neural network for machine learning(by Geoffrey Hinton)lecture1--几种常见的激活函数
2017-04-10 14:52
501 查看
neural network for machine learning(by Geoffrey Hinton)lecture1--几种常见的激活函数
看了Hinton大神在第一周的lecture1中的讲的几种激活函数,自己又搜集了一些资料,因此整理成一篇博客,一来相当于笔记方便自己查看,二来也供各位程序猿参考。在介绍激活函数之前,先看下一个最基本的神经元模型,这个模型在以前的关于神经网络的博客中也写过(http://blog.csdn.net/u012328159/article/details/51143536),具体的可以看下这篇博客,现在只贴个图大家有个直观的感受就可以。
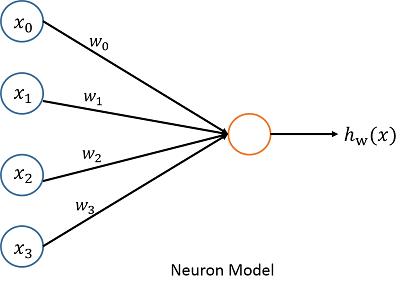
常见的激活函数主要有linear neurons、binary threshold neurons、sigmoid neurons、TanH、[b]rectified linear neurons、Leaky-ReLU、Maxout等。下面来分别详细的介绍这几个激活函数:[/b]
1、linear neurons:
linear neurons可以表示为:
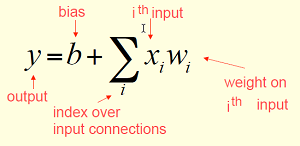
2、[b]binary threshold neurons:[/b]
[b] binary threshold neurons可以表示为:
[/b]
[b]
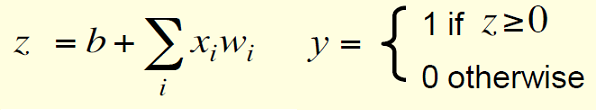
[/b]
[b] 其图像为:[/b]
[b]

[/b]
3、sigmoid neurons:
Sigmoid激活函数为:
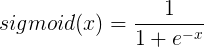
其图像为:
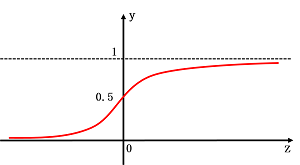
阈值型函数具有不连续、不光滑的不好性质,Sigmoid函数可以把较大范围内的输入值挤压到(0,1)输出范围内,因此有时候称为“挤压函数”。以前sigmoid激活函数很常用,现在已经不常用了,因为它主要有以下缺点(摘自 我爱机器学习,CS231n课程笔记翻译:神经网络笔记1(上),链接为:link)
Sigmoid函数饱和使梯度消失。sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。回忆一下,在反向传播的时候,这个(局部)梯度将会与整个损失函数关于该门单元输出的梯度相乘。因此,如果局部梯度非常小,那么相乘的结果也会接近零,这会有效地“杀死”梯度,几乎就有没有信号通过神经元传到权重再到数据了。还有,为了防止饱和,必须对于权重矩阵初始化特别留意。比如,如果初始化权重过大,那么大多数神经元将会饱和,导致网络就几乎不学习了。
Sigmoid函数的输出不是零中心的。这个性质并不是我们想要的,因为在神经网络后面层中的神经元得到的数据将不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数(比如在f=w^Tx+b中每个元素都x>0),那么关于w的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数(具体依整个表达式f而定)。这将会导致梯度下降权重更新时出现z字型的下降。然而,可以看到整个批量的数据的梯度被加起来后,对于权重的最终更新将会有不同的正负,这样就从一定程度上减轻了这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
4、TanH
TanH激活函数可表示为:
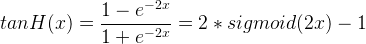
其图像为:
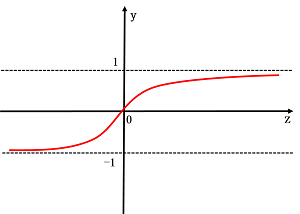
TanH激活函数可以将输入挤压到(-1,1)的范围内输出,这样它的输出就是以0为中心的,但它依然存在饱和问题。其实TanH函数就是Sigmoid函数的放大,
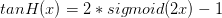
。在实际操作中,tanh非线性函数比sigmoid非线性函数更受欢迎。
[b]5、rectified linear neurons(ReLU)
[/b]
[b]ReLU激活函数可被表示为:[/b]
[b]
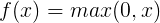
[/b]
[b]其图像为:[/b]
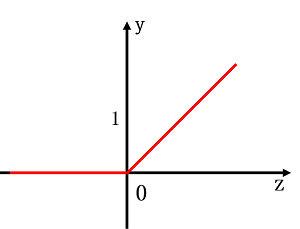
现在,ReLU激活函数很流行,很常用。RLU函数主要有以下优缺点:(摘自 我爱机器学习,CS231n课程笔记翻译:神经网络笔记1(上),链接为:link)
优点:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用( Krizhevsky 等的论文指出有6倍之多)。据称这是由它的线性,非饱和的公式导致的。
优点:sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
缺点:在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
6、Leaky-ReLU:
Leaky-ReLU从名字上应该也可以看出是从ReLU衍生出来的,主要是为了克服ReLU的缺点。Leaky-ReLU可表示为:
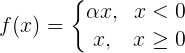
其中
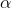
通常是一个非常小的实数,但关于其效果有的说很好,有的说不好。尚无明确的定论。
7、Maxout
Maxout是Goodfellow在13年的ICML上发表的论文中提出的,有兴趣的可以去看这篇论文link。其可以表示为:
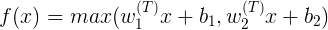
ReLU和Leaky-ReLU都是这个公式的特殊情况(比如ReLU就是当w_1,b_1=0的时候)。这样Maxout神经元就拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)。然而和ReLU对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。([b]摘自
我爱机器学习,CS231n课程笔记翻译:神经网络笔记1(上),链接为:link)
[/b]
以上就是一些常见的激活函数。至于在实践中该如何选择激活函数呢?
一般可以使用 ReLU,但是一定要设置好learning rate,不要让你的网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
现在基本不会再用sigmoid了,可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
通常来说,很少会把各种激活函数串起来在一个网络中使用的。
最后附上一个hinton课堂上关于激活函数的题目,供大家参考:


相关文章推荐
- Neural Networks for Machine Learning by Geoffrey Hinton (1~2)
- Neural Networks for Machine Learning by Geoffrey Hinton (5)
- Neural Networks for Machine Learning by Geoffrey Hinton (6)
- Neural Networks for Machine Learning by Geoffrey Hinton (4)
- Neural Networks for Machine Learning by Geoffrey Hinton (4)
- Neural Networks for Machine Learning by Geoffrey Hinton (7)序列建模与RNN
- Neural Networks for Machine Learning by Geoffrey Hinton (3)
- Neural Networks for Machine Learning by Geoffrey Hinton (1~2)
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 1 Quiz
- Machine Learning by Andrew Ng --- neural network learning
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 12 Quiz
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 3 Quiz
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 7 Quiz
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 2 Quiz
- 【深度学习】论文导读:ELU激活函数的提出(FAST AND ACCURATE DEEP NETWORK LEARNING BY EXPONENTIAL LINEAR UNITS (ELUS))
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 11 Quiz
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 13 Quiz
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 15 Quiz
- 机器学习中的神经网络Neural Networks for Machine Learning:Lecture 4 Quiz
- neural network for machine learning(第三周编程作业)----感知机算法