(4)------softmax层
- caffe中五种层的实现与参数配置(3)------激活函数层
- HttpClient 4.3连接池参数配置及源码解读
- 通用权限管理系统组件 (GPM - General Permissions Manager) 中实现系统参数配置保存,附源码
- HttpClient 4.3连接池参数配置及源码解读
- HttpClient 4.3连接池参数配置及源码解读_0
- HttpClient 4.3连接池参数配置及源码解读
- Caffe源码解读(十三):caffe.proto中Layer参数与源代码中Layer的相互关系
- 通用权限管理系统组件 (GPM - General Permissions Manager) 中实现系统参数配置保存,附源码
- HttpClient 4.3连接池参数配置及源码解读
- HttpClient 4.3连接池参数配置及源码解读
- HttpClient 4.3连接池参数配置及源码解读
- 通用权限管理系统组件中实现系统参数配置保存,附源码
- Spring-Transaction 事务配置的五种实现方式
- php源码安装时configure配置参数
- adw launcher源码阅读(一)配置选项实现与sqlite数据库
- FastDFS的配置、部署与API使用解读——设置FastDFS配置参数的两种方式
- Tomcat源码解读系列(一)——server.xml文件的配置