Neural Networks for Machine Learning by Geoffrey Hinton (5)
2015-08-25 12:15
561 查看
为什么物体识别很困难
获得视角不变性的方法
不变特征方法The invariant feature approach
合理归一化方法The judicious normalization approach
强制归一化方法The brute force normalization approach
用以手写体识别的卷积神经网络
复制特征方法The replicated feature approach
复制特征方法学习到了什么
复制特征提取器的池化Pooling
LeNet5 模型
如何评价两个模型的优劣
Alexs Net 的诸多设计
物体光照(Lighting):像素的值被物体光照所显著影响。
图像变形(Deformation):物体有时会变形成非仿射(non-affine)的形式。
情景支持(Affordances):物体所属类别常常由他们的使用方式而定义。如各种能坐的物体都可以是算是椅子。
维度跳变(dimension-hopping):
具体表现是:改变视角(viewpoint)可能导致机器学习方法失效,如图1。
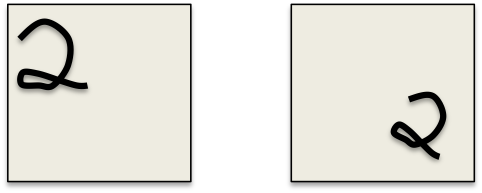
图1
形象的比喻是:网络用来学习病人的各种体征,之前用来学习身高的神经元,现在忽然用来学习病人的年龄。
在物体外侧画一个边框,然后对其进行归一化(Normalization)。
使用复制特征(replicated features)以及池化(pooling)技巧。
例如:在红点周围的两根粗平行线。如图2。

图2
当时对于识别任务而言,应当尽量避免不属于物体的部分的特征。
边框对相当多的变形具有不变性:如平移、旋转、放大、剪切以及拉伸。

图3
然而选取边框非常困难,因为:
分割错误、遮挡、反常定位。
因此我们需要识别出物体才能更好对边框进行定位——这变成了鸡与蛋的问题。
测试识别器的时候用各种位置和朝向的边框。
这种方法对检测未经裁切的竖直物体如脸部、门牌号码这些任务很有效。
复制特征的方法显著降低了自由参数的数量。
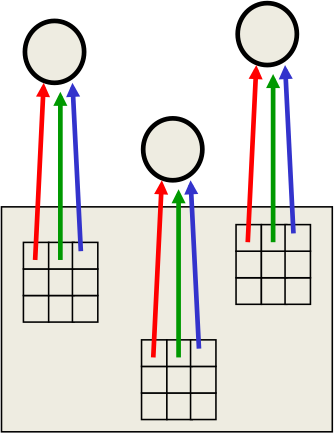
图4
复制特征的方法并不能使神经元激活值不变,但是能够使激活值改变量相同,如图5。

图5
知识不变量
如果在训练中某个特征在一些位置有效,那么在测试中,特征提取器应该在各个位置生效。
这会降低输入到下一层的输入特征数,从而使得下一层实际能学到特征变多了。
存在的问题:经过若干层的池化,我们损失了 物体的精确位置信息。
这使得利用物体之间的精确空间位置关系来进行识别变得不可行。
LENET
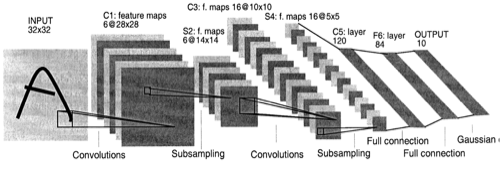
图6
说明模型2要显著好于模型1。
并不能说明模型2要好于模型1。
7层隐含层(不包括池化层)。
前面5层是卷积层,后面2层是全连接层。
激活函数使用的是ReLU函数。
归一化层用以抑制近邻神经元的强激活值。
随机裁切和水平镜像以扩大训练数据集。
丢弃层(Dropout)随机丢弃一半权重以防止过拟合。
双GPU(GTX 580)矩阵运算。
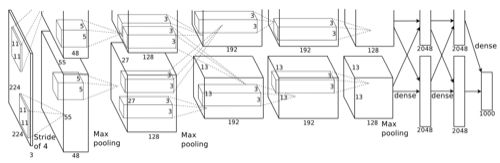
图7
获得视角不变性的方法
不变特征方法The invariant feature approach
合理归一化方法The judicious normalization approach
强制归一化方法The brute force normalization approach
用以手写体识别的卷积神经网络
复制特征方法The replicated feature approach
复制特征方法学习到了什么
复制特征提取器的池化Pooling
LeNet5 模型
如何评价两个模型的优劣
Alexs Net 的诸多设计
为什么物体识别很困难?
图像分割(Segmentation):实际场景中总是掺杂着其他物体。物体光照(Lighting):像素的值被物体光照所显著影响。
图像变形(Deformation):物体有时会变形成非仿射(non-affine)的形式。
情景支持(Affordances):物体所属类别常常由他们的使用方式而定义。如各种能坐的物体都可以是算是椅子。
维度跳变(dimension-hopping):
具体表现是:改变视角(viewpoint)可能导致机器学习方法失效,如图1。
图1
形象的比喻是:网络用来学习病人的各种体征,之前用来学习身高的神经元,现在忽然用来学习病人的年龄。
获得视角不变性的方法
使用充足冗余的不变性特征(redundant invariant features)。在物体外侧画一个边框,然后对其进行归一化(Normalization)。
使用复制特征(replicated features)以及池化(pooling)技巧。
不变特征方法(The invariant feature approach)
提取一个巨大、冗余的特征集合,这个集合对于变换具有不变性。例如:在红点周围的两根粗平行线。如图2。
图2
当时对于识别任务而言,应当尽量避免不属于物体的部分的特征。
合理归一化方法(The judicious normalization approach)
在物体周围放置一个边框,并定位方向,从而进行归一化。如图3。边框对相当多的变形具有不变性:如平移、旋转、放大、剪切以及拉伸。
图3
然而选取边框非常困难,因为:
分割错误、遮挡、反常定位。
因此我们需要识别出物体才能更好对边框进行定位——这变成了鸡与蛋的问题。
强制归一化方法(The brute force normalization approach)
训练识别器的时候用良好裁切,方向竖直向上、贴合边框的图片。测试识别器的时候用各种位置和朝向的边框。
这种方法对检测未经裁切的竖直物体如脸部、门牌号码这些任务很有效。
用以手写体识别的卷积神经网络
复制特征方法(The replicated feature approach)
在不同的位置使用相同的特征提取器,如图4。复制特征的方法显著降低了自由参数的数量。
图4
复制特征方法学习到了什么?
激活值等变化量复制特征的方法并不能使神经元激活值不变,但是能够使激活值改变量相同,如图5。
图5
知识不变量
如果在训练中某个特征在一些位置有效,那么在测试中,特征提取器应该在各个位置生效。
复制特征提取器的池化(Pooling)
池化就是把相邻的像素值均值化,作为下一层网络的单一输入。这会降低输入到下一层的输入特征数,从而使得下一层实际能学到特征变多了。
存在的问题:经过若干层的池化,我们损失了 物体的精确位置信息。
这使得利用物体之间的精确空间位置关系来进行识别变得不可行。
LeNet5 模型
Yann LeCun 开发了一个多层卷积神经网络用于手写体识别,如图6:LENET
图6
如何评价两个模型的优劣?
McNemar 测试比单纯地比较两个模型的错误率要更加可观。| type | model 1 wrong | model 1 right |
|---|---|---|
| model 2 wrong | 29 | 1 |
| model 2 right | 11 | 9959 |
| type | model 1 wrong | model 1 right |
|---|---|---|
| model 2 wrong | 15 | 15 |
| model 2 right | 25 | 9949 |
Alex’s Net 的诸多设计
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.7层隐含层(不包括池化层)。
前面5层是卷积层,后面2层是全连接层。
激活函数使用的是ReLU函数。
归一化层用以抑制近邻神经元的强激活值。
随机裁切和水平镜像以扩大训练数据集。
丢弃层(Dropout)随机丢弃一半权重以防止过拟合。
双GPU(GTX 580)矩阵运算。
图7

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- bp神经网络及matlab实现
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 治安卡口方案
- 模式识别
- 基于神经网络的预测模型
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 关于机器学习的学习笔记(二):决策树算法
- 关于机器学习的学习笔记(三):k近邻算法
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐