Caffe源码解读(三):Layer类的源码解读
2017-04-16 23:42
501 查看
Layer是Caffe模型的本质内容和执行计算基单元。
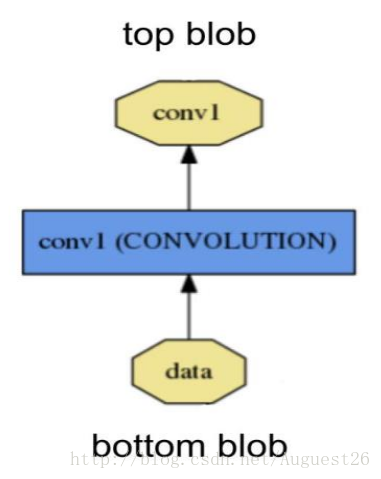
一个 layer 通过 bottom(底部)连接层接收数据,通过 top(顶部)连接层输出数据。
每一个 layer 都定义了 3 种重要的运算:setup(初始化设置),forward(前向传播),backward(反向传播)。
Setup: 在模型初始化时重置 layers 及其相互之间的连接 ;
Forward: 从 bottom 层中接收数据,进行计算后将输出送入到 top 层中;
Backward: 给定相对于 top 层输出的梯度,计算其相对于输入的梯度,并传递到 bottom层。一个有参数的 layer 需要计算相对于各个参数的梯度值并存储在内部。
由于 Caffe 网络的组合性和其代码的模块化,自定义 layer 是很容易的。只要定义好 layer的 setup(初始化设置)、forward(前向通道)和backward(反向通道),就可将 layer 纳入到网络中。
功能:实现一般layer的setup功能。参数bottom用来preshape输入的blobs。参数top用来分配blobs,这些blobs不用shape,shape由Reshape来执行。
功能:虚函数,由自定义的Layer继承并实现,功能类似于SetUp。
功能:根据bottom,计算出top和loss。
bottom:是输入的blobs,它的数据域存储该层的输入数据。
top:经过preshaped的输出的blobs,用来存储该层的输出。
返回值:该层整体loss。
功能:给定相对于 top 层输出的误差梯度,计算其相对于输入的梯度,并传递到 bottom层。一个有参数的 layer 需要计算相对于各个参数的梯度值并存储在内部。
- propagate_down:一个与bottom长度相等的向量,对应的每一个值表示是否把误差梯度向下传递给bottom。
neuron_layer
loss_layer
common_layer
vision_layer
1. DATA 用于LevelDB或LMDB数据格式的输入的类型,输入参数有source, batch_size, (rand_skip), (backend)。后两个是可选。
2. MEMORY_DATA 这种类型可以直接从内存读取数据使用时需要调用MemoryDataLayer::Reset,输入参数有batch_size, channels, height, width。
3. HDF5_DATA HDF5数据格式输入的类型,输入参数有source, batch_size。
4. HDF5_OUTPUT HDF5数据格式输出的类型,输入参数有file_name。
5. IMAGE_DATA 图像格式数据输入的类型,输入参数有source, batch_size, (rand_skip), (shuffle), (new_height), (new_width)。
其实还有两种WINDOW_DATA, DUMMY_DATA用于测试和预留的接口,不重要。
Caffe中实现了大量激活函数GPU和CPU的都有很多。它们的父类都是NeuronLayer
一般的参数设置格式如下(以ReLU修正线性单元为例):
RELU目前使用广泛的激活函数。
声明了9个类型的common_layer,部分有GPU实现:
InnerProductLayer 常常用来作为全连接层
SplitLayer 用于一输入对多输出的场合(对blob)
FlattenLayer 将n * c * h * w变成向量的格式n * ( c * h * w ) * 1 * 1
ConcatLayer 用于多输入一输出的场合
SilenceLayer 用于一输入对多输出的场合(对layer)
(Elementwise Operations) 这里面是我们常说的激活函数层Activation Layers。
EltwiseLayer
SoftmaxLayer
ArgMaxLayer
MVNLayer
ConvolutionLayer 最常用的卷积操作
Im2colLayer 与MATLAB里面的im2col类似,即image-to-column transformation,转换后方便卷积计算
LRNLayer 全称local response normalization layer,在Hinton论文中有详细介绍ImageNet Classification with Deep Convolutional Neural Networks 。
PoolingLayer Pooling操作
作用
Layer可以进行很多运算,如convolve(卷积)、pooling(池化)、inner product(内积),rectified-linear和sigmoid等非线性运算,元素级的数据转换,normalize(归一化)、softmax和hinge等losses(损失计算)。Layer工作原理
一个 layer 通过 bottom(底部)连接层接收数据,通过 top(顶部)连接层输出数据。
每一个 layer 都定义了 3 种重要的运算:setup(初始化设置),forward(前向传播),backward(反向传播)。
Setup: 在模型初始化时重置 layers 及其相互之间的连接 ;
Forward: 从 bottom 层中接收数据,进行计算后将输出送入到 top 层中;
Backward: 给定相对于 top 层输出的梯度,计算其相对于输入的梯度,并传递到 bottom层。一个有参数的 layer 需要计算相对于各个参数的梯度值并存储在内部。
由于 Caffe 网络的组合性和其代码的模块化,自定义 layer 是很容易的。只要定义好 layer的 setup(初始化设置)、forward(前向通道)和backward(反向通道),就可将 layer 纳入到网络中。
Layer成员变量
/** The protobuf that stores the layer parameters */ LayerParameter layer_param_;//caffe.proto中定义了LayerParameter类,定义了它所包含的基本参数 /** The phase: TRAIN or TEST */ Phase phase_;//caffe.proto中定义了枚举型的Phase,值:TRAIN or TEST。 /** The vector that stores the learnable parameters as a set of blobs. */ vector<shared_ptr<Blob<Dtype> > > blobs_; /** Vector indicating whether to compute the diff of each param blob. */ vector<bool> param_propagate_down_; /** The vector that indicates whether each top blob has a non-zero weight in * the objective function. */ vector<Dtype> loss_;
/** Whether this layer is actually shared by other nets*/ bool is_shared_; /** The mutex for sequential forward if this layer is shared */ shared_ptr<boost::mutex> forward_mutex_;
Layer类的成员函数
Layer类常用的成员函数,那些简单易懂的就不列出了。SetUp()
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
InitMutex();
CheckBlobCounts(bottom, top);
LayerSetUp(bottom, top);
Reshape(bottom, top);
SetLossWeights(top);
}功能:实现一般layer的setup功能。参数bottom用来preshape输入的blobs。参数top用来分配blobs,这些blobs不用shape,shape由Reshape来执行。
LayerSetUp()
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {}功能:虚函数,由自定义的Layer继承并实现,功能类似于SetUp。
Forward()
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top);
功能:根据bottom,计算出top和loss。
bottom:是输入的blobs,它的数据域存储该层的输入数据。
top:经过preshaped的输出的blobs,用来存储该层的输出。
返回值:该层整体loss。
Backward()
inline void Backward(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
功能:给定相对于 top 层输出的误差梯度,计算其相对于输入的梯度,并传递到 bottom层。一个有参数的 layer 需要计算相对于各个参数的梯度值并存储在内部。
- propagate_down:一个与bottom长度相等的向量,对应的每一个值表示是否把误差梯度向下传递给bottom。
type()
/**
* @brief Returns the layer type.
*/
virtual inline const char* type() const { return ""; }param_propagate_down()
/**
* @brief Specifies whether the layer should compute gradients w.r.t. a
* parameter at a particular index given by param_id.
*
* You can safely ignore false values and always compute gradients
* for all parameters, but possibly with wasteful computation.
*/
inline bool param_propagate_down(const int param_id) {
return (param_propagate_down_.size() > param_id) ?
param_propagate_down_[param_id] : false;
}Forward_cpu()
/** @brief Using the CPU device, compute the layer output. */ virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) = 0;
Forward_gpu()
/**
* @brief Using the GPU device, compute the layer output.
* Fall back to Forward_cpu() if unavailable.
*/
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
4000
const vector<Blob<Dtype>*>& top) {
// LOG(WARNING) << "Using CPU code as backup.";
return Forward_cpu(bottom, top);
}Backward_cpu()
/** * @brief Using the CPU device, compute the gradients for any parameters and * for the bottom blobs if propagate_down is true. */ virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) = 0;
Backward_gpu()
/**
1. @brief Using the GPU device, compute the gradients for any parameters and
2. for the bottom blobs if propagate_down is true.
3. Fall back to Backward_cpu() if unavailable.
*/
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
// LOG(WARNING) << "Using CPU code as backup.";
Backward_cpu(top, propagate_down, bottom);
}5种主要的衍生类
data_layerneuron_layer
loss_layer
common_layer
vision_layer
data_layer
data_layer主要包含与数据有关的文件。在官方文档中指出data是caffe数据的入口是网络的最低层,并且支持多种格式,在这之中又有5种LayerType:1. DATA 用于LevelDB或LMDB数据格式的输入的类型,输入参数有source, batch_size, (rand_skip), (backend)。后两个是可选。
2. MEMORY_DATA 这种类型可以直接从内存读取数据使用时需要调用MemoryDataLayer::Reset,输入参数有batch_size, channels, height, width。
3. HDF5_DATA HDF5数据格式输入的类型,输入参数有source, batch_size。
4. HDF5_OUTPUT HDF5数据格式输出的类型,输入参数有file_name。
5. IMAGE_DATA 图像格式数据输入的类型,输入参数有source, batch_size, (rand_skip), (shuffle), (new_height), (new_width)。
其实还有两种WINDOW_DATA, DUMMY_DATA用于测试和预留的接口,不重要。
neuron_layer
同样是数据的操作层,neuron_layer实现里大量激活函数,主要是元素级别的操作,具有相同的bottom,top size。Caffe中实现了大量激活函数GPU和CPU的都有很多。它们的父类都是NeuronLayer
template <typename Dtype> class NeuronLayer : public Layer<Dtype>
一般的参数设置格式如下(以ReLU修正线性单元为例):
layers {
name: "relu1"
type: RELU
bottom: "conv1"
top: "conv1"
}RELU目前使用广泛的激活函数。
loss_layer
loss层计算网络误差,loss_layer.hpp头文件中调用了neuron_layers.hpp。估计是需要调用里面的函数计算Loss,一般来说Loss放在最后一层。caffe实现了大量loss function,它们的父类都是LossLayer。template <typename Dtype> class LossLayer : public Layer<Dtype>
common_layer
这一层主要进行的是vision_layer的连接。声明了9个类型的common_layer,部分有GPU实现:
InnerProductLayer 常常用来作为全连接层
SplitLayer 用于一输入对多输出的场合(对blob)
FlattenLayer 将n * c * h * w变成向量的格式n * ( c * h * w ) * 1 * 1
ConcatLayer 用于多输入一输出的场合
SilenceLayer 用于一输入对多输出的场合(对layer)
(Elementwise Operations) 这里面是我们常说的激活函数层Activation Layers。
EltwiseLayer
SoftmaxLayer
ArgMaxLayer
MVNLayer
vision_layer
主要是实现Convolution和Pooling操作, 主要有以下几个类:ConvolutionLayer 最常用的卷积操作
Im2colLayer 与MATLAB里面的im2col类似,即image-to-column transformation,转换后方便卷积计算
LRNLayer 全称local response normalization layer,在Hinton论文中有详细介绍ImageNet Classification with Deep Convolutional Neural Networks 。
PoolingLayer Pooling操作

相关文章推荐
- caffe之classification.cpp 接口源码解读
- Caffe源码解读: Softmax_loss_Layer的前向与反向传播
- Caffe源码解读(九):Caffe可视化工具
- Caffe源码解读(十三):caffe.proto中Layer参数与源代码中Layer的相互关系
- caffe源码解读(10)-hinge_loss_layer.cpp
- 【转】SSD的caffe源码解读 -- 数据增强
- caffe 源码的解读(2)DataStructure
- caffe源码解读(1)-softmax_loss_layer.cpp
- caffe源码解读(6)-数据读取层DataLayer
- caffe源码解读(2)-center_loss_layer.cpp
- Caffe源码解读前言
- caffe源码解读(9)-euclidean_loss_layer.cpp
- caffe源码解读(13)-blob.hpp
- caffe 分类源码解读
- Caffe源码解读:lrn_layer层原理
- Caffe源码解读(二):caffe.proto(下)
- Caffe源码解读(二):Blob类的源码解读
- Caffe源码解读(一):caffe.proto(上)
- Caffe源码解读:conv_layer的前向传播与反向传播
- caffe源码解读(4)-concate_layer.cpp以及slice_layer.cpp