Python 学习笔记 - 正则表达式模块
2017-04-01 00:00
477 查看
在Python里面,处理字符串除了基本的split,格式化操作等等,还可以使用正则表达式。使用正则表达式,需要导入模块re。正则本身也是一门语言,像下围棋一样,入门很容易,不过要玩的很溜就得花时间了。
老实说,老男孩13期的正则表达式的视频真的很烂,那个讲课的估计是个新人,说话颠三倒四,逻辑混乱,豆子听完还是稀里糊涂。
课后在网上找到一篇强文
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
拜读之后,受益匪浅。
基本规则如下所示:
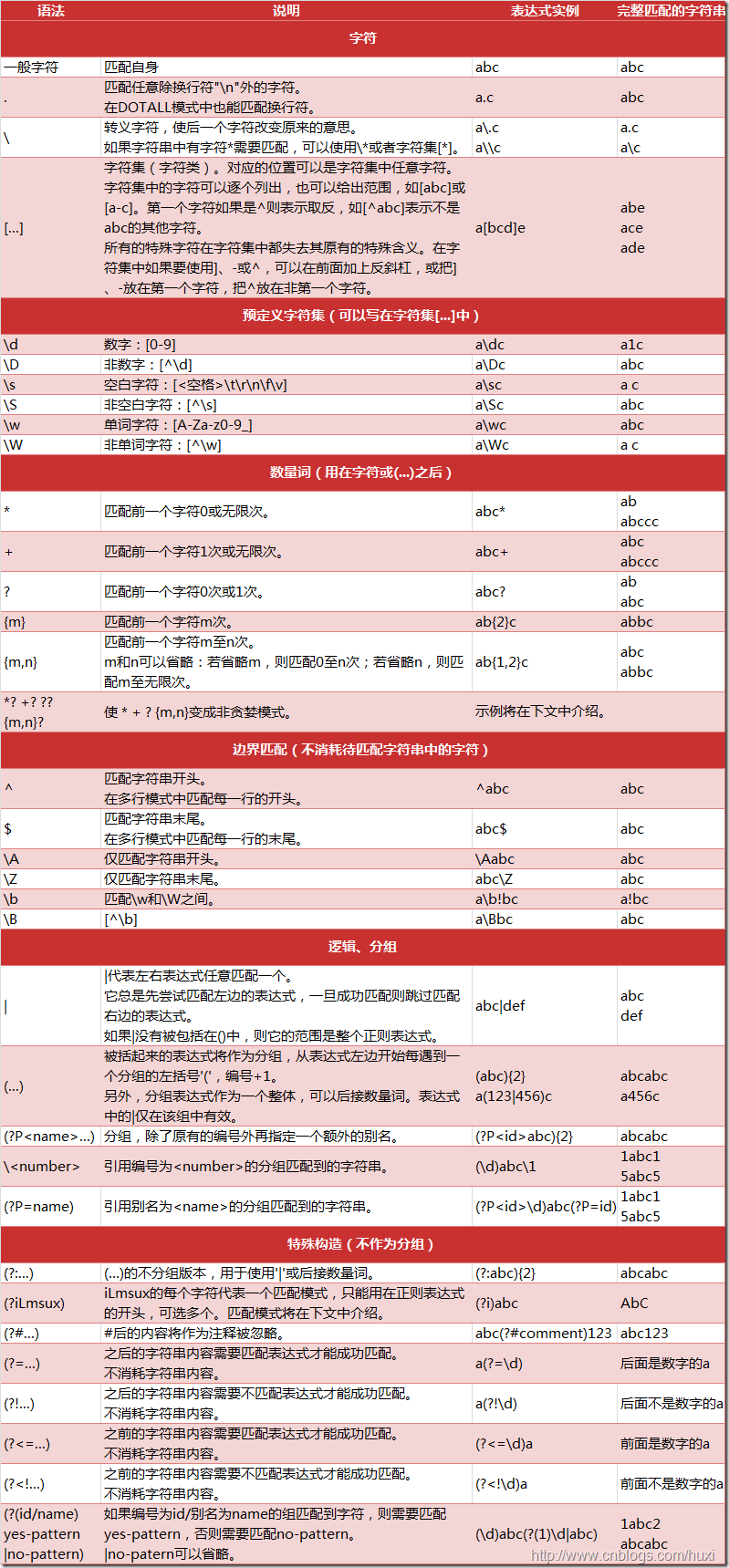
re模块有下面几个常用的函数
1. findall(pattern,string,flags=0),这个函数会返回一个列表,列表的元素是匹配到的字符串
例1,下面会匹配出以a开头的所有单词,\w+表示一个或者多个字母数字或者下划线,因为不包括空格,所以相当于单个的单词了
例2,在字符集里面的元素可以表示或的意义。字符集里面特殊的字符会失去意义;但是他本身有2个特殊的字符,-表示范围,^表示取反,比如说我需要查找加减乘除的符号,那么-因为有特殊含义,因此需要用转移符\转义
2. search(pattern,string,flags)会通过pattern去匹配,如果匹配成功,会返回一个match对象,否则返回None。然后可以通过group()函数获取对象里面的字符串
例3
3. match(pattern,string,flags)会通过pattern去匹配,如果匹配成功,会返回一个match对象,否则返回None。然后可以通过group()函数获取对象里面的字符串。他和search的区别在于match只能匹配字符串开头的字符,后面的无法匹配;而search可以匹配到任意位置的字符串。
例4
4.finditer(pattern,string,flags) 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
例5,我希望匹配一个括号内的四则运算
注意他们的区别,search和match都返回了match对象,然后可以通过group获取字符串;而findall返回的是列表,因为我使用了圆括号分组,因此他会返回圆括号里面的内容;如何获取所有的内容呢,可以通过 finditer,他相当于一个加强版的search,会找到所有match对象放入一个列表,我们可以循环这个列表然后获取每个元素的group内容。
5.sub(pattern,repl,string,count=0,flags=0)
用于替换匹配的字符串
例6 替换2次
6.split(pattern,string,maxsplit=0,flags=0)
除了上面的基本使用之外,还有几点需要注意。
*转移符\的使用,Python本身有转移符,在Re模块中也有转移符,因此,如果在Re里要匹配一个字符\,需要使用\\\\四次,首先Python转移为\\进入Re,然后Re再转义成\;一个简单的方法是使用原生字符r,这样\\就行了。
例7
正则里面还有有一个概念叫做分组。简单的说,分组就是在已经匹配获取的结果里面继续划分新的子集。
在search和match里面,group代表的是获取通过pattern匹配出来的结果;groups表示分组之后的结果;groupdic同样表示分组之后的结果,不过他需要通过P?指定名字才能显示出来
例8
在findall里面分组比较特殊,如果有分组,那么他直接就显示出分组之后的子集,而不是匹配到的字符串
例9 首先匹配到['1hh','2kll']然后分组获取数字后面部分
sub就是替换,不存在分组
split的分组如下所示
例10,对比一下不分组和分组的差别,前者分割之后不会出现分隔符,后者会显示出来
最后补充一下,正则表达式的函数除了可以直接使用re.search,re.match等形式,还可以先编译一个pattern,然后通过pattern来调用这些函数
例11 先编译一次正则表达式,然后再通过编译后的pattern来调用,这样如果调用的地方很多,可以节省一下资源
登录乐搏学院官网http://www.learnbo.com/
或关注我们的官方微博微信,还有更多惊喜哦~

本文出自 “麻婆豆腐” 博客,请务必保留此出处http://beanxyz.blog.51cto.com/5570417/1852180
老实说,老男孩13期的正则表达式的视频真的很烂,那个讲课的估计是个新人,说话颠三倒四,逻辑混乱,豆子听完还是稀里糊涂。
课后在网上找到一篇强文
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
拜读之后,受益匪浅。
基本规则如下所示:
re模块有下面几个常用的函数
1. findall(pattern,string,flags=0),这个函数会返回一个列表,列表的元素是匹配到的字符串
例1,下面会匹配出以a开头的所有单词,\w+表示一个或者多个字母数字或者下划线,因为不包括空格,所以相当于单个的单词了
| 1 2 3 4 | >>> import re ret = re.findall( 'a\w+' , 'abc aaa bbh kjk hkk add' ) (ret) [ 'abc' , 'aaa' , 'add' ] |
| 1 2 3 4 | >>> import re a = re.findall( '[+\-*/]\d' , '3+3-2*4/2' ) (a) [ '+3' , '-2' , '*4' , '/2' ] |
例3
| 1 2 3 4 5 6 | >>> import re obj = re.search( '\d+' , '123uuasf' ) if obj: (obj.group()) - - - - - - - - - - - - - 123 |
例4
| 1 2 3 4 5 6 | import re obj = re.match( '\d+' , 'u123uu888asf' ) if obj: (obj.group()) - - - - - - - - - - - - - 123 |
例5,我希望匹配一个括号内的四则运算
注意他们的区别,search和match都返回了match对象,然后可以通过group获取字符串;而findall返回的是列表,因为我使用了圆括号分组,因此他会返回圆括号里面的内容;如何获取所有的内容呢,可以通过 finditer,他相当于一个加强版的search,会找到所有match对象放入一个列表,我们可以循环这个列表然后获取每个元素的group内容。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | >>>a = re.match( '\(([+\-*/]?\d+\.?\d*){1,}\)', '(-3.2)-2*2+(2-3*(22-3*3))' ) (a.group()) ( 'search' .center( 40 , '-' )) a = re.search( '\(([+\-*/]?\d+\.?\d*){1,}\)', '2-(3*(2.2-3*3))' ) (a.group()) ( 'findall' .center( 40 , '-' )) a = re.findall( '\(([+\-*/]?\d+\.?\d*){1,}\)', '(-3.2)-2*2+(2-3*(22-3*3))' ) for item in a: (item) ( 'finditer' .center( 40 , '-' )) a = re.finditer( '\(([+\-*/]?\d+\.?\d*){1,}\)', '(-3.2)-2*2+(2-3*(22-3*3))' ) for item in a: (item.group()) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ( - 3.2 ) - - - - - - - - - - - - - - - - - search - - - - - - - - - - - - - - - - - ( 2.2 - 3 * 3 ) - - - - - - - - - - - - - - - - findall - - - - - - - - - - - - - - - - - - 3.2 * 3 - - - - - - - - - - - - - - - - finditer - - - - - - - - - - - - - - - - ( - 3.2 ) ( 22 - 3 * 3 ) |
用于替换匹配的字符串
例6 替换2次
| 1 2 3 | >>>ss = 'one,two,three' (re.sub( '\w+' , 'AAA' ,ss, 2 )) AAA,AAA,three |
| 1 2 3 4 | >>>a = 'i am ha happy man' (re.split( 'am' ,a)) - - - - - - - - - - - - - - - - - [ 'i ' , ' ha happy man' ] |
*转移符\的使用,Python本身有转移符,在Re模块中也有转移符,因此,如果在Re里要匹配一个字符\,需要使用\\\\四次,首先Python转移为\\进入Re,然后Re再转义成\;一个简单的方法是使用原生字符r,这样\\就行了。
例7
| 1 2 3 4 5 6 | >>>a = re.findall( '\\\\',' \sabc') (a) b = re.findall(r '\\',' \sjkll') (b) [ '\\' ] [ '\\' ] |
在search和match里面,group代表的是获取通过pattern匹配出来的结果;groups表示分组之后的结果;groupdic同样表示分组之后的结果,不过他需要通过P?指定名字才能显示出来
例8
| 1 2 3 4 5 6 7 8 9 | import re a = re.search( 'h(?P<name>\w+)' , 'hello 123a hoo bc333' ) (a.group()) (a.groups()) (a.groupdict()) - - - - - - - - - - - - - - - - hello ( 'ello' ,) {'name' : 'ello' } |
例9 首先匹配到['1hh','2kll']然后分组获取数字后面部分
| 1 2 3 4 | >>> import re a = re.findall( '\d(\w+)' , '1hh jjkl2 hhs 2kll' ) (a) [ 'hh' , 'kll' ] |
split的分组如下所示
例10,对比一下不分组和分组的差别,前者分割之后不会出现分隔符,后者会显示出来
| 1 2 3 4 5 6 7 | >>>a = 'i am ha happy man' (re.split( 'am' ,a)) a = 'i am ha happy man' (re.split( '(am)' ,a)) - - - - - - - - - - - - - - - - [ 'i ' , ' ha happy man' ] [ 'i ' , 'am' , ' ha happy man' ] |
例11 先编译一次正则表达式,然后再通过编译后的pattern来调用,这样如果调用的地方很多,可以节省一下资源
| 1 2 3 4 5 6 7 | >>> import re >>>p = re. compile (r '\b\w+\b' ) >>>match = p.search( 'jkl jkljl 23jk4 kjl2' ) >>> (match.group()) jkl >>>p.findall( 'jkl kls 234lkjk23 23lk ' ) [ 'jkl' , 'kls' , '234lkjk23' , '23lk' ] |
或关注我们的官方微博微信,还有更多惊喜哦~
本文出自 “麻婆豆腐” 博客,请务必保留此出处http://beanxyz.blog.51cto.com/5570417/1852180

相关文章推荐
- Python学习笔记6-Python中re(正则表达式)模块学习
- Python学习笔记--正则表达式,re模块
- Python学习笔记6-Python中re(正则表达式)模块学习
- Python学习笔记6-Python中re(正则表达式)模块学习
- Python学习笔记6-Python中re(正则表达式)模块学习
- Python 学习笔记(三):文件,高级特性,枚举,正则表达式,模块
- [学习笔记]python之re模块-----正则表达式
- python学习笔记正则表达式re模块
- Python的re(正则表达式)模块学习笔记
- 基于python的正则表达式学习笔记
- Python中re(正则表达式)模块学习
- Python 之 【re模块的正则表达式学习】
- Python模块学习 ---- re 正则表达式
- Python 学习笔记 (5)—— 正则表达式
- Python中re(正则表达式)模块学习
- Python中re(正则表达式)模块学习
- Python模块学习 ---- re 正则表达式
- Python笔记(8)re模块,正则表达式
- Python中re(正则表达式)模块学习
- python 学习笔记(5)用户自定义类正则表达式