ambari 搭建hadoop大数据平台系列2-客户机配置
2017-04-04 17:10
369 查看
本案例搭建的环境介绍如下:Ambari 2.4.2 + HDP 2.5 (hadoop 2.7 ;hive 1.2 ;Tez ;Spark 2.0)+jdk1.8.25 +centos7.0,这里首先要关注些注意事项,至于为什么会一一说明。
第一部分:注意事项:
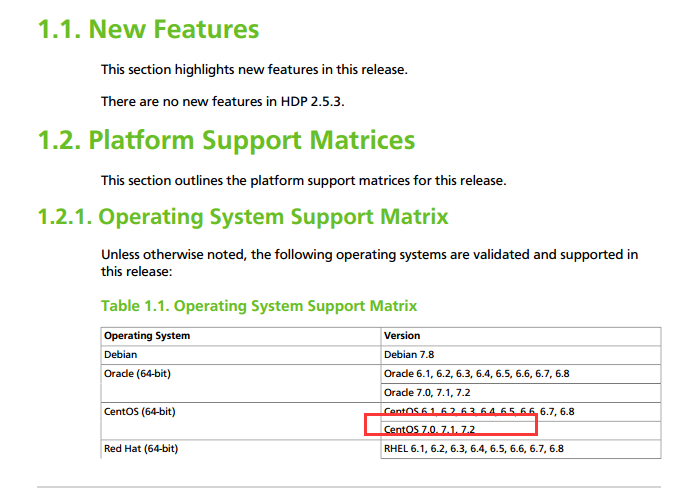
1:版本必须低于7.2,这里踩了个大坑,刚开始选用了7.3,最后发现经常莫名其妙的异常,经常安装失败。后来从官方查到(没有放在最显眼的位置说明):
2. 127.0.0.1 hosts该条记录删除 ,这也是在埋坑过后 发现的
3.本地仓库必须搭建 ,如果不搭建本地仓库,太痛苦了。下载过程巨慢,而且每次重新来的时候,巨费时间。
4.root 账户ssh 启用 这个我也考虑过使用专门账户,虽然ambari 也支持该功能,但是需要做相应的很多更改,如果是测试机版本,还是便捷点比较好,后期可以通过ambari 的相关安全策略来补上。
5.其他的几项注意事项,大家一看就懂的,不过还是得细心检查比较好。否则后面的拍错过程会费掉很多精力
第二部分:开始配置客户端及ambari-server
1.集群端机器分配如下:
2.检查 centos 版本,关闭selinux ,firewalld , 添加hosts 记录,安装jdk1.8,
检查时区和时间是否统一
yum install ntp
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
配置root ssh 登陆
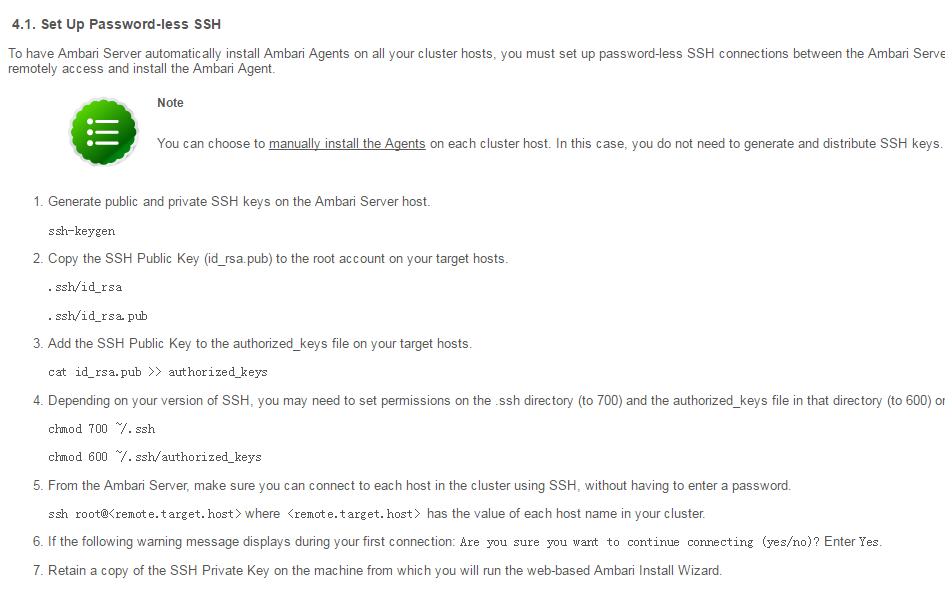
配置jdk1.8.025 ,将jdk 解压到/usr/local/java/jdk1.8.0_112目录:
/etc/profile 文件末尾添加
#add jdk-8u112
##add for jdk
export JAVA_HOME=/usr/local/java/jdk1.8.0_112
export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
配置hosts 文件
cat /etc/hosts
10.1.11.32 localRepository-11-32
10.1.11.10 ambari-11-10
10.1.11.1 hadoop11-1
10.1.11.2 hadoop11-2
10.1.11.3 hadoop11-3
10.1.11.4 hadoop11-4
10.1.11.5 hadoop11-5
10.1.11.6 hadoop11-6
10.1.11.7 hadoop11-7
如上,客户机的相关准备工作已经都检查完毕。下一步骤,先搭建本地仓库,以便下载。
第一部分:注意事项:
| 版本必须低于7.2 |
| selinux 必须关闭 |
| firewalld 必须关闭 |
| 127.0.0.1 hosts该条记录删除 |
| 本地仓库必须搭建 |
| root 账户ssh 启用 |
| 指定hdfs data 目录 |
| 安装jdk1.8.0 |
| 所有机器时间必须同步 |
2. 127.0.0.1 hosts该条记录删除 ,这也是在埋坑过后 发现的
3.本地仓库必须搭建 ,如果不搭建本地仓库,太痛苦了。下载过程巨慢,而且每次重新来的时候,巨费时间。
4.root 账户ssh 启用 这个我也考虑过使用专门账户,虽然ambari 也支持该功能,但是需要做相应的很多更改,如果是测试机版本,还是便捷点比较好,后期可以通过ambari 的相关安全策略来补上。
5.其他的几项注意事项,大家一看就懂的,不过还是得细心检查比较好。否则后面的拍错过程会费掉很多精力
第二部分:开始配置客户端及ambari-server
1.集群端机器分配如下:
| centos7.0 | 10.1.11.1 | hadoop11-1 |
| centos7.0 | 10.1.11.2 | hadoop11-2 |
| centos7.0 | 10.1.11.3 | hadoop11-3 |
| centos7.0 | 10.1.11.4 | hadoop11-4 |
| centos7.0 | 10.1.11.5 | hadoop11-5 |
| centos7.0 | 10.1.11.6 | hadoop11-6 |
| centos7.0 | 10.1.11.7 | hadoop11-7 |
检查时区和时间是否统一
yum install ntp
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
配置root ssh 登陆
配置jdk1.8.025 ,将jdk 解压到/usr/local/java/jdk1.8.0_112目录:
/etc/profile 文件末尾添加
#add jdk-8u112
##add for jdk
export JAVA_HOME=/usr/local/java/jdk1.8.0_112
export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
配置hosts 文件
cat /etc/hosts
10.1.11.32 localRepository-11-32
10.1.11.10 ambari-11-10
10.1.11.1 hadoop11-1
10.1.11.2 hadoop11-2
10.1.11.3 hadoop11-3
10.1.11.4 hadoop11-4
10.1.11.5 hadoop11-5
10.1.11.6 hadoop11-6
10.1.11.7 hadoop11-7
如上,客户机的相关准备工作已经都检查完毕。下一步骤,先搭建本地仓库,以便下载。

相关文章推荐
- ambari 搭建hadoop大数据平台系列4-配置ambari-server
- ambari 搭建hadoop大数据平台系列6-验证测试
- ambari 搭建hadoop大数据平台系列1-概述
- ambari 搭建hadoop大数据平台系列3-搭建本地仓库
- 电商用户行为分析大数据平台相关系列2-HADOOP环境搭建
- 大数据系列(1)——Hadoop集群坏境搭建配置
- Hadoop平台搭建使用系列教程(5)- 网络以及初始统一环境配置
- Hadoop平台搭建使用系列教程(5)- 网络以及初始统一环境配置
- win7(64位)平台下Cygwin+Eclipse搭建Hadoop单机开发环境 (一) Cygwin(64位)的安装 + ssh的配置
- Hadoop平台搭建使用系列教程(7)- SSH无密码验证
- Puppet系列之二:自动化配置管理平台的搭建
- hadoop平台搭建(2)--jdk的安装及配置
- Hadoop平台搭建使用系列教程(6)- JDK的安装
- Hadoop平台搭建使用系列教程(4)-操作系统安装
- Hadoop平台搭建使用系列教程(1)-资源目录
- hadoop平台搭建(3)--hadoop安装、环境配置、单机运行
- Hadoop平台搭建使用系列教程(终)- 致歉与全部发布
- Hadoop平台搭建使用系列教程(7)- SSH无密码验证
- Linux下单机版hadoop平台搭建与配置
- hadoop 安装 配置 平台搭建