机器学习之分类模型的性能度量
2017-03-20 16:31
344 查看
在建立分类器之后,要评价分类器的泛化能力,即分类器在测试集上的分类能力。这时需要一些评价标准,及分类器的性能度量。
其中第一行1和0代表预测的结果,第一列的1和0代表真实数据的标签
预测结果可分为两类,正确(T)和不正确(F),其中正确又分为TP和TN,不正确分为FP和FN
TP:真阳性,实际情况为1,分类结果也为1,分类正确,且均为阳性
TN:真阴性,真实情况为0,预测结果为0,分类正确,且均为阴性
FP:真实情况为0,预测结果为1,分类错误,是假的阳性
FN:真实情况为1,分类结果为0,分类错误,是假的阴性
a+b:真实数据标签为1的个数
c+d:真实数据中标签为0的个数
a+c:预测结果中标签为1的个数
b+d:预测聚过中标签为0的个数
a+b+c+d:总共样本的个数
此时,将样本数量较少的标签设为1,一般只关心这一类的准确率。例如在癌症预测是,将患癌症设为1。
查准率(precision):P=a/(a+c),预测结果为1的样本数占总共预测结果为1的比例,如癌症的例子,查准率是被确诊为癌症的患者中,真正的患者得比例。假如有1000(a+b+c+d)个人就医,我们判断其中20(a+c)个有癌症,这20个患者中真正患癌症的有15(a)个,其余5(c)个没病,则查准率为75%。如果想要增加查准率,只要在判断时谨慎些,只将特别确认的患者判断为癌症患者,这就好比在统计分类模型中的增加阈值。
查全率(recall):R=a/(a+b),预测结果为1的样本数占真实标签为1的样本数的比例,还是癌症的例子,查全率是在所有真正的癌症患者中,被确诊的比例。假如有1000(a+b+c+d)个人就医,真正的患者有25(a+b)个,我们只确定其中15(a)个是癌症患者,其余10(b)个没有确诊,则查全率为60%。如果想要增加查全率,只需要将所有来就医的人确诊为癌症患者即可,这好比将阈值减小。
查准率和查全率是一组矛盾的评价标准,当查准率高时,查全率就低。查准率和查全率和阈值的选择有关,每选择一个阈值,则会有一对(查准率,查全率),将得到的多组数据绘制成图,便得到P-R曲线。
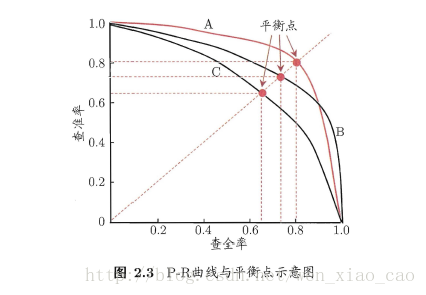
P-R曲线直挂的反映出查准率和查全率的关系,在实验中,如果模型A的P-R曲线将模型C的P-R曲线完全包住,我们则认为模型A对数据集的泛化能力较好。如图,如果是模型A和模型B的话,则不好比较。这时引入F1度量。
F1: F1=2∗P∗RP+R 或 1F1=12(1P+1R)
F1是P和R的调和平均.
在一些应用中,对查准率和查全率的重视程度有所不同.例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要.
-Fβ:Fβ=((1+β2)∗P∗Rβ2∗P+R 或 1Fβ=11+β2(1P+β2R)
其中β>0度量了查全率对查准率的相对重要性。β=1是,退化为标准形式F1;β<1,查准率有更大的影响;β>1,查全率有更大的影响。
即标签为1的查全率
FPR(false positive rate):FPR=c/(c+d)=1-d/(c+d)=1-TNR(ture negative rate)
即对标签为0的样本的错误度量,也是1-标签为0的查全率。
P-R曲线将查全率作为横坐标。查准率作为纵坐标,而ROC将FPR(1-标签为0的查全率)作为横坐标,将TPR(标签为1的查全率)作为纵坐标,根据不同的阈值,绘制曲线。
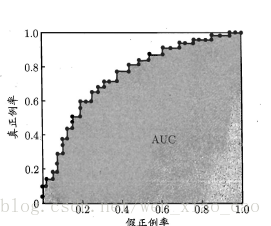
随着阈值减小,更多的样本被预测为1,TPR增大,TNR减小,所以FPR增大。和P-R曲线一样,如果一个模型的ROC曲线将另一个完全包围,则这个模型对于数据来说更好。但是当两个曲线相交是,需要用另一个标准来衡量。
AUC:AUC 是ROC曲线下的面积。面积越大说明模型越好。
周志华《机器学习》
http://blog.csdn.net/xw_classmate/article/details/51334373
1、混淆矩阵
混淆矩阵如图所示| correct/your answer | 1 | 0 | total |
|---|---|---|---|
| 1 | TP(True Positive,真阳性)-a | FN(False Negative,假阴性)-b | a+b |
| 0 | FP(False Positive,假阳性)-c | TN(True Negative,真阴性)-d | c+d |
| total | a+c | b+d | a+b+c+d |
预测结果可分为两类,正确(T)和不正确(F),其中正确又分为TP和TN,不正确分为FP和FN
TP:真阳性,实际情况为1,分类结果也为1,分类正确,且均为阳性
TN:真阴性,真实情况为0,预测结果为0,分类正确,且均为阴性
FP:真实情况为0,预测结果为1,分类错误,是假的阳性
FN:真实情况为1,分类结果为0,分类错误,是假的阴性
a+b:真实数据标签为1的个数
c+d:真实数据中标签为0的个数
a+c:预测结果中标签为1的个数
b+d:预测聚过中标签为0的个数
a+b+c+d:总共样本的个数
2、评价标准
2.1 精度(accuracy)
精度:acc=(a+d)/(a+b+c+d),分类正确的样本数占总体样本数的比例。2.2 查准率(precision)、查全率(recall)和F1
最经常使用的评价标准是精度(accuracy),但是当样本的1,0分布不均匀时,比如有100个样本,90个0,10个1,我们只需将所有的样本都判断为0,精确度为90%,但是这并不是一个好的分类器。所以对于分布不均与的样本,还需要其他的评价标准。此时,将样本数量较少的标签设为1,一般只关心这一类的准确率。例如在癌症预测是,将患癌症设为1。
查准率(precision):P=a/(a+c),预测结果为1的样本数占总共预测结果为1的比例,如癌症的例子,查准率是被确诊为癌症的患者中,真正的患者得比例。假如有1000(a+b+c+d)个人就医,我们判断其中20(a+c)个有癌症,这20个患者中真正患癌症的有15(a)个,其余5(c)个没病,则查准率为75%。如果想要增加查准率,只要在判断时谨慎些,只将特别确认的患者判断为癌症患者,这就好比在统计分类模型中的增加阈值。
查全率(recall):R=a/(a+b),预测结果为1的样本数占真实标签为1的样本数的比例,还是癌症的例子,查全率是在所有真正的癌症患者中,被确诊的比例。假如有1000(a+b+c+d)个人就医,真正的患者有25(a+b)个,我们只确定其中15(a)个是癌症患者,其余10(b)个没有确诊,则查全率为60%。如果想要增加查全率,只需要将所有来就医的人确诊为癌症患者即可,这好比将阈值减小。
查准率和查全率是一组矛盾的评价标准,当查准率高时,查全率就低。查准率和查全率和阈值的选择有关,每选择一个阈值,则会有一对(查准率,查全率),将得到的多组数据绘制成图,便得到P-R曲线。
P-R曲线直挂的反映出查准率和查全率的关系,在实验中,如果模型A的P-R曲线将模型C的P-R曲线完全包住,我们则认为模型A对数据集的泛化能力较好。如图,如果是模型A和模型B的话,则不好比较。这时引入F1度量。
F1: F1=2∗P∗RP+R 或 1F1=12(1P+1R)
F1是P和R的调和平均.
在一些应用中,对查准率和查全率的重视程度有所不同.例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要.
-Fβ:Fβ=((1+β2)∗P∗Rβ2∗P+R 或 1Fβ=11+β2(1P+β2R)
其中β>0度量了查全率对查准率的相对重要性。β=1是,退化为标准形式F1;β<1,查准率有更大的影响;β>1,查全率有更大的影响。
2.3 ROC和AUC
TPR(true positive rate):TPR=a/(a+b)=R即标签为1的查全率
FPR(false positive rate):FPR=c/(c+d)=1-d/(c+d)=1-TNR(ture negative rate)
即对标签为0的样本的错误度量,也是1-标签为0的查全率。
P-R曲线将查全率作为横坐标。查准率作为纵坐标,而ROC将FPR(1-标签为0的查全率)作为横坐标,将TPR(标签为1的查全率)作为纵坐标,根据不同的阈值,绘制曲线。
随着阈值减小,更多的样本被预测为1,TPR增大,TNR减小,所以FPR增大。和P-R曲线一样,如果一个模型的ROC曲线将另一个完全包围,则这个模型对于数据来说更好。但是当两个曲线相交是,需要用另一个标准来衡量。
AUC:AUC 是ROC曲线下的面积。面积越大说明模型越好。
3 总结
从以上的评价标准可以看出,acc只能度量总体分类的正确率,当正例1和负例0的分布不均匀,或者遇到特定的情况,比如癌症的确诊、信用卡诈骗等正例和负例有明显要求时,需要求查全率和查准率,甚至对查全率和查准率的重视不一样时,需要更多的评价标准。这些评价标准都可以根据混淆矩阵得出,所以混淆矩阵是基础。4 下一步用实例验证
参考资料
https://en.wikipedia.org/wiki/Receiver_operating_characteristic周志华《机器学习》
http://blog.csdn.net/xw_classmate/article/details/51334373

相关文章推荐
- 机器学习实战笔记(Python实现)-07-模型评估与分类性能度量
- 机器学习之分类模型的性能度量
- 机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
- 机器学习二分类问题模型效果度量方法
- 【机器学习】分类性能度量指标 : ROC曲线、AUC值、正确率、召回率、敏感度、特异度
- 机器学习模型性能度量
- 机器学习 —— 性能度量和比较检验、模型评估方法
- 机器学习模型性能度量
- 分类模型的性能评估——以SAS Logistic回归为例(2): ROC和AUC
- 机器学习实验(十二):深度学习之图像分类模型AlexNet结构分析和tensorflow实现
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
- 机器学习实战第七章 - 利用AdaBoost元算法提高分类性能
- 机器学习——线性模型之回归与分类
- 类间样本数量不平衡对分类模型性能的影响问题
- 机器学习实践之集成方法(随机森林和AdaBoost元算法提高分类性能)
- 分类模型的效果度量---R语言实现
- 机器学习 - 模型性能改善
- 性能度量(模型评价)
- 机器学习性能改善备忘单:32个帮你做出更好预测模型的技巧和窍门
- 机器学习实战笔记-利用AdaBoost元算法提高分类性能